Clear Sky Science · fr
Les grands modèles de langage montrent des effets semblables au biais de Dunning-Kruger dans la vérification multilingue des faits
Pourquoi une bonne vérification des faits concerne tout le monde
La désinformation se propage aujourd’hui plus vite que jamais, influençant ce que les gens croient au sujet de la santé, de la politique, de la science et de la vie quotidienne. De nombreuses plateformes et salles de rédaction s’appuient désormais sur l’intelligence artificielle — en particulier les grands modèles de langage, ou LLM — pour aider à déterminer si des affirmations virales sont vraies ou fausses. Cette étude pose une question apparemment simple mais cruciale : lorsque nous laissons ces systèmes juger des faits, à quelle fréquence ont-ils raison, à quel point se montrent-ils assurés, et cela varie-t-il selon les langues et les régions du monde ?
Comment les chercheurs ont confronté l’IA à des rumeurs du monde réel
Plutôt que d’inventer des exemples artificiels, les auteurs ont construit leurs tests à partir de 5 000 affirmations authentiques que des organisations professionnelles de vérification des faits dans le monde avaient déjà examinées. Ces affirmations couvraient 47 langues et provenaient à la fois du Nord et du Sud globaux, reflétant la réalité multiforme et désordonnée des rumeurs en ligne. Seules ont été retenues les déclarations dotées de verdicts clairement « vrai » ou « faux » — approuvés par plusieurs vérificateurs — constituant une base solide pour la comparaison.
Ils ont ensuite soumis neuf modèles de langage largement utilisés, depuis des systèmes open source plus modestes jusqu’à des modèles commerciaux avancés, à chaque affirmation. Pour refléter la façon dont les gens interagissent réellement avec les chatbots, la plupart des invites étaient de simples questions comme « Est-ce vrai ? » ou « Est-ce faux ? », rédigées dans la même langue que l’affirmation. Un quatrième protocole, plus professionnel, utilisait en anglais des instructions détaillées transformant le modèle en vérificateur virtuel et demandant des sorties structurées. Des annotateurs humains ont lu attentivement les réponses des modèles et les ont étiquetées comme affirmant que l’assertion était vraie, fausse ou refusant de donner un verdict clair.
Mesurer non seulement le juste ou le faux, mais aussi quand dire « je ne sais pas »
L’équipe n’a pas seulement comptabilisé les réussites et les erreurs. Elle a utilisé trois mesures clés pour cerner le comportement des modèles. D’abord, l’« exactitude sélective » a évalué la fréquence à laquelle un modèle avait raison lorsqu’il prenait position et déclarait une affirmation vraie ou fausse. Ensuite, l’« exactitude tolérante à l’abstention » a considéré comme acceptable, voire souhaitable, que le modèle reconnaisse son incertitude au lieu de deviner — essentiel dans des domaines sensibles comme la médecine ou les élections. Enfin, le « taux de certitude » a suivi la fréquence à laquelle un modèle donnait une réponse définitive, servant d’indicateur approximatif de son comportement confiant.
L’invite de style professionnel, avec ses consignes pas à pas, a systématiquement amélioré l’exactitude sur l’ensemble des modèles. Mais elle a aussi révélé un compromis : les modèles plus petits sont souvent devenus plus décidés sans pour autant être plus fiables, tandis que les grands modèles ont profité de la structure pour fournir moins de réponses, mais meilleures. Les invites du quotidien, de type conversation, ont produit des comportements plus prudents, surtout chez les modèles faibles, mais ont aussi légèrement réduit leur exactitude.
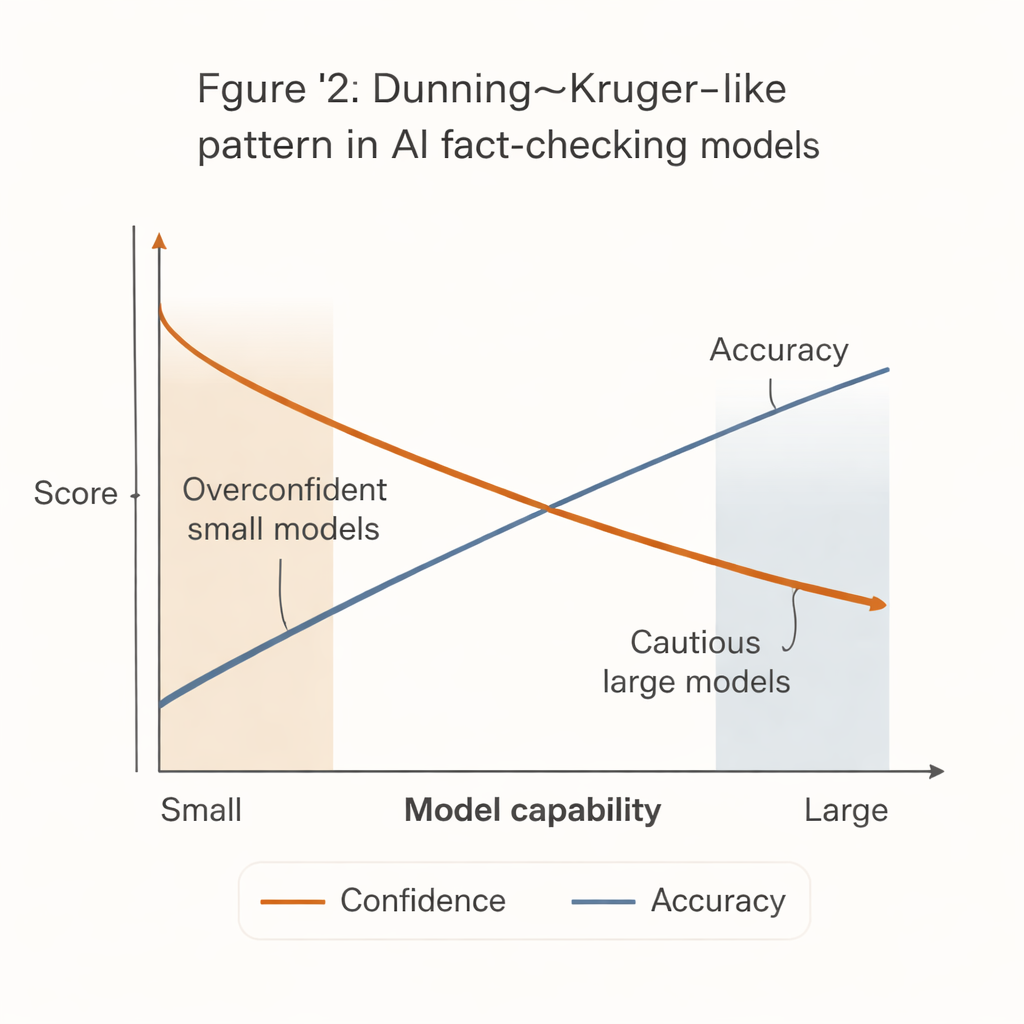
Quand des systèmes moins capables se montrent plus sûrs d’eux
Un schéma frappant est apparu, rappelant l’effet Dunning–Kruger bien connu en psychologie humaine : les systèmes les moins capables se montraient les plus confiants. Les modèles petits et peu coûteux avaient tendance à émettre des verdicts fermes sur une large majorité d’affirmations, mais avec une exactitude nettement inférieure. En revanche, les modèles les plus puissants — tels que certaines versions avancées de GPT — étaient beaucoup plus précis quand ils s’engageaient, tout en étant beaucoup plus enclins à s’abstenir, notamment sur des énoncés difficiles ou ambigus.
Ce « fossé confiance‑compétence » a des conséquences concrètes. De nombreuses salles de rédaction aux moyens limités, organisations de la société civile et petits organismes de vérification des faits n’ont pas les moyens des systèmes d’IA les plus puissants. Ils sont plus susceptibles d’adopter des modèles plus petits et moins chers qui paraissent décidés mais se trompent plus souvent. Si ces outils sont intégrés à des flux de travail ou à des systèmes de modération communautaire sans garde‑fous, ils pourraient en réalité amplifier la désinformation en produisant des vérifications confiantes mais incorrectes.
Des performances inégales selon les langues et les régions
L’étude révèle aussi que ces systèmes ne performent pas de manière égale pour tous. Sur plusieurs langues majeures, les modèles ont généralement obtenu leurs meilleurs résultats sur les affirmations en anglais et des performances légèrement inférieures en portugais et en hindi. Les grands modèles avaient tendance à répondre plus prudemment dans les langues non anglaises, mais surpassaient néanmoins les plus petits en termes d’exactitude. Lorsque les auteurs ont comparé des affirmations liées au Nord global et au Sud global, la plupart des modèles ont eu plus de difficultés avec ces dernières. Les petits systèmes restaient souvent confiants tout en perdant en exactitude, tandis que les grands modèles montraient des baisses plus marquées de certitude mais des diminutions plus faibles de précision, ce qui suggère qu’ils percevaient leur propre incertitude et se retenaient.
Ce que cela implique pour l’avenir des outils d’IA de confiance
Pour un non‑spécialiste, le message principal est clair : les vérificateurs automatiques d’aujourd’hui sont loin d’être équivalents, et les plus accessibles peuvent être les plus trompeurs. Les modèles puissants peuvent se montrer prudents et précis, mais ils sont coûteux et parfois excessivement hésitants. Les modèles plus faibles sont audacieux mais ont davantage de chances de se tromper, surtout en dehors de l’anglais et sur des sujets provenant du Sud global. Les auteurs soutiennent que l’IA devrait soutenir, et non remplacer, les vérificateurs humains, et que les choix de politiques et de conception doivent favoriser une meilleure calibration — apprendre aux systèmes quand se taire — et un accès plus équitable à des outils de haute qualité. Sans cela, la même technologie conçue pour lutter contre la désinformation pourrait creuser les inégalités informationnelles qu’elle vise à résoudre.
Citation: Qazi, I.A., Khan, Z., Ghani, A. et al. Large language models show Dunning-Kruger-like effects in multilingual fact-checking. Sci Rep 16, 7594 (2026). https://doi.org/10.1038/s41598-026-39046-w
Mots-clés: désinformation, vérification des faits, grands modèles de langage, confiance de l'IA, biais multilingue