Clear Sky Science · fr
Utiliser un grand modèle de langage pour améliorer le raisonnement d’un autre grand modèle de langage via GRPO mis à jour par récompense
Apprendre aux machines à réfléchir en profondeur
Beaucoup des modèles de langage actuels savent converser, traduire et répondre à des questions, mais ils peinent encore à montrer leur démarche comme le ferait un bon élève en mathématiques ou un analyste rigoureux. Cet article examine comment un système d’intelligence artificielle peut être utilisé pour améliorer les capacités de raisonnement d’un autre, et comment le faire sans construire manuellement d’énormes jeux de données spécialisés. Pour les lecteurs intéressés par la fiabilité accrue de l’IA dans des domaines tels que la finance, la médecine ou la recherche scientifique, ce travail propose une recette pratique pour amener les modèles à expliquer leurs réponses de façon plus claire et plus cohérente.
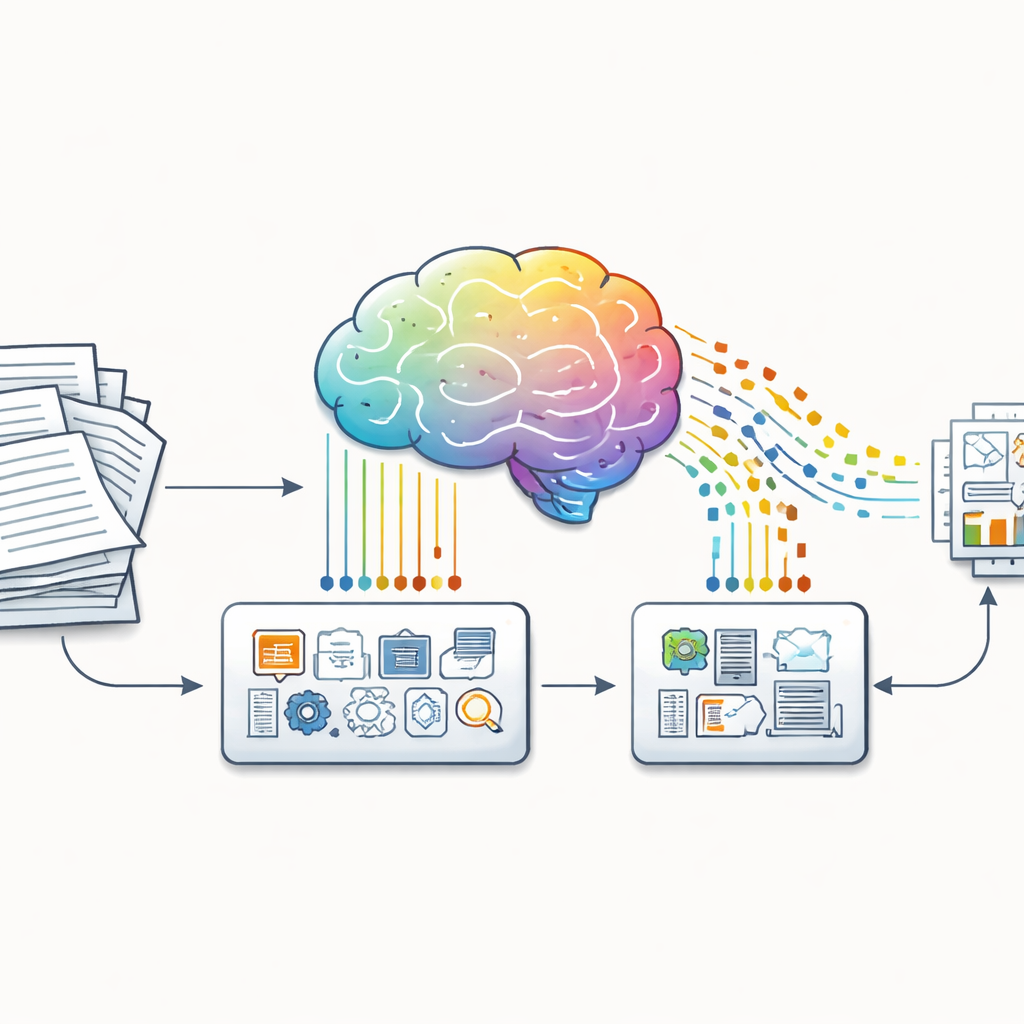
Des documents bruts aux exemples enseignables
Les auteurs partent d’une observation simple : la plupart des informations du monde réel se trouvent sous des formes désordonnées — rapports, lettres aux actionnaires ou pages web — et non sous forme propre de questions-réponses. Pour combler cet écart, ils présentent deux outils logiciels, Huggify-Data et le générateur de données CoT. Ces outils prennent du texte non structuré et le transforment automatiquement en paires question-réponse, puis demandent à un modèle de langage puissant de fournir les étapes de raisonnement manquantes entre les deux. Le résultat est un triplet structuré pour chaque exemple : une question, une chaîne de raisonnement et une réponse. Fait crucial, ce pipeline peut s’appliquer à presque n’importe quel domaine, des mathématiques scolaires à la finance d’entreprise, rendant possible la constitution de données d’entraînement axées sur le raisonnement sans armées d’annotateurs humains.
Comment un modèle en entraîne un autre
Une fois ces triplets question–raisonnement–réponse créés, ils servent à entraîner un modèle « étudiant » plus petit à penser de la même manière structurée. On demande à l’étudiant non seulement de donner une réponse finale, mais de produire une explication clairement séparée suivie de la conclusion. L’entraînement est guidé par une méthode appelée Group Relative Policy Optimization, qui compare plusieurs réponses candidates à la même question et oriente le modèle vers les meilleures. L’article enrichit cette méthode d’un terme de récompense supplémentaire qui vérifie si la sortie du modèle suit le format souhaité, jusqu’à quel point elle correspond à un exemple de référence bien formé. Cette récompense pénalise légèrement les explications confuses ou incomplètes, poussant le modèle vers des réponses nettes et interprétables.
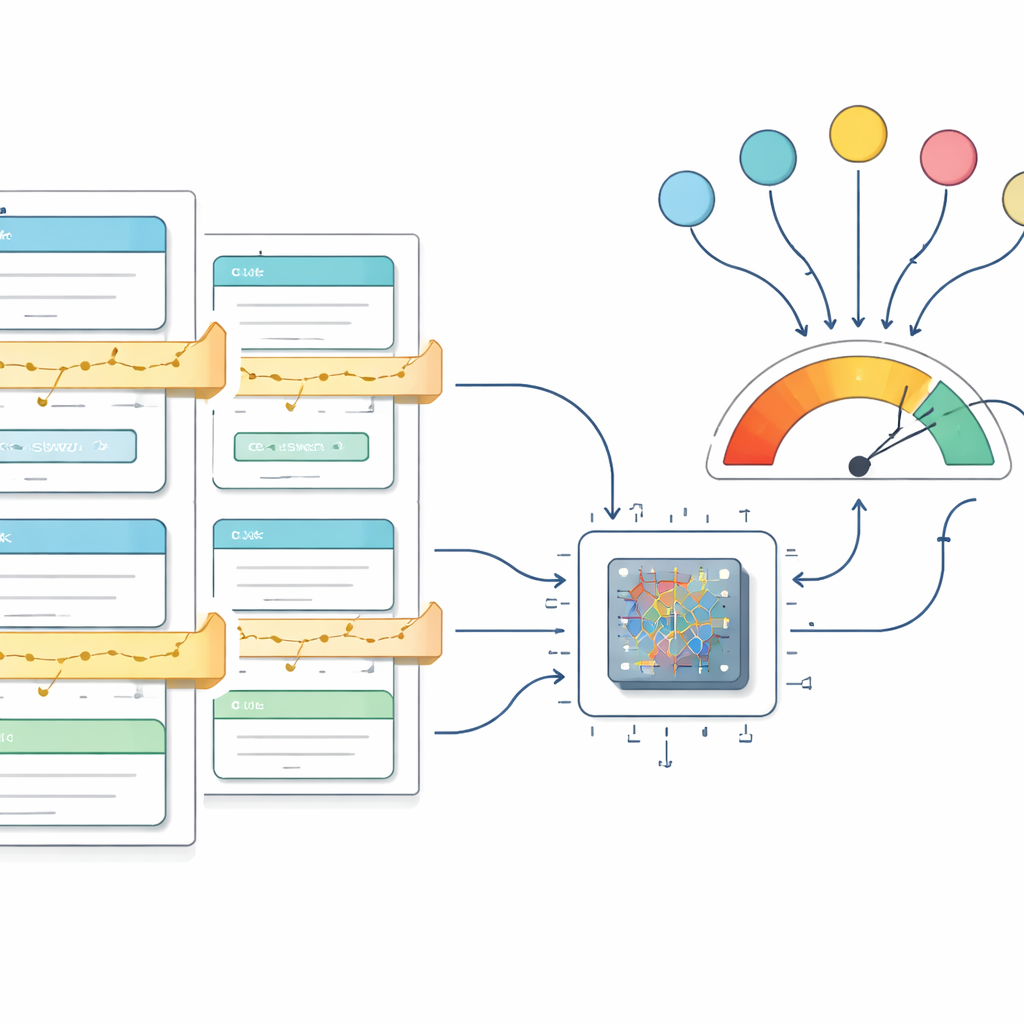
Mettre l’approche à l’épreuve
Pour vérifier si le cadre fonctionne en pratique, les auteurs l’appliquent à deux jeux de données très différents. Le premier, GSM8K, contient des problèmes arithmétiques de niveau scolaire qui requièrent un raisonnement en plusieurs étapes. Le second est construit à partir des lettres annuelles de Warren Buffett aux actionnaires, où l’objectif est de capturer un raisonnement long et argumenté sur l’investissement et les décisions d’entreprise. Dans les deux cas, le pipeline transforme le texte brut en données d’entraînement structurées et affine un modèle de taille moyenne appelé Qwen 2.5. Pendant l’entraînement, une règle de notation simple récompense les réponses correctes et bien formatées ; à mesure que l’apprentissage progresse, la récompense moyenne augmente régulièrement puis se stabilise à son maximum théorique, montrant que le modèle a en grande partie maîtrisé le comportement ciblé sur les données d’entraînement.
Quelle est la performance du modèle amélioré
La performance est mesurée par la « précision moyenne par token », qui évalue, à grands traits, quelle fraction des petits éléments de texte (tokens) dans les sorties du modèle correspondent à ceux attendus. Bien que cela diffère du scoring classique tout-ou-rien des réponses de test, cette mesure convient pour juger si les explications et les réponses sont produites dans la bonne structure. Sur GSM8K, le meilleur modèle atteint 98,2 % de précision par token, et sur les lettres de Buffett il atteint 98,5 %. Ces scores dépassent ceux rapportés pour des systèmes largement connus comme GPT‑4 et Claude 3.5 Sonnet selon le même indicateur, tout en n’utilisant qu’un modèle de 3 milliards de paramètres pouvant être entraîné en moins de deux jours sur du matériel loué. Les auteurs partagent également des détails sur les coûts informatiques et les configurations matérielles, et publient tout le code, les modèles et les jeux de données pour que d’autres puissent les inspecter et les exploiter.
Ce que cela signifie pour l’usage quotidien de l’IA
Pour les non-spécialistes, la conclusion principale est que les systèmes d’IA peuvent être enseignés non seulement à répondre, mais à répondre de manière disciplinée et facile à suivre, en utilisant des données extraites automatiquement de documents ordinaires. En combinant un modèle enseignant riche en raisonnement, un pipeline de données flexible et un schéma de récompense qui valorise à la fois la justesse et la clarté, les auteurs montrent comment sculpter des modèles plus petits en résolveurs de problèmes plus fiables. Bien qu’ils notent des limites — comme la nécessité de tests plus robustes de compréhension réelle et de sûreté — le cadre ouvre la voie à un avenir où les organisations pourront transformer leurs archives textuelles en assistants d’IA sur mesure et transparents pour l’éducation, la finance et au-delà.
Citation: Yin, Y. Use large language model to enhance reasoning of another large language model through reward updated GRPO. Sci Rep 16, 8360 (2026). https://doi.org/10.1038/s41598-026-39296-8
Mots-clés: grands modèles de langage, raisonnement par chaîne de pensée, optimisation par récompense, curation de données, IA spécialisée par domaine