Clear Sky Science · fr
Un cadre robuste de génération text-to-SQL en langage naturel avec des stratégies dynamiques basées sur des LLM
Transformer des questions courantes en réponses issues de bases de données
Les organisations modernes sont noyées dans les données, mais la plupart des personnes ne parlent pas le langage technique nécessaire pour les interroger. Cet article présente TriSQL, un système qui permet aux utilisateurs de poser des questions en langage courant et de les traduire automatiquement en commandes de base de données précises. En maîtrisant soigneusement la manière dont les grands modèles de langage gèrent la complexité, le cadre vise à rendre l’accès aux données à la fois plus exact et plus fiable, même pour les questions les plus difficiles.
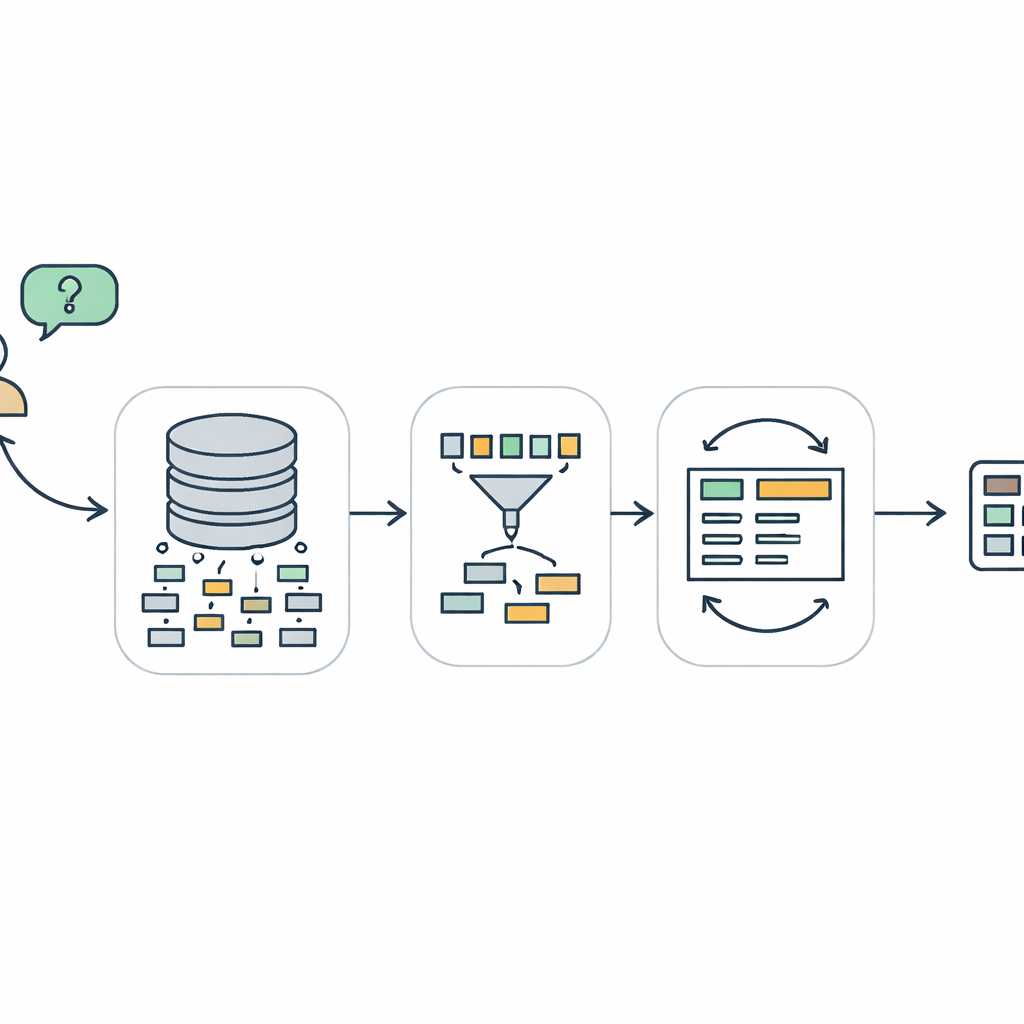
Pourquoi parler aux bases de données est si difficile
Quand quelqu’un tape une question comme « Quels clients ont acheté plus de cinq produits le mois dernier ? », un ordinateur doit la traduire en SQL, le langage spécialisé utilisé par la plupart des bases de données. Cette tâche, appelée text-to-SQL, paraît simple mais est étonnamment complexe. Le système doit comprendre l’intention de l’utilisateur, repérer les bonnes tables et colonnes dans une base parfois gigantesque et désordonnée, puis construire une requête à la fois structurellement valide et fidèle à l’intention initiale. Les systèmes précédents, y compris ceux alimentés par de grands modèles de langage, échouent souvent lorsque les questions impliquent de nombreuses tables, une logique imbriquée ou des conditions subtiles. Ils peuvent produire des requêtes qui ressemblent à des bonnes mais qui échouent à s’exécuter ou qui retournent des résultats incorrects une fois exécutées.
Un parcours en trois étapes de la question à la requête
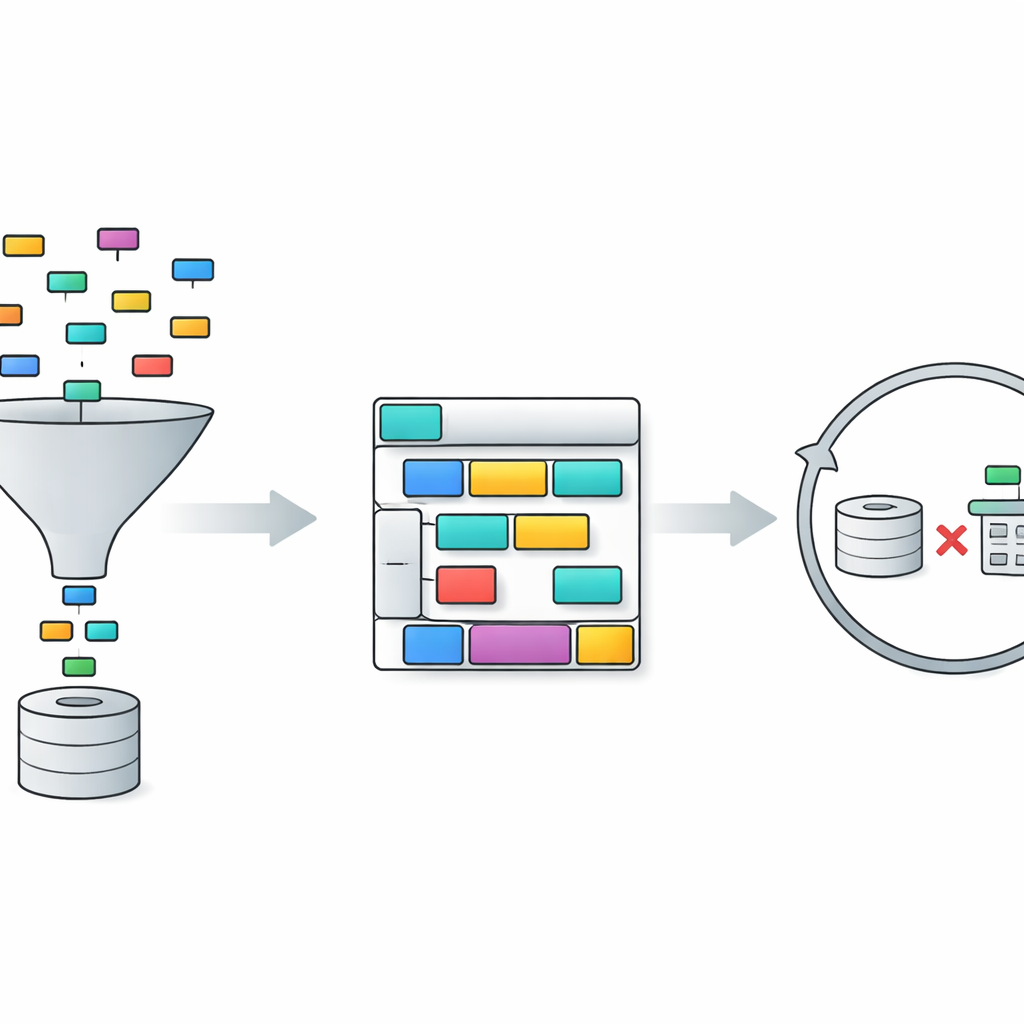
TriSQL s’attaque à ces problèmes avec un pipeline en trois étapes. D’abord, un sélecteur guidé par la question examine les mots de l’utilisateur et la structure complète de la base de données, et décide quelles tables et colonnes sont réellement pertinentes. Plutôt que d’exposer aveuglément le modèle de langage au schéma entier, il réduit la vue aux seules pièces utiles. Ensuite, un générateur conscient de la structure planifie la forme de la requête SQL avant d’en remplir les détails. Il esquisse d’abord un squelette de haut niveau — quelles clauses sont nécessaires et comment elles s’articulent — puis insère les tables, jointures et conditions spécifiques. Cette approche « structure d’abord, contenu ensuite » aide à préserver la grammaire rigide du SQL, en particulier pour les requêtes longues et complexes. Enfin, un affineur conscient de la complexité vérifie et améliore la requête initiale, en appliquant des stratégies différentes selon la difficulté apparente de la question.
Adapter l’effort à la difficulté de la question
La phase d’affinement est l’endroit où TriSQL exploite de manière particulièrement novatrice les grands modèles de langage. Le système évalue la complexité de chaque question et du brouillon de requête, en tenant compte de facteurs tels que le nombre de tables jointes, la profondeur des imbrications et les types de contraintes utilisés. Pour les cas simples, il n’applique que de légères corrections, par exemple pour corriger de petites erreurs de syntaxe. Pour les cas moyens, il réorganise les clauses et s’assure que la requête correspond au schéma choisi. Pour les questions les plus exigeantes, il mobilise le modèle de langage pour un raisonnement plus approfondi, parfois en décomposant le problème en sous-tâches et en exécutant des requêtes alternatives. Fait crucial, TriSQL exécute ensuite la requête originale et la requête raffinée contre la base de données et utilise leur comportement — si elles s’exécutent, le temps d’exécution et les résultats retournés — pour décider quelle version conserver ou s’il faut tenter un nouveau cycle d’affinement.
Mettre le système à l’épreuve
Pour évaluer les performances de TriSQL, les auteurs le testent sur un banc d’essai largement utilisé appelé Spider, ainsi que sur plusieurs variantes plus difficiles qui introduisent des connaissances de domaine, des structures de phrases inhabituelles et des structures de requêtes plus réalistes. Ils mesurent deux indicateurs : la correspondance exacte, qui vérifie si la chaîne SQL générée est identique à une référence humaine, et la précision d’exécution, qui vérifie si elle produit réellement la bonne réponse une fois exécutée. Sur ces ensembles de données, TriSQL atteint la meilleure précision d’exécution rapportée à ce jour tout en maintenant la correspondance exacte compétitive avec les meilleurs systèmes antérieurs. Il est aussi plus robuste : à mesure que les questions passent de faciles à extrêmement difficiles, la performance de TriSQL chute beaucoup plus lentement que celle des méthodes concurrentes. Des expériences supplémentaires sur un ensemble de données réel de gestion de réseau électrique montrent que le même cadre peut gérer non seulement la récupération de données, mais aussi les commandes d’insertion, de mise à jour, de suppression et de création de tables. Des adaptations pilotes à des bases de données graphiques (Cypher) et aux pipelines MongoDB suggèrent que la conception en trois étapes peut s’étendre au-delà du SQL classique.
Ce que cela signifie pour l’utilisation quotidienne des données
Concrètement, ce travail nous rapproche d’un monde où les personnes peuvent converser avec des bases de données complexes aussi facilement qu’elles discutent aujourd’hui avec des moteurs de recherche. En choisissant soigneusement quelles parties de la base de données considérer, en planifiant la structure d’une requête avant d’en remplir les détails et en adaptant l’usage des grands modèles de langage à la difficulté de chaque question, TriSQL produit des requêtes plus susceptibles de s’exécuter correctement et de retourner les résultats voulus. Si des défis subsistent — comme la gestion des questions ambiguës et des bases inconnues — l’étude montre qu’une conception réfléchie et en étapes peut rendre les interfaces en langage naturel pour les données à la fois plus puissantes et plus prévisibles pour les utilisateurs quotidiens.
Citation: Su, X., Gu, Y., Wang, P. et al. A robust natural language text-to-SQL generation framework with dynamic strategies based on LLMs. Sci Rep 16, 7892 (2026). https://doi.org/10.1038/s41598-026-39128-9
Mots-clés: text-to-SQL, interfaces en langage naturel, interrogation de bases de données, grands modèles de langage, robustesse des requêtes