Clear Sky Science · fr
Une approche pour traiter les jeux de données déséquilibrés en décalant la frontière
Pourquoi les cas rares comptent dans les données quotidiennes
De la fraude bancaire et du diagnostic médical à la prédiction de la perte de clients, nombre de décisions que nous demandons aux ordinateurs reposent sur la détection d'événements rares mais cruciaux. Dans la plupart des jeux de données réels, ces cas importants sont largement surpassés par les cas ordinaires. Un modèle qui voit surtout le « quotidien » peut devenir aveugle aux situations que nous considérons les plus importantes. Cet article présente une nouvelle façon de rééquilibrer de telles données biaisées afin que les algorithmes d'apprentissage accordent toute l'attention nécessaire aux cas rares à fort impact.
Le piège caché des données déséquilibrées
Lorsque qu'un type d'exemple l'emporte nettement sur un autre, les méthodes classiques d'apprentissage automatique ont tendance à se concentrer sur la majorité et à négliger silencieusement la minorité. Un système de prédiction de churn, par exemple, peut qualifier presque tout le monde de client fidèle et afficher une forte précision simplement parce que les churners réels sont très peu nombreux. Des problèmes similaires surviennent dans la détection d'accidents, la surveillance des fraudes et le dépistage médical, où les cas positifs sont rares mais coûteux à manquer. Les solutions traditionnelles se répartissent en deux approches : ajuster l'algorithme pour qu'il « tienne davantage compte » de la minorité, ou remodeler les données en supprimant certains cas majoritaires (sous‑échantillonnage) ou en créant des cas minoritaires supplémentaires (suréchantillonnage). Des outils de suréchantillonnage populaires comme SMOTE génèrent des exemples minoritaires synthétiques, mais ils peuvent involontairement encombrer la région frontalière délicate où les deux classes se rencontrent.
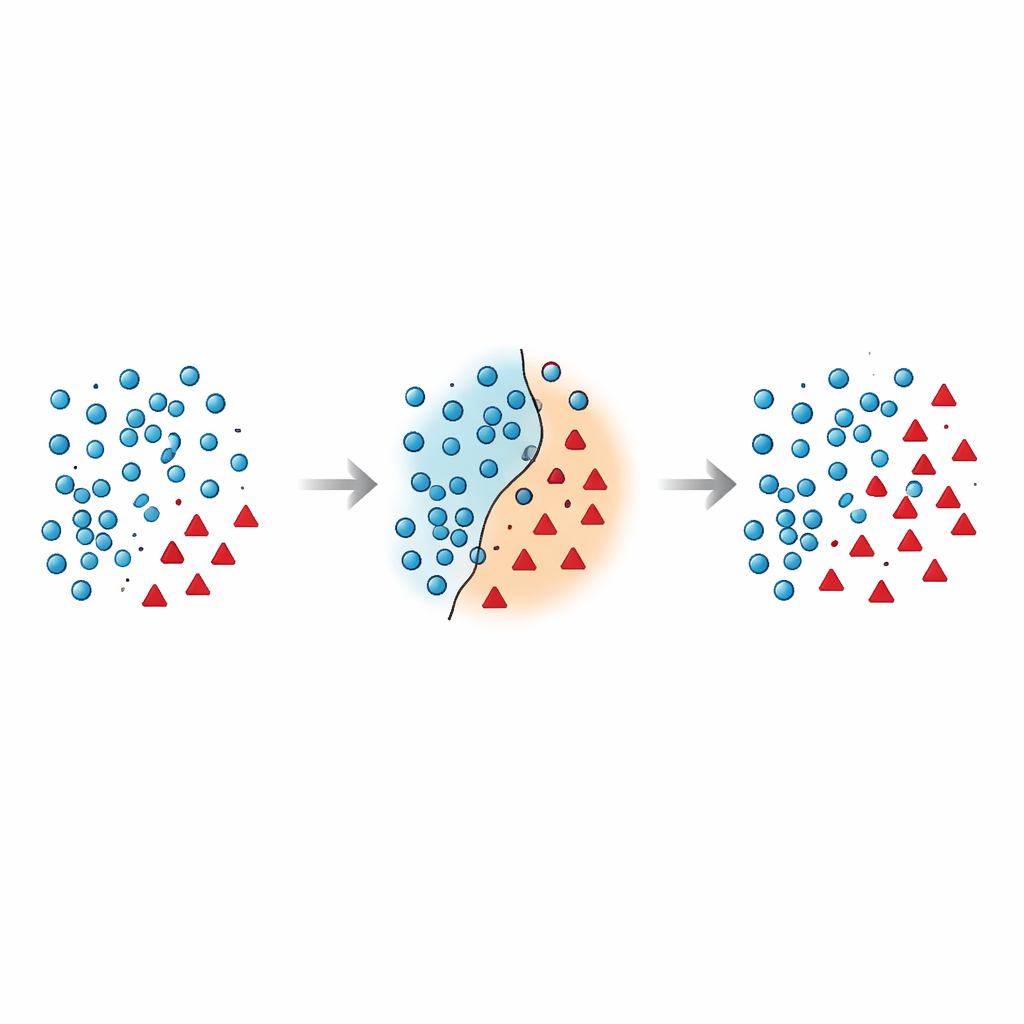
Pourquoi la frontière entre groupes est si fragile
Les auteurs soutiennent que les erreurs les plus dangereuses surviennent près de la frontière de décision — la zone où majorités et minorités se chevauchent dans l'espace des caractéristiques. De nombreuses techniques existantes ajoutent des points synthétiques dans cette zone à risque sans la nettoyer, ou suppriment agressivement des données en éliminant par inadvertance des exemples informatifs. Des travaux récents ont tenté d'atténuer cela en utilisant des contraintes géométriques, des estimations de densité locale ou des filtres de bruit, mais la plupart des méthodes traitent encore les points minoritaires sur place et repensent rarement la manière de gérer les points majoritaires proches de la frontière. Il en résulte un problème persistant : des échantillons qui se chevauchent et sont bruyants, ce qui embrouille le classificateur et conduit à des prédictions instables, en particulier sur des données nouvelles.
Une méthode en deux étapes pour nettoyer la frontière
L'article introduit Borderline Shifting Oversampling (BSO), une méthode de remodelage des données en deux phases qui cible explicitement cette région frontalière problématique. D'abord, elle scrute le voisinage de chaque exemple majoritaire pour décider s'il se trouve dans une zone sûre, sur la frontière, ou clairement erroné (bruit). Les points majoritaires entourés de voisins minoritaires sont soit reclassés vers le côté minoritaire, soit marqués comme bruit et supprimés, nettoyant et décalant ainsi la frontière pour qu'elle reflète mieux le schéma sous‑jacent. Dans la seconde phase, la méthode génère de nouveaux points minoritaires synthétiques par interpolation, à la manière de SMOTE, mais uniquement autour des échantillons minoritaires proches de la frontière raffinée. En concentrant les nouvelles données là où elles sont les plus informatives et en évitant les zones manifestement bruyantes, BSO construit un jeu d'entraînement à la fois plus équilibré en taille et plus propre en structure.
Éprouver la méthode
Pour évaluer l'efficacité pratique, les chercheurs ont testé BSO sur 30 jeux de données de référence avec des degrés variables de déséquilibre et de recouvrement. Ils l'ont comparée à sept alternatives largement utilisées, y compris le sur‑ et sous‑échantillonnage aléatoire, SMOTE, Borderline‑SMOTE, NearMiss, et deux méthodes hybrides qui combinent suréchantillonnage et nettoyage du bruit (SMOTE‑Tomek et SMOTE‑ENN). Trois classificateurs courants — machines à vecteurs de support, Naïve Bayes et forêts aléatoires — ont été entraînés sur chaque jeu rééchantillonné. Plutôt que de s'appuyer sur la précision brute, l'étude a utilisé des métriques plus informatives en contexte de déséquilibre, telles que le F1‑score, le G‑mean, le rappel, la précision et l'aire sous la courbe ROC (AUC). Sur presque tous les jeux de données et classificateurs, BSO a obtenu des scores supérieurs ou comparables tout en montrant moins de variation, ce qui signifie que ses avantages étaient constants plutôt que dépendants d'un modèle ou d'un réglage particulier.
Ce que cela change pour les décisions réelles
En termes concrets, l'approche Borderline Shifting agit comme un éditeur soigneux pour des données désordonnées : elle nettoie les exemples confus proches de la ligne de partage entre classes puis ajoute juste assez de cas minoritaires réalistes aux bons endroits. Le résultat est que les algorithmes d'apprentissage deviennent meilleurs pour reconnaître des événements rares mais importants sans être induits en erreur par des recouvrements bruyants. Pour des applications comme la détection de fraude, la prédiction d'accidents ou la priorisation médicale — où manquer un cas minoritaire peut coûter cher — cette méthode offre un moyen pratique de rendre les modèles plus justes, plus sensibles et plus fiables, tout en n'ajoutant qu'une surcharge computationnelle modeste.
Citation: Malhat, M.G., Elsobky, A.M., Keshk, A.E. et al. An approach for handling imbalanced datasets using borderline shifting. Sci Rep 16, 8264 (2026). https://doi.org/10.1038/s41598-026-39118-x
Mots-clés: déséquilibre des classes, suréchantillonnage, frontière de décision, détection d'anomalies, robustesse en apprentissage automatique