Clear Sky Science · fr
Prédiction masquée de la topologie du mouvement squelettique et apprentissage contrastif pour la reconnaissance d'actions humaines en apprentissage auto-supervisé
Apprendre aux ordinateurs à lire le langage corporel
Des sonnettes vidéo aux outils de rééducation intelligents, de nombreux systèmes modernes doivent comprendre ce que font les personnes simplement en observant leurs mouvements. Mais entraîner des ordinateurs à reconnaître des actions humaines exige habituellement d'énormes jeux de données soigneusement étiquetés, où chaque vague de la main, coup de pied ou poignée de main est annoté manuellement. Cette étude présente une méthode pour apprendre à partir de données de mouvement brutes, en n'utilisant que le squelette en mouvement du corps — sans étiquettes, sans visages et sans vidéo couleur complète — ce qui rend la reconnaissance d'actions plus précise, plus respectueuse de la vie privée et beaucoup moins dépendante d'annotations humaines coûteuses.
Pourquoi le squelette suffit
Plutôt que d'analyser des images vidéo complètes, la méthode travaille avec des données squelettiques 3D : les coordonnées des articulations clés comme les épaules, coudes, hanches et genoux au fil du temps. Cette vue dépouillée du corps présente plusieurs avantages. Elle évite en grande partie les problèmes de confidentialité puisque les visages et les vêtements sont éliminés, et elle est suffisamment compacte pour être traitée efficacement, même pour de longues séquences. Les squelettes sont aussi robustes face aux arrière-plans encombrés et aux variations d'éclairage qui peuvent perturber les systèmes vidéo classiques. Cependant, la plupart des approches existantes basées sur le squelette reposent encore fortement sur des exemples étiquetés et peinent à capturer pleinement la manière dont les articulations se déplacent ensemble dans des actions complexes et coordonnées.
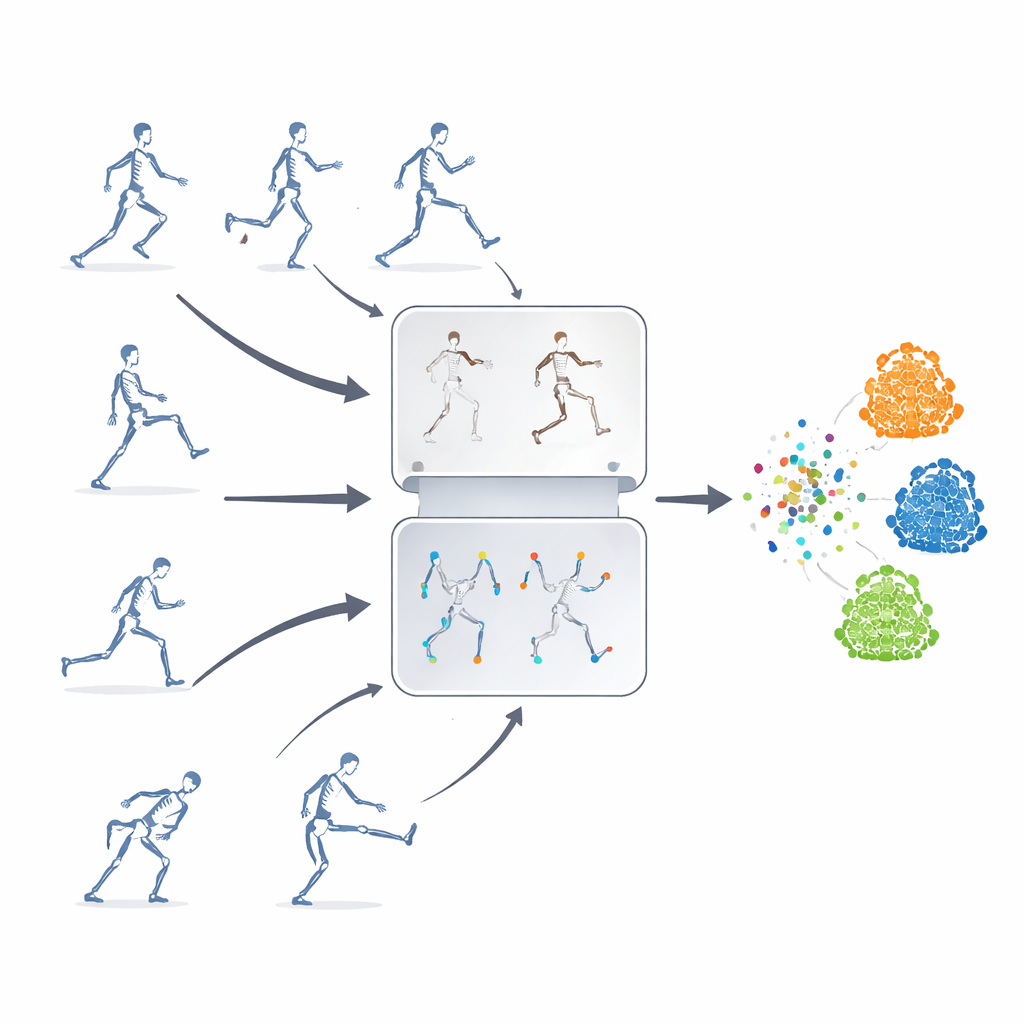
Apprendre sans étiquettes
Les auteurs proposent un cadre d'apprentissage auto-supervisé, c'est-à-dire que le système s'enseigne à lui-même à partir de séquences squelettiques non étiquetées. Leur idée clé est de combiner deux stratégies puissantes habituellement utilisées séparément. La première est la « prédiction masquée », où des parties des données squelettiques sont volontairement cachées afin que le modèle doive deviner le mouvement manquant à partir du contexte restant. La seconde est l'« apprentissage contrastif », qui présente au modèle plusieurs versions altérées d'une même action et l'entraîne à reconnaître que ces variations représentent toujours un même mouvement sous-jacent. En mêlant ces approches, le système apprend à la fois les détails fins du mouvement des articulations et le sens global d'une action.
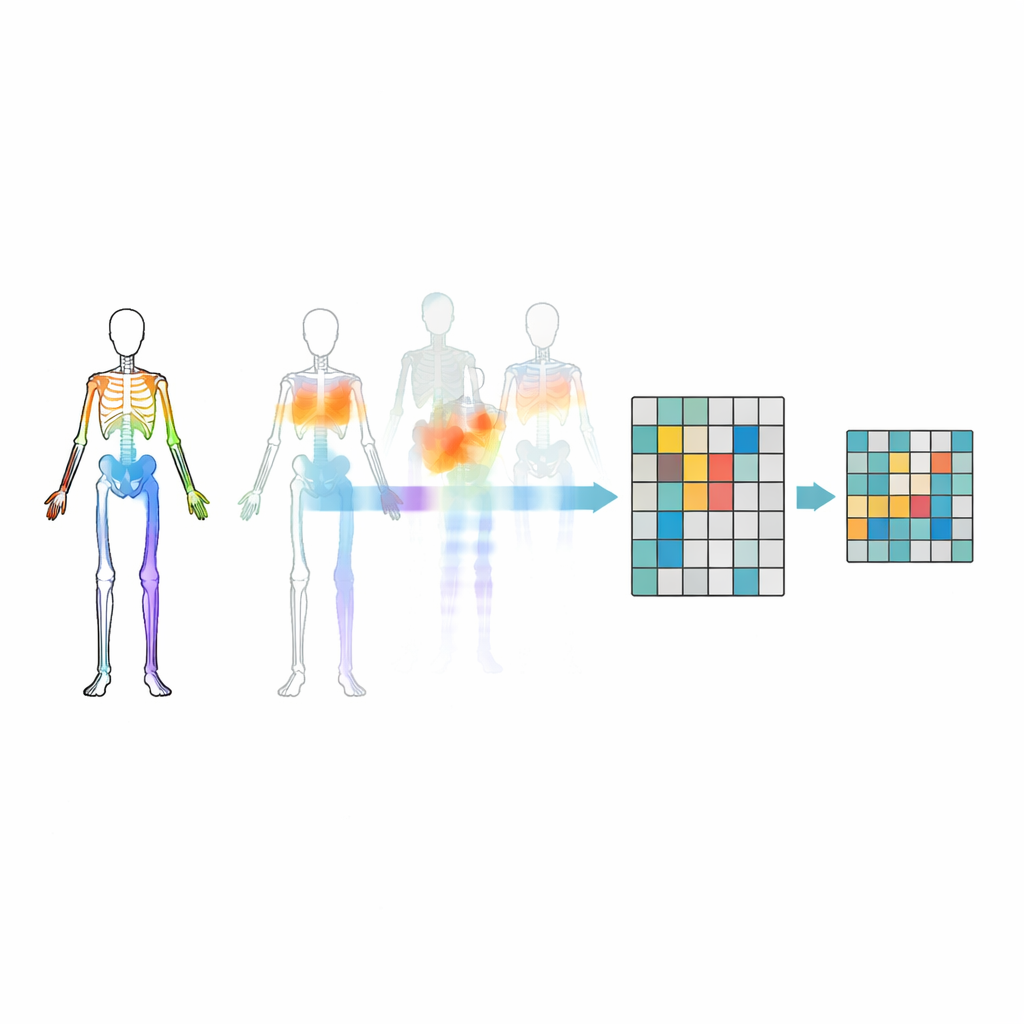
Masquer les bonnes articulations
Masquer simplement des articulations au hasard ne suffit pas — le modèle pourrait ignorer des relations importantes entre les parties du corps ou se focaliser sur le mouvement le plus évident. Pour éviter cela, les chercheurs introduisent une stratégie de masquage basée sur la topologie et le mouvement. Ils regroupent les articulations en régions corporelles signifiantes telles que les bras, les jambes et le tronc, puis mesurent l'intensité du mouvement de chaque région au fil du temps. Les décisions de masquage sont guidées à la fois par la structure du corps et par l'activité de chaque région, de sorte que certaines parties très actives sont parfois cachées et que le modèle est contraint de les inférer à partir du reste du corps. Ce masquage ciblé aide le système à apprendre comment les articulations coopèrent pendant les actions, plutôt que de simplement mémoriser quelques mouvements voyants.
Déformer les actions de multiples façons
Pour entraîner la composante contrastive du système, une même séquence squelettique d'origine est transformée en de nombreuses « vues ». Certaines modifications sont douces, comme le recadrage temporel ou une légère déformation de la trajectoire, tandis que d'autres sont plus extrêmes, incluant des retournements, des rotations et un bruit plus important. Ces niveaux multiples d'augmentations exposent le modèle à une grande variété de motifs de mouvement, l'encourageant à se concentrer sur la structure fondamentale d'une action plutôt que sur des détails superficiels. Parallèlement, un module d'ablation de caractéristiques guidé par la trajectoire suit les caractéristiques de mouvement sur lesquelles le modèle s'appuie le plus et les supplante intentionnellement pendant l'entraînement. En supprimant temporairement ses indices favoris, le système est poussé à découvrir des indices de secours et à apprendre des représentations plus générales et transférables.
Quelle est l'efficacité réelle ?
Le cadre est évalué sur trois grandes bases de référence publiques d'actions humaines 3D, couvrant des comportements du quotidien, des mouvements liés au domaine médical et des interactions entre personnes. Bien qu'il n'utilise que des données d'articulations squelettiques et un réseau de neurones récurrent relativement léger, la méthode égalise ou dépasse de nombreux systèmes à la pointe qui reposent sur des entrées ou des architectures plus complexes. Elle est particulièrement performante lorsque les annotations sont rares ou lorsque certaines parties du corps sont occultées, des conditions fréquentes en milieu réel. Si sa capacité à transférer les connaissances entre des jeux de données très différents laisse encore une marge d'amélioration, l'approche réduit significativement l'écart entre l'entraînement étiqueté et non étiqueté pour la reconnaissance d'actions.
Conséquences pour les systèmes du monde réel
Pour un non-spécialiste, la conclusion est que ce travail montre comment les ordinateurs peuvent devenir bien meilleurs pour lire le langage corporel humain sans qu'on leur indique explicitement la signification de chaque mouvement. En masquant et en déformant intelligemment les données squelettiques pendant l'entraînement, le modèle apprend des motifs de mouvement robustes qui tiennent sous de mauvaises conditions d'éclairage, des scènes encombrées ou des articulations manquantes, et ce avec beaucoup moins d'étiquettes fournies par des humains. Cela ouvre la voie à des systèmes de reconnaissance d'actions plus privés, évolutifs et adaptables, pour des applications allant de la surveillance domestique et du coaching sportif à la rééducation médicale et à l'interaction homme–robot.
Citation: Hui, Y., Li, F., Hu, X. et al. Skeleton motion topology-masked prediction and contrastive learning for self-supervised human action recognition. Sci Rep 16, 8100 (2026). https://doi.org/10.1038/s41598-026-39330-9
Mots-clés: reconnaissance d'actions humaines, données squelettiques 3D, apprentissage auto-supervisé, apprentissage contrastif, analyse du mouvement