Clear Sky Science · fr
Détection automatisée des photorécepteurs en cônes à l’aide de données synthétiques et d’apprentissage profond dans des images AOSLO confocales avec optique adaptative
Des vues plus nettes de l’œil vivant
Voir les cellules photoréceptrices de l’œil une par une pourrait transformer la façon dont les médecins détectent et suivent les maladies responsables de cécité. Aujourd’hui toutefois, les spécialistes doivent repérer ces cellules à la main dans des images fortement agrandies de la rétine, un processus lent, subjectif et difficile à déployer à l’échelle de milliers de patients. Cette étude montre comment des modèles informatiques entraînés sur des images « faux » d’œil réalistes peuvent apprendre à localiser automatiquement ces cellules, ouvrant la voie à des examens oculaires plus rapides, plus fiables et à une meilleure évaluation des nouveaux traitements.
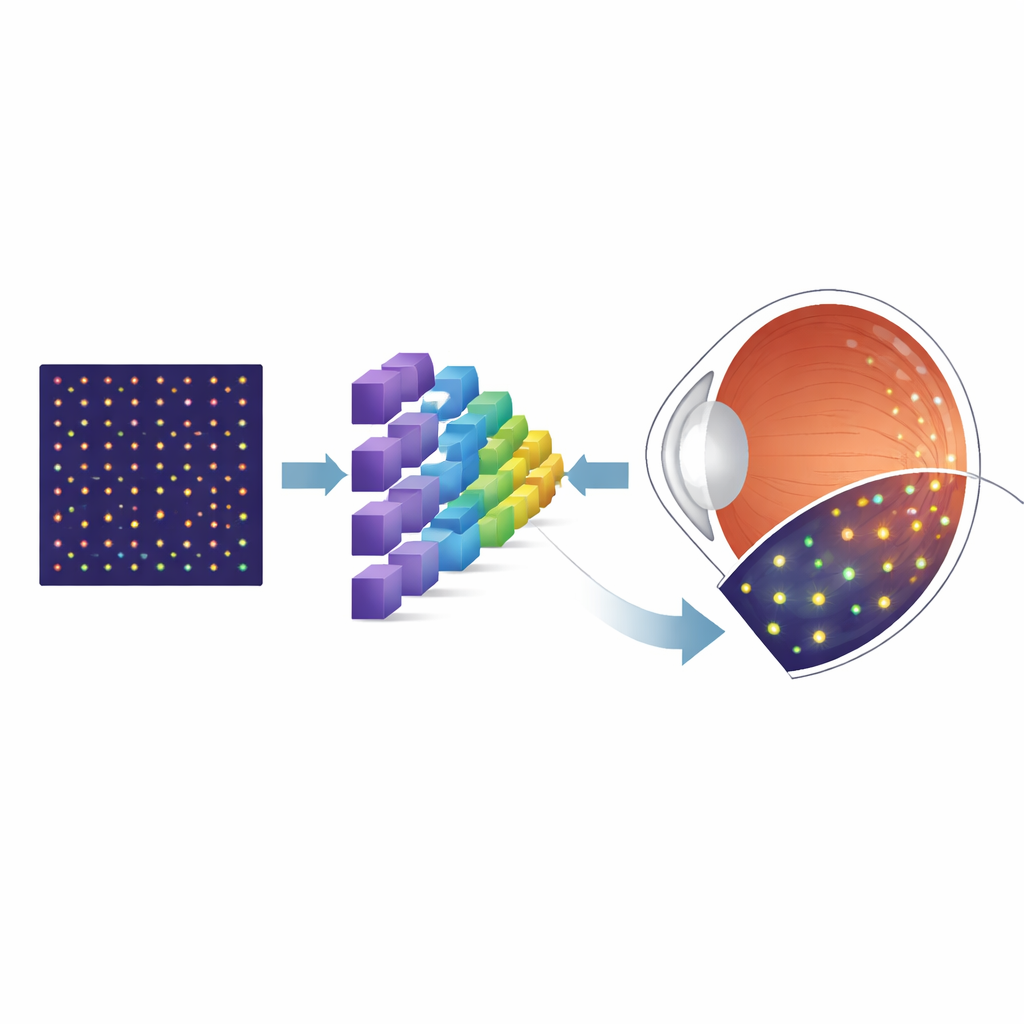
Pourquoi ces petites cellules comptent
À l’arrière de l’œil se trouvent des photorécepteurs — des cellules spécialisées qui transforment la lumière en signaux que notre cerveau interprète comme la vision. Les photorécepteurs en cônes, en particulier, sont essentiels pour la vision centrale nette et la perception des couleurs, et leur perte est une caractéristique de nombreuses maladies rétiniennes. Une technologie d’imagerie puissante appelée ophalmoscopie laser à balayage avec optique adaptative (AOSLO) peut capturer des images détaillées de ces cellules chez des personnes vivantes. Cependant, avant que médecins et chercheurs puissent mesurer la densité de cônes ou suivre les changements au fil du temps, il faut d’abord repérer chaque cône dans l’image. Le marquage manuel prend non seulement beaucoup de temps, mais varie aussi d’un opérateur à l’autre, limitant son utilité en clinique courante et dans les essais de grande envergure.
Des règles artisanales à l’apprentissage depuis les données
Des programmes informatiques antérieurs ont tenté d’automatiser la détection des cônes en appliquant des règles fixes : par exemple, rechercher des points lumineux d’une certaine taille ou espacement. Ces méthodes basées sur des règles pouvaient bien fonctionner sur des images propres provenant d’yeux sains, mais elles rencontraient souvent des difficultés lorsque les images étaient bruitées, légèrement floues ou issues de patients malades. L’apprentissage profond propose une stratégie différente. Plutôt que de concevoir des règles manuellement, un réseau neuronal apprend les motifs directement à partir d’exemples. Le problème est que ces modèles nécessitent généralement un grand nombre d’images déjà étiquetées par des experts — précisément le type de données rare et coûteux en imagerie AOSLO.
Construire un terrain d’entraînement virtuel
Pour contourner la pénurie d’images réelles annotées, les chercheurs ont utilisé un outil de simulation appelé ERICA, capable de générer des images réalistes de type AOSLO montrant des mosaïques de cônes, avec une connaissance « ground truth » parfaite de la position de chaque cône. Ils ont créé de vastes jeux d’images synthétiques couvrant de nombreuses positions rétiniennes, en faisant varier de façon systématique les principales imperfections affectant les images réelles, comme le bruit aléatoire et le flou optique subtil. Ils ont ensuite entraîné une architecture de réseau neuronal spécialisée, connue sous le nom d’U-Net, pour transformer chaque image d’entrée en une carte de probabilités indiquant où les cônes sont les plus susceptibles d’être. Après cet entraînement initial sur des données synthétiques, l’équipe a affiné le modèle en utilisant une collection beaucoup plus petite d’images AOSLO réelles issues d’un jeu de données public bien connu, puis l’a testé sur des images indépendantes provenant d’un autre laboratoire pour évaluer sa capacité de généralisation.

Que vaut la méthode par rapport aux experts humains ?
L’équipe a comparé sa méthode automatisée au marquage manuel fastidieux et à deux algorithmes de détection de cônes performants. En utilisant une mesure standard d’emboîtement entre les marquages prédits et manuels des cônes, le nouvel U-Net égalait ou approchait la performance des évaluations expertes et des méthodes automatisées concurrentes sur le jeu de données public. De manière cruciale, lorsqu’il a été testé sur un ensemble séparé d’images prises à différentes distances du centre de la vision et acquises avec un instrument différent, le modèle a tout de même très bien performé. Cela suggère qu’un entraînement intensif sur des données synthétiques couvrant une large gamme de conditions visuelles a aidé le réseau à apprendre des caractéristiques transférables aux images réelles, plutôt qu’à surajuster un appareil ou un groupe de patients spécifique.
Ce que cela pourrait signifier pour les soins oculaires futurs
Pour les non-spécialistes, le message clé est qu’un programme informatique entraîné en grande partie sur des images « virtuelles » d’œil peut désormais trouver des cônes réels dans des scans rétiniens à haute résolution à peu près aussi fidèlement que des experts humains. En rendant la détection des cônes plus rapide, plus objective et plus facile à appliquer sur différents scanners et dans différentes cliniques, cette approche pourrait aider à faire de l’imagerie rétinienne détaillée un outil de routine pour le suivi des maladies au niveau des cellules individuelles. À plus long terme, des méthodes similaires basées sur des données synthétiques pourraient être étendues pour détecter d’autres types cellulaires et modéliser la perte cellulaire liée aux maladies, soutenant un diagnostic plus précoce, un suivi plus précis de la progression et une évaluation plus fine des nouveaux traitements visant à préserver la vision.
Citation: Shah, M., Young, L.K., Downes, S.M. et al. Automated cone photoreceptor detection using synthetic data and deep learning in confocal adaptive optics scanning laser ophthalmoscope images. Sci Rep 16, 8313 (2026). https://doi.org/10.1038/s41598-026-39570-9
Mots-clés: imagerie rétinienne, photorécepteurs en cônes, apprentissage profond, données synthétiques, optique adaptative