Clear Sky Science · fr
CGDFNet : un réseau de segmentation sémantique temps réel à double branche avec fusion des détails guidée par le contexte
Apprendre aux voitures à voir toute la rue
Les voitures et les robots modernes reposent de plus en plus sur des caméras pour comprendre le monde qui les entoure — repérant en temps réel routes, trottoirs, personnes, véhicules et panneaux. Cet article présente CGDFNet, un nouveau système de vision par ordinateur conçu pour accomplir ce type de « compréhension de scène » plus rapidement et avec plus de précision, en particulier dans les rues urbaines encombrées. En apprenant à conserver à la fois les détails fins (comme les poteaux de feux ou les roues de vélo) et la structure d’ensemble (comme les routes et les bâtiments), CGDFNet vise à rendre la conduite automatisée et autres tâches de vision en temps réel plus sûres et plus fiables.
Pourquoi la vision au niveau des pixels est si exigeante
En segmentation sémantique, un ordinateur attribue une catégorie à chaque pixel d’une image : route, voiture, piéton, ciel, etc. C’est bien plus exigeant que de simplement tracer une boîte autour d’une voiture, car le système doit suivre les contours d’objets et les petites formes avec une grande précision. De nombreuses méthodes très précises existent, mais elles ont tendance à être lentes et gourmandes en énergie, ce qui les rend peu adaptées aux systèmes temps réel embarqués dans les voitures, drones ou dispositifs portables. À l’inverse, les méthodes légères et rapides sacrifient souvent les détails ou perdent la vue d’ensemble, peinant avec les petits objets, les structures fines ou les environnements urbains denses.
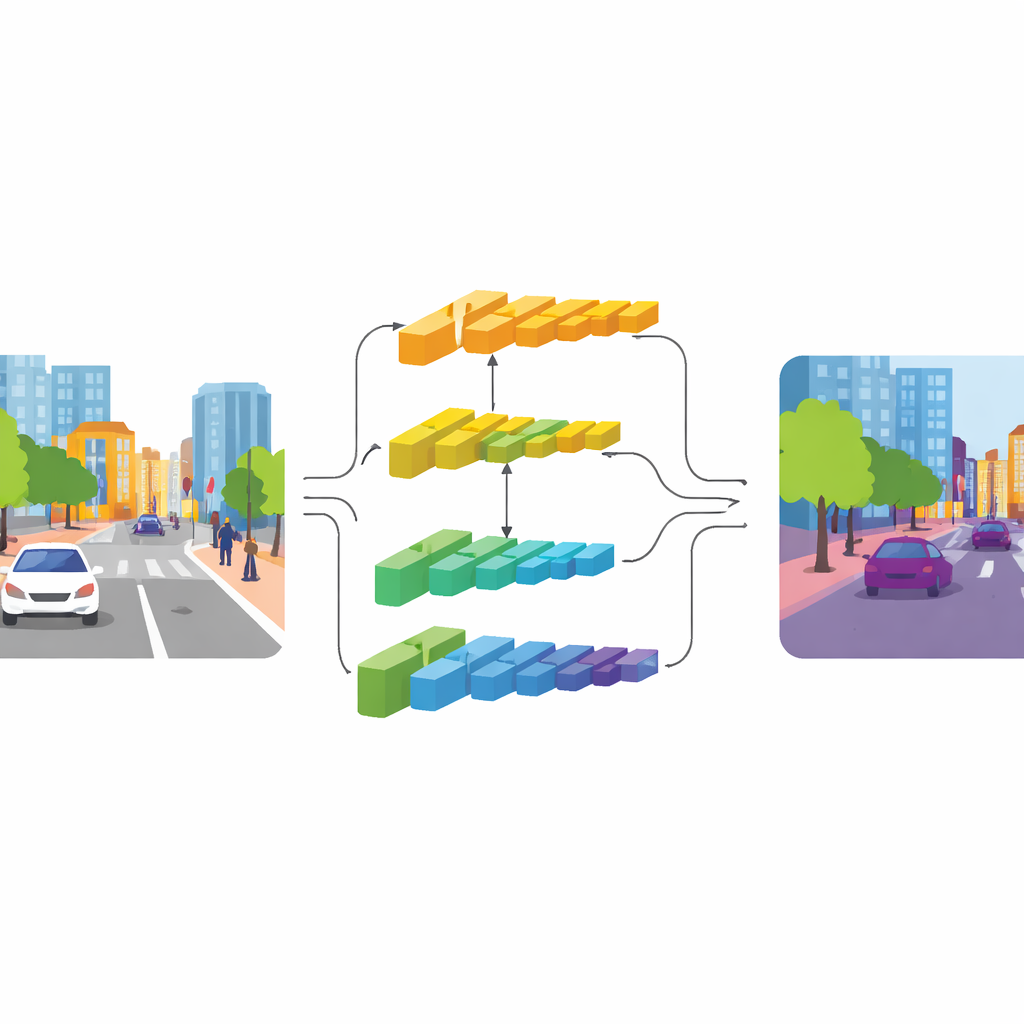
Deux voies : l’une pour le détail, l’autre pour le contexte
CGDFNet aborde cette tension par une architecture à double branche : une branche se concentre sur les détails nets, l’autre capture le contexte global. S’appuyant sur une architecture de base efficace, les couches basses alimentent une « branche détail » qui conserve une résolution plus élevée pour préserver les arêtes et textures. Les couches profondes alimentent une « branche contexte » qui observe la scène sous une forme plus compressée, adaptée à la compréhension de la structure générale et des relations entre objets. Contrairement aux conceptions antérieures à deux branches qui restent largement séparées puis les additionnent grossièrement, CGDFNet les encourage à communiquer tout au long du traitement, de sorte que les détails fins sont continuellement confrontés à ce que le réseau sait de la scène globale.
Guider les détails par le sens
Deux composants clés renforcent cette interaction. Dans la branche contexte, un Module de Raffinement Sémantique apprend à mettre en évidence les régions et canaux les plus informatifs de ses cartes de caractéristiques. Il combine des indices locaux (quelles parties de la scène sont actives à proximité les unes des autres) et des indices globaux (ce que le réseau perçoit sur l’ensemble de l’image), de sorte que la représentation porte à la fois le détail du voisinage et le sens au niveau de la scène. Dans la branche détail, un Module de Détail Guidé par le Contexte utilise cette information sémantique pour diriger l’attention vers les arêtes et structures fines importantes, telles que le contour d’un bus ou le cadre d’un vélo. Il s’appuie sur un type particulier de convolution plus sensible aux variations entre pixels voisins, ce qui met naturellement l’accent sur les contours et les petits objets sans ajouter beaucoup de paramètres supplémentaires.
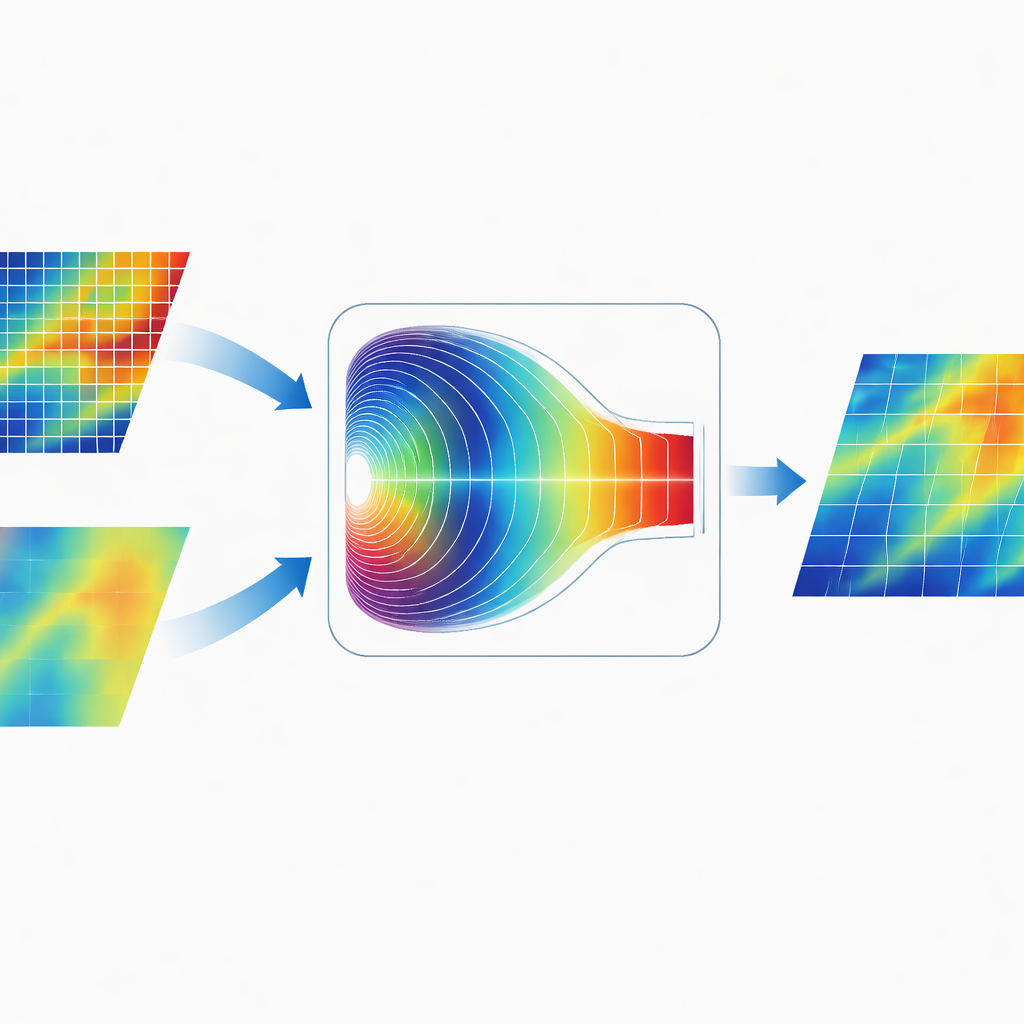
Fusionner l’information dans le domaine fréquentiel
Une caractéristique distinctive de CGDFNet est la manière dont il fusionne les deux branches. Plutôt que de simplement additionner leurs cartes dans l’espace image, les auteurs conçoivent un Module de Fusion Adaptative dans le Domaine de Fourier. Ce module transforme temporairement les caractéristiques combinées dans le domaine fréquentiel, où les motifs sont représentés en termes de variations lentes et larges et de changements rapides et nets. Un mécanisme de gating adaptatif apprend alors quelles composantes fréquentielles mettre en avant pour la branche détail et lesquelles favoriser pour la branche contexte. Après ce pondération, les caractéristiques sont retransformées, produisant une représentation qui unit plus efficacement arêtes nettes et structure globale cohérente qu’une fusion traditionnelle uniquement spatiale.
Résultats dans des rues réelles
L’équipe a testé CGDFNet sur deux benchmarks largement utilisés pour les scènes de conduite urbaine : Cityscapes, collecté dans des villes européennes, et CamVid, acquis du point de vue du conducteur au Royaume-Uni. CGDFNet a traité de grandes images à des vitesses temps réel — environ 88 images par seconde sur Cityscapes et environ 129 images par seconde sur CamVid — tout en atteignant une précision de segmentation qui rivalise avec, voire dépasse, de nombreux systèmes à la pointe. Il a particulièrement bien performé sur des catégories généralement difficiles à segmenter, telles que les barrières, panneaux de signalisation, bus et bicyclettes, où la préservation de contours précis et de petites structures est cruciale.
Ce que cela implique pour la technologie du quotidien
Concrètement, CGDFNet montre qu’il est possible de concevoir des systèmes de vision à la fois assez rapides pour un usage temps réel et suffisamment soignés pour respecter des détails petits et critiques pour la sécurité dans des scènes urbaines complexes. En combinant une branche axée sur le détail, une branche axée sur le contexte et une étape de fusion intelligente dans le domaine fréquentiel, le réseau conserve une vue équilibrée de la rue : il sait où se trouve chaque chose et où commence et finit chaque objet. Si des défis subsistent — comme les foules denses ou les intempéries — l’approche offre un plan prometteur pour la vision embarquée future, des voitures autonomes aux caméras de trafic intelligentes et aux robots d’assistance.
Citation: Zhao, S., Fu, W., Gao, J. et al. CGDFNet: a dual-branch real-time semantic segmentation network with context-guided detail fusion. Sci Rep 16, 9191 (2026). https://doi.org/10.1038/s41598-026-39370-1
Mots-clés: segmentation sémantique temps réel, vision pour conduite autonome, réseau neuronal à double branche, fusion de caractéristiques basée sur Fourier, compréhension de scènes urbaines