Clear Sky Science · fr
Un modèle vision-langage médical 3D économe en données n’utilisant qu’un encodeur 2D
Aide plus intelligente à partir des scans 3D
Lorsque les médecins lisent des scanners CT ou des IRM, ils ne se contentent pas d’examiner des images isolées : ils reconstituent mentalement des centaines de coupes pour comprendre un problème en trois dimensions. Enseigner aux ordinateurs à faire de même pourrait accélérer les diagnostics, améliorer la cohérence et produire des comptes rendus plus clairs pour les patients. Mais les systèmes d’intelligence artificielle actuels capables de traiter des volumes 3D sont extrêmement « gourmands » en données, nécessitant d’immenses jeux d’annotations que beaucoup d’hôpitaux n’ont pas. Cet article présente une méthode pour obtenir une compréhension de niveau 3D à partir de technologies d’image 2D existantes, promettant des outils puissants plus simples et moins coûteux à construire et à déployer.
Pourquoi les scans 3D sont difficiles pour l’IA
Les systèmes modernes « vision–langage » savent déjà analyser une image médicale 2D et répondre à des questions ou rédiger un rapport en langage courant. Étendre cette capacité aux volumes 3D permettrait à l’IA de raisonner sur des organes entiers et des lésions subtiles qui ne deviennent claires qu’en examinant de nombreuses coupes. Le problème est que la plupart des systèmes 3D actuels s’appuient sur des encodeurs 3D spécifiques entraînés depuis zéro sur d’énormes collections de scans annotés. De tels jeux de données sont rares, coûteux à annoter et souvent concentrés dans des centres bien financés, ce qui limite qui peut en bénéficier. Parallèlement, traiter chaque coupe comme une simple image 2D individuelle fait perdre la continuité naturelle entre les coupes et noie le modèle sous des informations répétitives.
Recycler un expert 2D pour le travail 3D
Les auteurs proposent une voie différente : au lieu d’entraîner un nouvel encodeur 3D, ils réutilisent un puissant modèle d’images médicales 2D déjà entraîné sur des millions d’images annotées de la littérature médicale. Ils découpent d’abord chaque volume 3D en ses coupes individuelles et laissent ce modèle 2D extraire des caractéristiques détaillées de chaque coupe. Ensuite, ils éliminent soigneusement la redondance : comme les coupes voisines se ressemblent souvent beaucoup, une vérification de similarité peut écarter de nombreux quasi‑doublons tout en conservant les vues les plus informatives. Cette étape réduit à elle seule la quantité de données que les étapes suivantes doivent traiter, sans exiger davantage de scans annotés.
Reconstruire l’histoire 3D à partir des morceaux
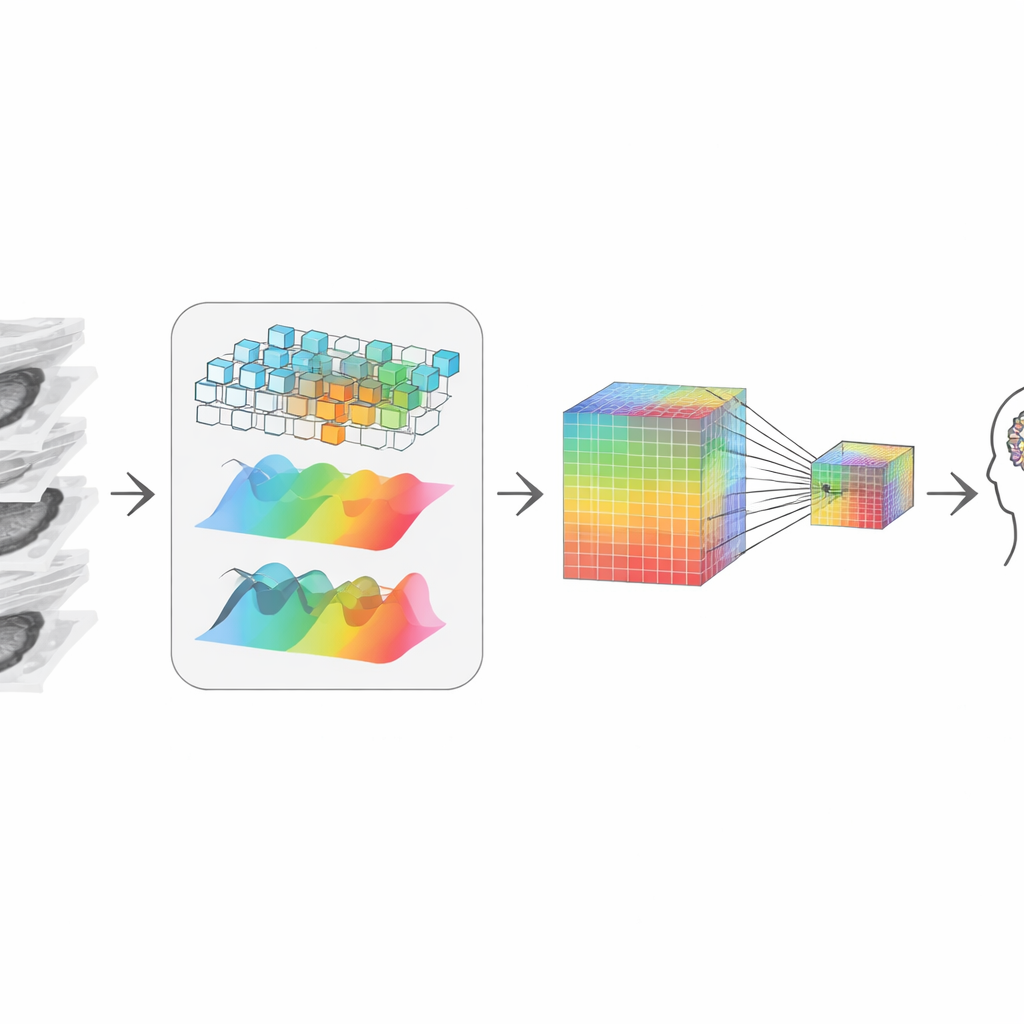
Après l’élagage, le système doit « recoudre » les coupes restantes en une image 3D cohérente. Les auteurs le font en combinant deux vues complémentaires des données. Une voie se concentre sur les formes et les contours locaux, comme une loupe parcourant le volume, sensible aux frontières nettes et aux textures. L’autre transforme les données en vue fréquentielle, mieux adaptée pour capter des motifs larges et la structure à longue portée entre les coupes — comment une tumeur s’étend ou comment un organe est globalement façonné. Une étape de fusion adaptative apprend à quel point faire confiance à chaque vue en chaque point, produisant une représentation qui respecte à la fois le détail fin et le contexte global, même si elle part de coupes 2D.
Conserver les indices minimes tout en compressant
Pour dialoguer avec un grand modèle de langage — la partie qui répond aux questions et rédige les rapports —, l’information visuelle doit être compressée en un nombre modéré de jetons, ou « mots visuels ». Une simple réduction risquerait d’estomper des signaux petits mais cruciaux, comme de petites calcifications ou des changements subtils de texture importants pour le diagnostic. Pour l’éviter, les auteurs créent une représentation à deux pistes : l’une conserve une version haute résolution riche en détails, l’autre est plus petite et bon marché. Un mécanisme d’attention permet à chaque point de la version réduite de « regarder » sélectivement la version large et d’y puiser les détails les plus nets disponibles. Le résultat est un résumé visuel compact qui conserve néanmoins les indices pertinents pour un radiologue, puis est transmis au modèle de langage pour raisonnement.
Preuve sur des tâches médicales réelles
Pour tester leur conception, les chercheurs l’ont évaluée sur des benchmarks 3D publics qui posent deux questions principales : le système peut‑il rédiger des descriptions de type radiologique précises de volumes 3D, et peut‑il répondre à des questions sur ce qui est visible dans ces volumes ? Leur approche, malgré l’absence d’un encodeur 3D entraîné spécifiquement, a surpassé plusieurs modèles 3D compétitifs sur les deux tâches. Elle a produit des rapports plus précis et cliniquement riches et répondu plus correctement aux questions, y compris les plus difficiles concernant l’organe exact, l’anomalie ou la localisation impliqués. Elle a aussi tourné plus vite, requis beaucoup moins de données d’entraînement 3D et généralisé efficacement à différents types de scans comme l’IRM et le PET.
Ce que cela signifie pour les soins futurs
Concrètement, ce travail montre qu’il n’est pas nécessaire de repartir de zéro avec des modèles 3D gourmands en données pour obtenir une aide de haute qualité de l’IA sur les scans volumétriques. En recyclant intelligemment un expert 2D performant, en sélectionnant soigneusement les coupes informatives et en reconstruisant l’image 3D tout en préservant les détails minimes, les auteurs atteignent des performances de pointe avec beaucoup moins de données et de calcul. Si cette approche était largement adoptée, elle pourrait rendre l’assistance IA avancée — meilleurs comptes rendus, explications plus claires et triage plus fiable — accessible aux hôpitaux et cliniques qui n’ont pas de vastes ressources de données, rapprochant l’analyse d’imagerie sophistiquée de la pratique clinique courante.
Citation: Lian, Y., Xie, Y., Jiang, Y. et al. A data-efficient 3D medical vision-language model using only a 2D encoder. Sci Rep 16, 8809 (2026). https://doi.org/10.1038/s41598-026-39526-z
Mots-clés: imagerie médicale 3D, modèles vision-langage, IA en radiologie, apprentissage économe en données, analyse CT et IRM