Clear Sky Science · fr
Une méthode d’ensemble hybride à empilement contrainte par la géologie utilisant des diagraphies pour la prédiction de la COT dans des réservoirs de schiste continentaux
Pourquoi cela compte pour l’exploration pétrolière future
Dénicher de nouveaux gisements dans des roches de schiste dépend de plus en plus d’une utilisation intelligente des données plutôt que du forage de puits toujours plus coûteux. Une mesure clé, le carbone organique total (COT), indique aux géologues où les schistes sont suffisamment riches en matière organique ancienne pour générer du pétrole. Mesurer directement la COT sur carottes est lent et onéreux, de sorte que la plupart des profondeurs dans la plupart des puits restent non échantillonnées. Cette étude montre comment un système d’intelligence artificielle soigneusement conçu, guidé par des connaissances géologiques, peut transformer des mesures de diagraphie de routine en estimations continues et fiables de la COT dans un grand bassin pétrolier de schiste chinois.
Lire les roches avec des yeux électroniques
Les puits modernes sont couramment enregistrés avec des outils qui mesurent des propriétés comme la radioactivité naturelle, le temps de propagation acoustique, la résistivité électrique, la densité et la réponse neutronique. Ces relevés forment des courbes continues le long du forage et coûtent bien moins cher que la collecte et l’analyse de carottes. Toutefois, le lien entre ces signaux de diagraphie et la richesse organique est complexe. Il dépend du type de roche, de la taille des grains, des fluides poreux et des modes de dépôt et d’altération des sédiments. Des formules empiriques antérieures, comme la méthode classique ΔlogR, fonctionnent raisonnablement dans des contextes simples mais peinent lorsque la géologie devient plus variée et stratifiée, comme dans des bassins lacustres continentaux tels que le bassin de Songliao dans le nord-est de la Chine.
Ajouter une perspective géologique à l’apprentissage automatique
Pour relever ce défi, les auteurs ont construit un modèle hybride d’ensemble « empilé » qui combine quatre moteurs de prédiction différents : arbres à gradient boosté, forêts aléatoires, une régression par vecteurs de support et un réseau neuronal récurrent amélioré. Plutôt que d’alimenter ces modèles uniquement avec des courbes brutes de diagraphie, ils ont conçu un jeu riche d’entrées encodant le contexte géologique. Les types de roche ont été traduits en une échelle numérique continue qui transitionne en douceur aux frontières de couches et reflète comment la COT tend à varier des schistes bitumineux aux schistes ordinaires, aux siltites et aux carbonates. Des intervalles réservoirs connus par la stratigraphie régionale ont été ajoutés comme indicateurs catégoriels, aidant le système à apprendre comment la relation diagraphie–COT change d’une zone de profondeur à l’autre.
Extraire des motifs subtils de diagraphies complexes
L’équipe a également conçu de nouvelles caractéristiques pour capturer des combinaisons subtiles de réponses de diagraphies qui signalent un schiste serré et riche en organique par opposition à des roches plus perméables et plus propres. Ils ont combiné plusieurs mesures de résistivité pour décrire la manière dont les fluides sont emprisonnés, et mixé les lectures gamma, de densité et neutroniques pour distinguer un fond riche en argile d’un véritable enrichissement organique. Un module convolutionnel spécialisé a été introduit pour gérer l’espacement irrégulier entre échantillons de carottes et mesures de diagraphie : il traite les courbes de diagraphie comme des signaux à valeurs complexes et extrait à la fois l’amplitude et la phase tout en tenant compte des pas de profondeur inégaux. Une analyse en composantes principales a ensuite distillé les nombreuses caractéristiques corrélées en un nombre réduit de composantes orthogonales résumant les propriétés clés des roches.
Optimiser les modèles et combler les lacunes de données
Parce que le nombre de mesures de COT issues de carottes est limité, les chercheurs ont utilisé une optimisation heuristique inspirée du comportement des bélugas pour sélectionner les sous-ensembles de caractéristiques les plus informatifs et ajuster de nombreux réglages des modèles de façon guidée par les données. Ils ont en outre appliqué une méthode d’augmentation de données axée sur la régression qui génère des valeurs synthétiques plausibles de COT à des profondeurs non étiquetées, contraintes pour rester cohérentes au sein d’un même puits et type de roche. Ces étapes ont produit des jeux d’entraînement plus équilibrés et réduit le surapprentissage. Enfin, les quatre modèles de base optimisés ont été empilés, leurs sorties étant combinées par un apprenant de niveau supérieur afin que les forces individuelles compensent les faiblesses des autres. 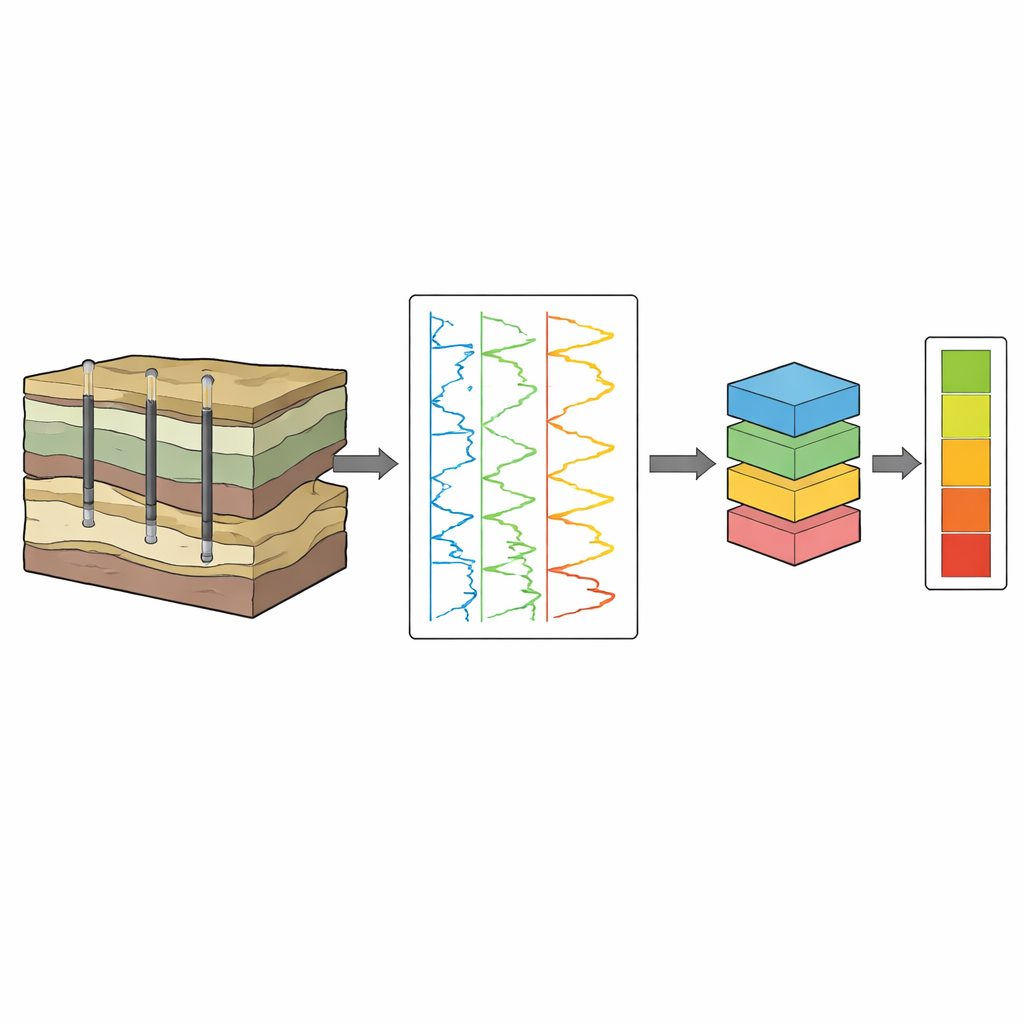
Quelle performance sur le terrain réel ?
L’approche a été testée sur sept puits de la Formation Qingshankou dans la partie nord du bassin de Songliao, en utilisant 2 374 échantillons de carotte comme vérité terrain. Au travers d’une série d’expériences contrôlées, chaque composant majeur — contraintes géologiques, caractéristiques de diagraphie conçues, convolution avancée, algorithmes d’optimisation, augmentation de données et empilement de modèles — a apporté des gains mesurables. L’ensemble final a atteint un fort degré d’ajustement à l’intérieur des puits et, plus important encore, a mieux généralisé que n’importe quel modèle isolé aux puits qu’il n’avait pas vus auparavant. Comparé aux formules traditionnelles et à des configurations d’apprentissage automatique plus simples, il a produit systématiquement des erreurs plus faibles et une performance plus stable lors de la prédiction de la COT à travers différents intervalles rocheux et puits. 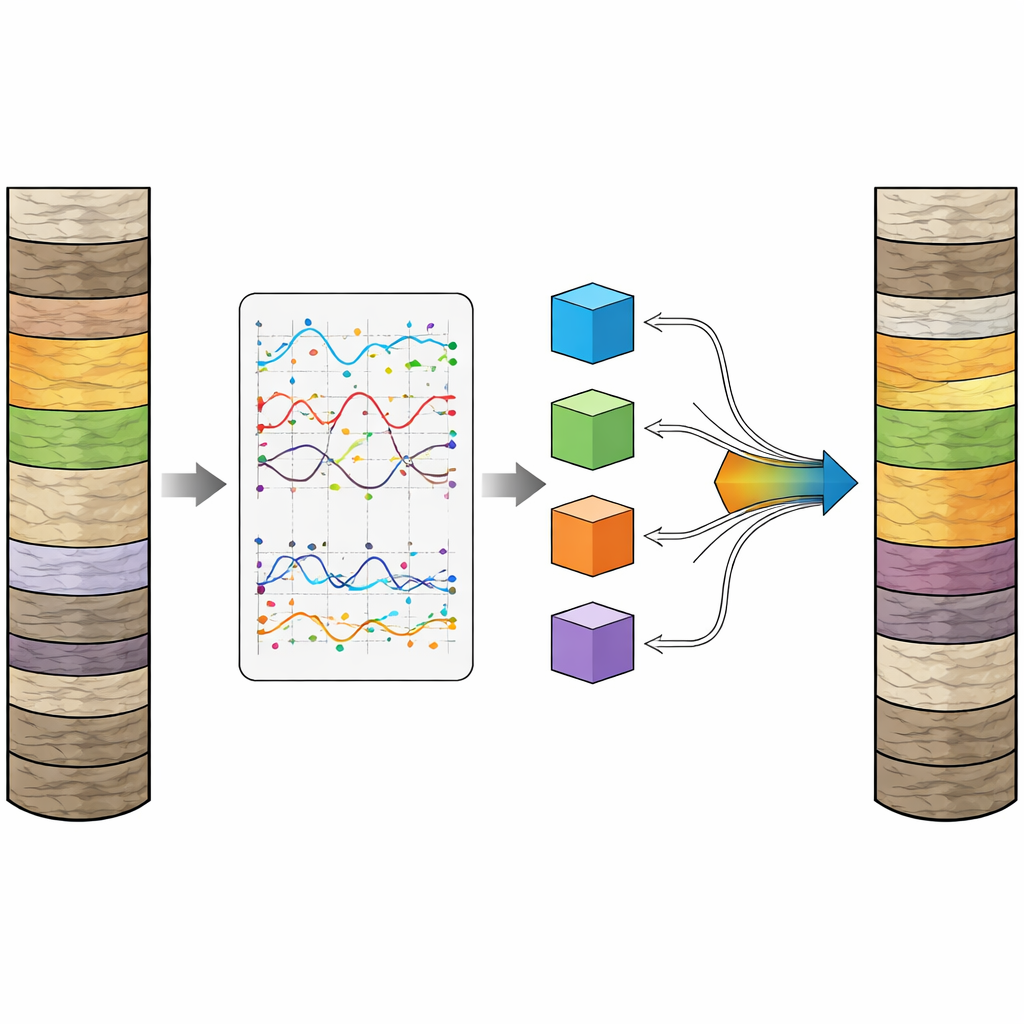
Ce que cela signifie pour l’énergie et la géologie
Pour les non-spécialistes, le message clé est que l’association du savoir métier avec l’intelligence artificielle peut extraire davantage d’informations des données existantes, sans forage supplémentaire ni travaux de laboratoire. En apprenant aux algorithmes à « penser géologiquement » pour identifier les couches susceptibles d’héberger des schistes riches en matière organique, et en traitant soigneusement des mesures de terrain désordonnées et inégales, cette étude propose un outil pratique pour cartographier les zones favorables dans des réservoirs de schiste continentaux. Bien que la méthode doive encore être testée dans d’autres bassins aux types de roche différents, elle ouvre la voie à un futur où des modèles plus intelligents contribuent à réduire le risque d’exploration, à mieux exploiter les puits existants et à guider un développement plus ciblé et efficace des ressources pétrolières non conventionnelles.
Citation: Lu, Y., Tian, F., Zhang, H. et al. A geology-constrained hybrid stacking ensemble method using well logs for TOC prediction in continental shale reservoirs. Sci Rep 16, 9059 (2026). https://doi.org/10.1038/s41598-026-39144-9
Mots-clés: huile de schiste, carbone organique total, diagraphies de puits, apprentissage automatique, caractérisation des réservoirs