Clear Sky Science · fr
Une méthode pour compiler des objets géographiques de cartes d’images satellites à partir de données cartographiques vectorielles via l’apprentissage profond
Pourquoi il est important de changer ce que montrent les cartes
Les cartes en ligne donnent souvent l’impression d’être des fenêtres ouvertes sur le monde réel, mais ce que vous voyez depuis le ciel est soigneusement conçu. Les cartes d’images satellites sont appréciées parce qu’elles ressemblent à des lieux réels, et pourtant parfois il faut dissimuler des installations sensibles, nettoyer des scènes encombrées ou s’assurer que différents types de cartes concordent entre eux. Cet article présente une nouvelle façon d’« éditer » automatiquement les images satellites à l’aide de l’intelligence artificielle, afin que des bâtiments et des routes puissent être supprimés, ajoutés, déplacés ou remodelés tout en conservant un aspect naturel et convaincant. 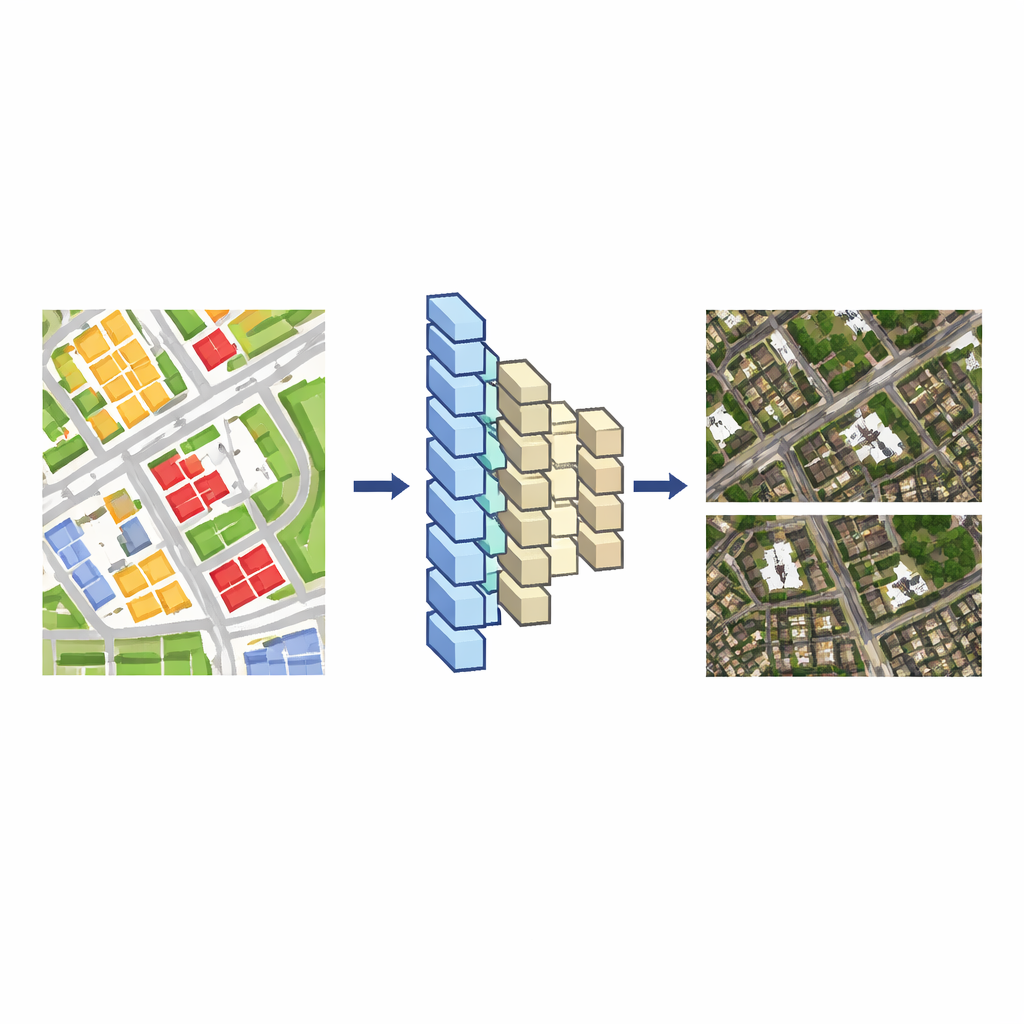
Des dessins simples aux vues réalistes
Les systèmes cartographiques modernes stockent généralement deux types de données géographiques. L’un est l’image satellite elle-même, un patchwork dense de pixels. L’autre est une carte vectorielle, un dessin plus propre composé de lignes et de formes qui indiquent routes, bâtiments, rivières et autres éléments. Modifier la carte vectorielle est relativement simple, mais retoucher l’image satellite correspondante à la main est lent et laborieux, car les pixels de chaque bâtiment se mêlent à des ombres, des arbres et des structures voisines. L’idée centrale des auteurs est d’apprendre à un modèle d’apprentissage profond à traduire ces dessins vectoriels en images satellites réalistes. Une fois que le modèle a appris ce lien, tout changement apporté à la carte vectorielle peut être automatiquement transformé en une modification cohérente de la vue satellite.
Apprendre à une IA à imaginer des villes
Pour construire ce traducteur, les chercheurs partent de zones où une carte vectorielle et une image satellite couvrent la même région à une échelle similaire. Ils découpent les deux en nombreuses petites tuiles, associant chaque tuile vectorielle à sa tuile d’image correspondante, et utilisent ces paires comme données d’entraînement. Un réseau de neurones encodeur–décodeur — similaire aux outils employés pour la traduction image-à-image — apprend comment l’agencement de blocs colorés et de lignes dans la tuile vectorielle se rapporte aux toits, rues et végétation dans la tuile satellite. Ils comparent deux architectures populaires, UNet++ et Pix2Pix, et constatent que Pix2Pix produit des images proches du rendu satellite qui correspondent mieux à la réalité et s’entraînent de façon fiable ; il devient donc leur modèle de base.
Concentrer le modèle sur les zones à modifier
Apprendre simplement à partir de la ville entière ne suffit pas lorsque l’on veut retoucher proprement des objets spécifiques. Pour affiner la capacité du modèle autour des zones ciblées, les auteurs utilisent l’apprentissage par transfert. Ils extraient des tuiles d’entraînement supplémentaires qui entourent les bâtiments ou les routes qu’ils prévoient d’éditer et lancent une courte phase d’entraînement additionnel en n’utilisant que ces exemples locaux. Cette étape de réglage fin améliore grandement la fidélité du modèle à reproduire ces quartiers, rendant les modifications ultérieures plus nettes et plus précises. 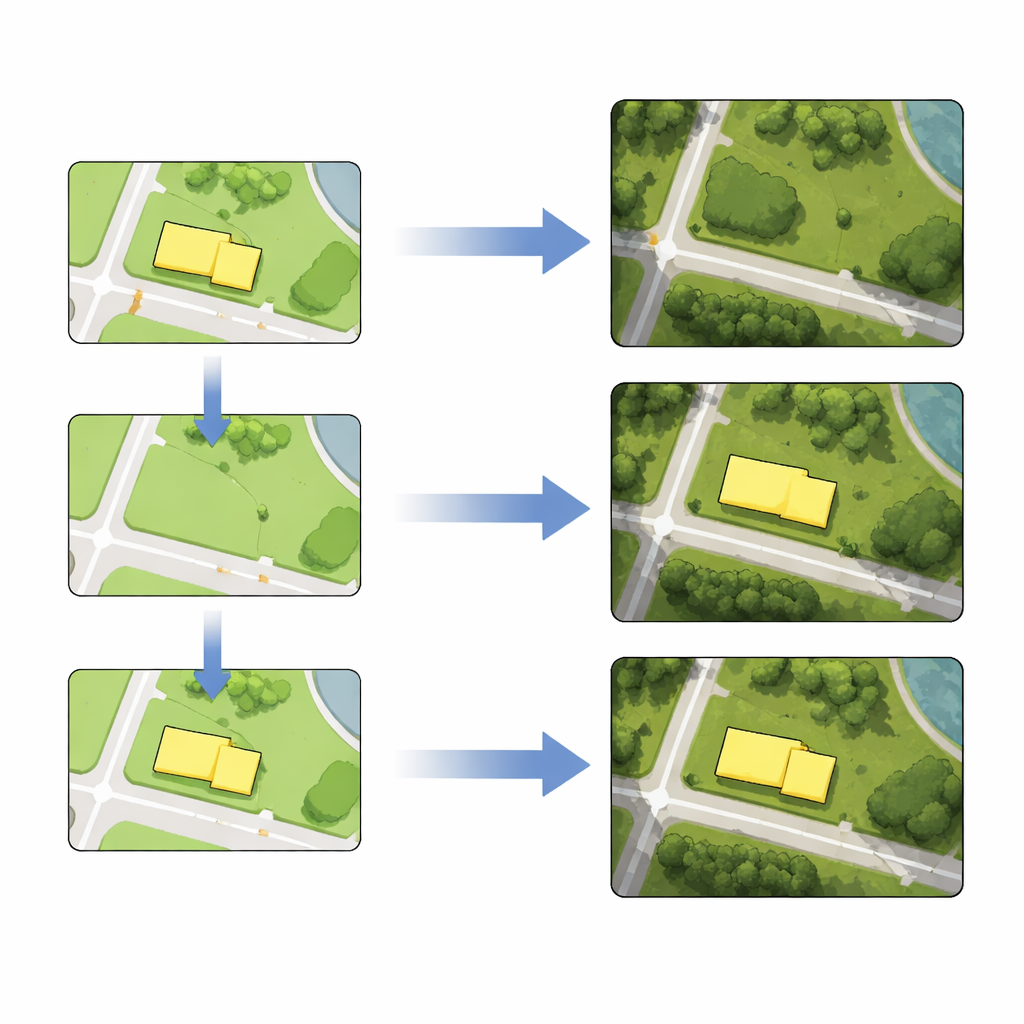
Éditer bâtiments et routes comme des couches cartographiques
Avec le modèle affiné en place, la compilation de cartes d’images satellites devient une recette en trois étapes. D’abord, un cartographe édite la carte vectorielle : supprimer un bâtiment, tracer une nouvelle route, remodeler un îlot ou déplacer un objet à un nouvel emplacement. Ensuite, les tuiles éditées de la carte vectorielle sont injectées dans le réseau entraîné, qui génère de nouvelles tuiles satellite reflétant le changement souhaité tout en préservant le détail et la texture environnants. Enfin, ces tuiles générées remplacent les tuiles d’image originales. En utilisant des données réelles de Berlin, les auteurs démontrent les quatre opérations — suppression, insertion, distorsion et déplacement — tant pour les empreintes de bâtiments que pour les tracés de routes, individuellement ou par lots. Les mesures montrent que les positions des objets modifiés dans les images générées diffèrent de leurs homologues vectoriels de seulement quelques pixels, une précision acceptable pour de nombreuses tâches cartographiques.
Ce que cela implique pour les cartes de demain
En termes simples, l’étude montre qu’une fois qu’une IA a appris comment les cartes vectorielles et les images satellites correspondent, on peut éditer le dessin simplifié et laisser le modèle repeindre une vue aérienne crédible pour l’adapter. Cela ouvre la voie à des cartes d’images satellites personnalisables : dissimuler des sites sensibles, clarifier des scènes complexes ou mêler espaces réels et imaginés tels que des mondes de jeu et des environnements virtuels. En même temps, cela met en lumière la puissance — et le risque — de la « géographie deepfake », où des images aériennes à l’apparence réaliste peuvent ne plus être de simples photographies du monde tel qu’il est.
Citation: Du, J., Zeng, D., Cai, K. et al. A method for compiling satellite image map geographic objects based on vector map data via deep learning. Sci Rep 16, 9295 (2026). https://doi.org/10.1038/s41598-026-39096-0
Mots-clés: imagerie satellite, apprentissage profond, édition de cartes, télédétection, cartographie deepfake