Clear Sky Science · fr
Intégrer l’apprentissage profond à la modélisation basée sur la physique permet une prédiction très précise de l’interface anticorps‑antigène
Pourquoi cela compte pour les médicaments de demain
Les anticorps sont les missiles guidés de notre système immunitaire et de nombreux médicaments modernes. Pour concevoir de meilleurs anticorps, les scientifiques doivent savoir exactement comment un anticorps saisit sa molécule cible, ou antigène. Mesurer ces structures expérimentalement est lent et coûteux. Cette étude montre comment la combinaison de l’apprentissage profond et de la modélisation classique de type physique peut améliorer sensiblement les prédictions informatiques de la zone de contact entre anticorps et antigène, accélérant potentiellement la conception et le criblage d’anticorps.
Trouver la zone de la poignée
Les anticorps reconnaissent leurs cibles grâce à de petites boucles flexibles à leurs extrémités, appelées régions de liaison, qui se combinent pour former une zone de contact. Ces boucles peuvent se plier et se tordre, et la zone correspondante sur l’antigène est souvent étendue et peu profonde plutôt que constituée d’une poche profonde. Cette flexibilité et cette subtilité rendent le problème du dockage — déterminer comment les deux formes s’emboîtent — extrêmement difficile pour les ordinateurs. Les programmes de dockage traditionnels testent de nombreuses positions relatives des deux protéines et les évaluent à l’aide de règles physiques telles que l’attraction électrostatique et le déplacement d’eau, mais sans indices biologiques ils aboutissent souvent à des appariements incorrects.
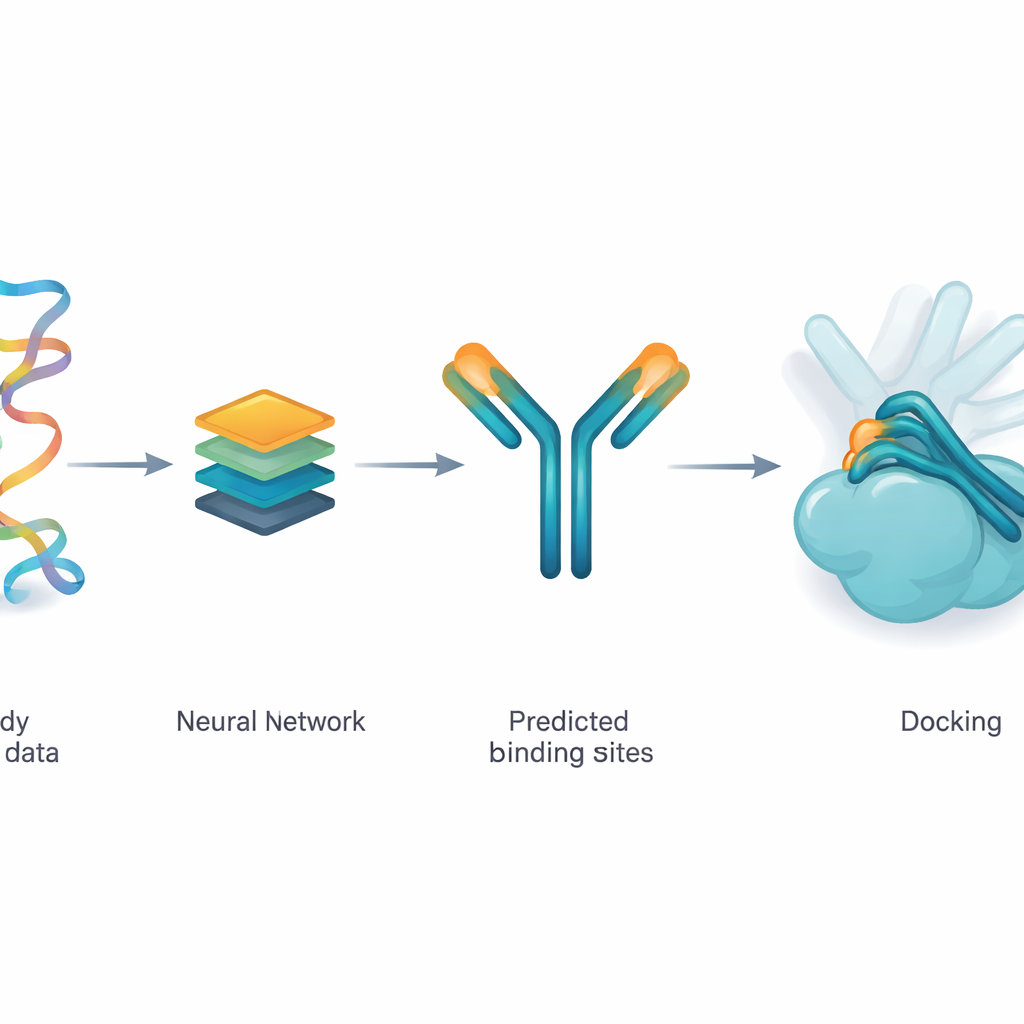
Apprendre à un réseau à suggérer les points de contact probables
Les auteurs utilisent un modèle d’apprentissage profond nommé ParaDeep pour deviner quels acides aminés d’un anticorps sont les plus susceptibles de toucher l’antigène. ParaDeep fonctionne uniquement à partir de la séquence de l’anticorps — l’ordre de ses éléments constitutifs — sans nécessiter une structure 3D complète. Il lit ensemble les séquences des chaînes lourde et légère, encode leurs caractéristiques chimiques et positionnelles, et utilise des mécanismes d’attention pour mettre en évidence les résidus qui semblent de bons candidats à la liaison. Chaque position reçoit un score de probabilité ; celles au‑dessus d’un seuil sont traitées comme une zone de contact prédite qui peut être repositionnée sur la structure de l’anticorps.
Guider un moteur physique plutôt que le remplacer
Plutôt que d’utiliser l’apprentissage profond pour générer intégralement des complexes anticorps–antigène à partir de rien, l’équipe injecte les résidus de contact prédits par ParaDeep dans un moteur de dockage basé sur la physique existant, PyDockWEB. Ce programme de dockage échantillonne des milliers de façons possibles dont l’anticorps et l’antigène pourraient se rencontrer et les évalue avec une fonction d’énergie. Dans ce nouveau cadre, les résidus de contact prédits servent de contraintes souples : elles orientent la recherche de sorte que de nombreuses orientations échantillonnées rapprochent ces résidus de la surface de l’antigène. De façon importante, l’évaluation physique sous‑jacente et le traitement en corps rigide des protéines restent inchangés, rendant le processus transparent et relativement léger à exécuter.
Dans quelle mesure les prédictions s’améliorent‑t‑elles ?
Les chercheurs ont testé leur approche hybride sur 50 complexes anticorps–antigène connus issus d’une base de données soignée. Pour chaque cas, ils ont comparé le dockage « à l’aveugle » standard au dockage guidé par les contraintes de ParaDeep. Ils ont mesuré la précision locale de l’interface (à quel point la région de contact prédite correspond à la réalité), la similarité globale de forme et un score de qualité combiné largement utilisé pour évaluer les modèles de dockage. Sur cet ensemble, la méthode guidée a fortement réduit les erreurs au site de liaison, rapproché les structures globales des complexes réels et déplacé de nombreuses prédictions de catégories clairement erronées vers des catégories de qualité moyenne ou élevée. Près de la moitié des modèles guidés se sont retrouvés dans la catégorie de haute qualité, contre environ un quart pour le dockage à l’aveugle.
Pourquoi certains appariements sont plus faciles que d’autres
L’équipe a également examiné pourquoi certains complexes ont bénéficié davantage que d’autres. Ils ont constaté que prédire un plus grand nombre de résidus de contact ne garantissait pas le succès ; ce qui importait était de placer les contraintes au bon endroit, pas leur quantité. Les interfaces plus hydrophiles et contenant davantage de segments en hélice lâche (coil) avaient tendance à mieux se doker, probablement parce qu’elles s’accordent bien avec l’accent mis par PyDockWEB sur l’électrostatique et sont plus faciles à aligner sans changements importants de forme. Lorsque les chercheurs ont répété certains cas échoués en utilisant des informations de contact « oracle » extraites directement des structures expérimentales, la plupart de ces cas se sont améliorés, confirmant que la localisation précise de la zone de contact est un ingrédient clé — mais le dockage en corps rigide atteint toujours ses limites lorsque de grands ajustements de forme sont nécessaires.
Ce que cela signifie pour la suite
Concrètement, ce travail montre que donner à un programme de dockage basé sur la physique un indice intelligent sur l’endroit où un anticorps est susceptible d’attraper sa cible peut considérablement améliorer sa visée, sans transformer le processus en une boîte noire opaque. Le pipeline combiné ParaDeep–PyDockWEB ne remplace pas les méthodes flexibles ou génératives plus avancées, mais offre un moyen pratique d’utiliser des signaux d’apprentissage profond au niveau séquence pour guider des outils de dockage familiers et interprétables. À mesure que les efforts de découverte et d’ingénierie d’anticorps génèrent des bibliothèques de séquences toujours plus vastes, de telles approches hybrides pourraient aider les chercheurs à filtrer rapidement des candidats structurellement compatibles avec une cible donnée, rendant le chemin de la séquence à l’anticorps exploitable plus rapide et mieux informé.
Citation: Kodchakorn, K., Udomwong, P., Pamonsupornwichit, T. et al. Integrating deep learning with physics based modeling enables high precision antibody antigen interface prediction. Sci Rep 16, 8134 (2026). https://doi.org/10.1038/s41598-026-39466-8
Mots-clés: dockage d’anticorps, apprentissage profond, prédiction du paratope, interactions protéine‑protéine, conception d’anticorps