Clear Sky Science · fr
Un cadre Siamese CNN-RNN avec agrégation multi-niveaux pour la ré-identification de personnes basée sur la vidéo
Pourquoi suivre des personnes entre caméras est important
Les villes modernes sont couvertes de caméras, mais ces caméras « ne se parlent » que rarement. Lorsqu’une personne se déplace d’un coin de rue à une gare, différentes caméras la voient sous de nouveaux angles, avec des éclairages variés et souvent au milieu d’une foule. Reconnaître automatiquement qu’il s’agit de la même personne à travers plusieurs séquences vidéo — appelé ré-identification de personnes basée sur la vidéo — peut aider les enquêteurs à retracer des déplacements après un incident, soutenir les recherches de personnes disparues ou alimenter des analyses dans des espaces publics fréquentés. Réaliser cela de façon précise et efficiente, en particulier sur du matériel modeste, reste un défi technique majeur.
Un cerveau plus simple pour apparier des personnes en mouvement
Cette étude présente un système d’intelligence artificielle compact conçu pour déterminer si deux courtes séquences vidéo montrent la même personne. Plutôt que d’utiliser la tendance actuelle des réseaux très profonds ou basés sur les transformers, les auteurs s’appuient sur une conception plus légère combinant deux ingrédients classiques : un réseau convolutionnel qui analyse chaque image de la vidéo, et une unité récurrente à portes (GRU) qui suit l’évolution de l’apparence dans le temps. Ces deux branches sont arrangées selon une architecture siamoise — essentiellement des copies jumelles du même réseau partageant tous leurs paramètres internes. Chaque jumeau traite une séquence vidéo, et le système apprend à produire des signatures internes similaires pour des clips de la même personne et clairement distinctes pour différentes personnes.
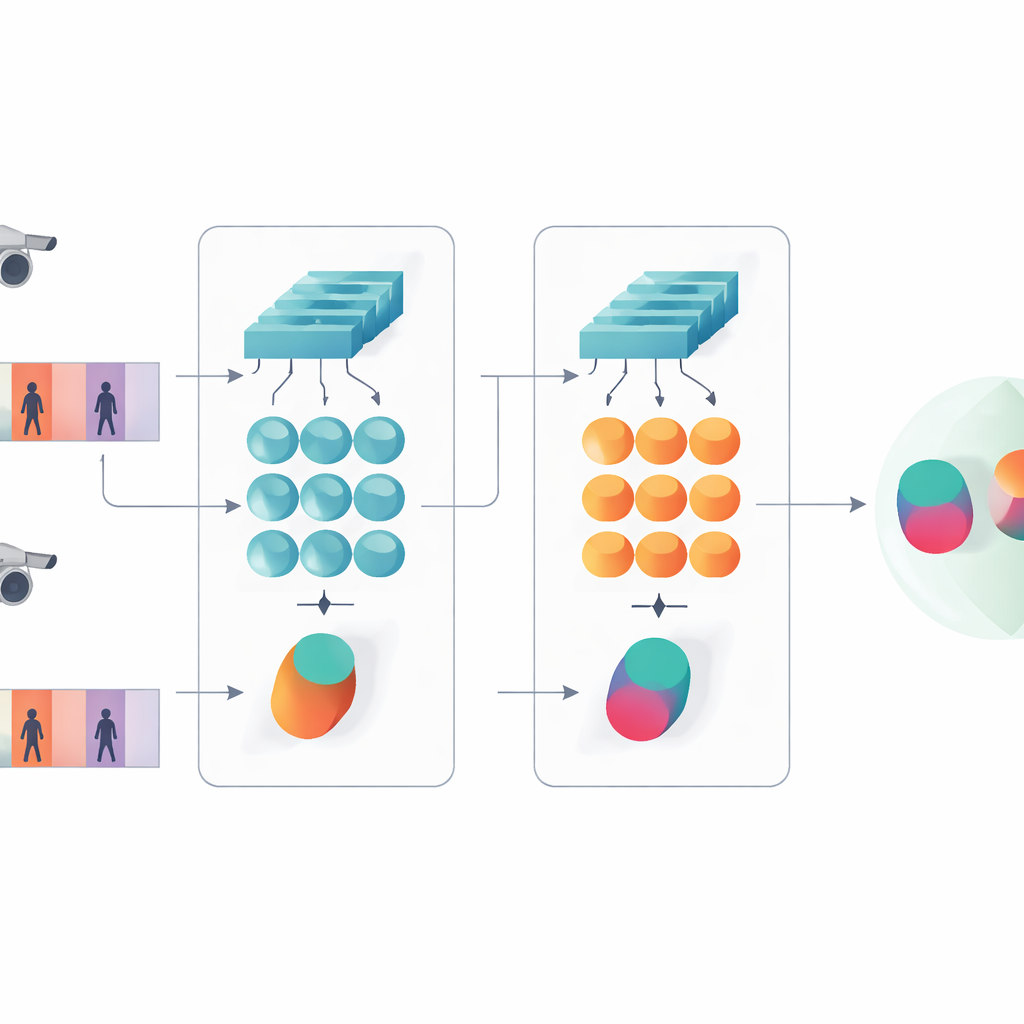
Voir à la fois les détails et les motifs temporels
Une idée clé de ce travail est que la reconnaissance ne doit pas reposer uniquement sur les caractéristiques les plus profondes et abstraites d’un réseau. Les couches antérieures contiennent encore des détails visuels nets comme le tissage d’une veste, des rayures sur un pantalon ou le contour d’un sac à dos — des indices qui survivent souvent aux changements d’angle de caméra. Le modèle proposé conserve donc deux niveaux de description. Une branche agrège par pooling les caractéristiques des couches peu profondes sur toutes les images pour résumer les textures fines et les motifs locaux. L’autre branche envoie des caractéristiques plus profondes dans la GRU, qui suit la séquence image par image puis moyenne ses états internes sur le temps. Cette étape de moyennage évite de surpondérer les dernières images et capture plutôt une vue consensuelle de l’apparence et des mouvements de la personne sur l’ensemble du clip.
Entraîner les réseaux jumeaux à s’accorder et à classer
Pour enseigner au système ce qui compte, les auteurs combinent deux objectifs d’apprentissage. D’une part, une fonction de vérification encourage les branches jumelles à produire des signatures proches pour des vidéos de la même personne et éloignées pour des personnes différentes. D’autre part, un objectif de classification demande au réseau d’assigner chaque clip d’entraînement à une identité spécifique. En optimisant les deux simultanément, et ce à la fois aux niveaux de caractéristiques bas et haut, le modèle apprend des descriptions internes qui sont non seulement distinctes entre individus mais aussi robustes au bruit, à l’occultation et aux images de mauvaise qualité occasionnelles. La conception reste peu profonde en nombre de couches et de paramètres, ce qui l’aide à éviter le surapprentissage sur des jeux de données vidéo relativement petits.
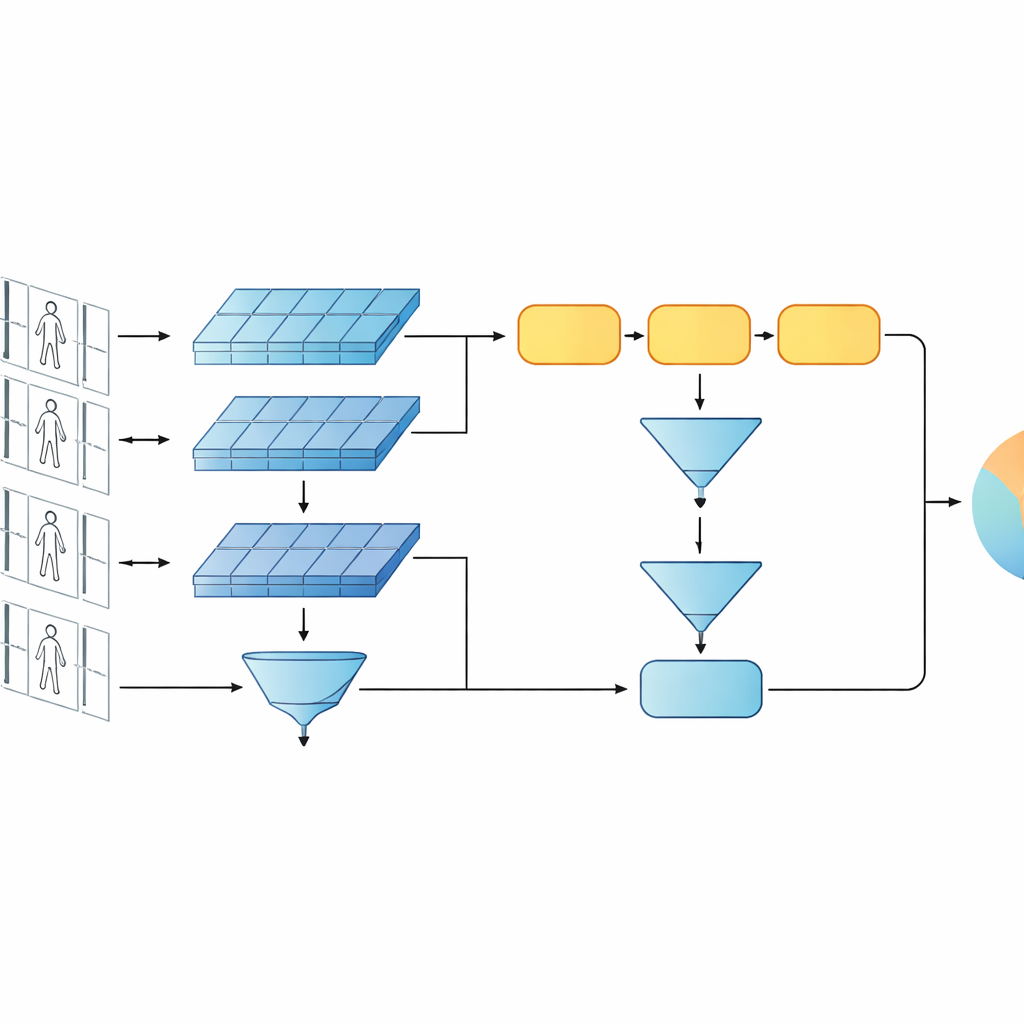
Tests sur des vidéos de type surveillance réelles
Le cadre est évalué sur deux benchmarks vidéo largement utilisés, PRID-2011 et iLIDS-VID, qui contiennent de courtes séquences de marche de centaines d’individus capturées par des paires de caméras disjointes. L’étude explore soigneusement différents choix de conception : remplacer la GRU par d’autres unités récurrentes, modifier le nombre de couches récurrentes, changer la façon dont les caractéristiques sont poolées dans le temps, et activer ou désactiver les branches de bas ou haut niveau. À travers ces tests, une GRU à couche unique avec pooling moyen et la configuration multi-niveaux complète fournit systématiquement la meilleure précision. Le modèle égalise ou dépasse de nombreux systèmes récurrents et siamois plus complexes, et est compétitif avec certains designs basés sur l’attention, tout en utilisant beaucoup moins de paramètres et de calcul.
Efficacité pour des déploiements concrets
Au-delà de la précision, le travail met l’accent sur la praticité. L’ensemble du réseau ne compte qu’environ un à deux millions de paramètres entraînables — des ordres de grandeur de moins que les backbones résiduels profonds ou basés sur des transformers populaires — et requiert une fraction de leur coût de calcul par image. Cela le rend plus adapté au déploiement sur des dispositifs à mémoire et puissance de calcul limitées, tels que des serveurs edge proches des caméras. Les expériences montrent également que des séquences de galerie plus longues, où le système voit plus d’images de chaque personne stockée, améliorent substantiellement la reconnaissance, bien que cela augmente linéairement le coût de traitement. Les auteurs soutiennent que de telles architectures compactes et soigneusement conçues peuvent offrir une ré-identification fiable sans le lourd coût des plus grands modèles actuels.
Ce que cela signifie pour les systèmes de surveillance quotidiens
En termes simples, cet article démontre que la conception intelligente peut l’emporter sur la taille brute : en combinant une analyse d’image peu profonde, une modélisation de séquence légère et une vision à deux niveaux de la similarité visuelle, il est possible de suivre qui est qui à travers les caméras avec une grande fiabilité tout en gardant le modèle petit et rapide. Pour les systèmes futurs qui doivent fonctionner sur de nombreuses caméras, souvent avec des contraintes matérielles et énergétiques strictes, ce type d’approche multi-niveaux et efficace pourrait aider à déployer des analyses vidéo plus performantes et responsables dans des usages réels.
Citation: Wang, YK., Pan, TM. & Sun, CP. A CNN-RNN Siamese framework with multi-level aggregation for video-based person re-identification. Sci Rep 16, 8224 (2026). https://doi.org/10.1038/s41598-026-39277-x
Mots-clés: ré-identification de personnes, surveillance vidéo, réseaux neuronaux siamois, modélisation temporelle, apprentissage profond efficace