Clear Sky Science · fr
Un cadre hybride LSTM-GRU pour la classification du cancer du poumon utilisant l’algorithme GWO-WOA pour l’optimisation des hyperparamètres et BPSO pour la sélection de caractéristiques
Pourquoi cela compte pour la santé quotidienne
Détecter le cancer du poumon tôt peut sauver des vies, mais beaucoup de personnes n’ont pas accès à des examens avancés avant qu’il ne soit trop tard. Cette étude explore si des contrôles simples basés sur des questionnaires — sur l’âge, le tabagisme, les symptômes et les habitudes quotidiennes — peuvent être combinés à l’intelligence artificielle moderne pour repérer des personnes à haut risque bien avant l’apparition d’une maladie sévère. En tirant parti de questionnaires peu coûteux et de modèles informatiques intelligents, ce travail ouvre la voie à des outils de dépistage plus rapides et plus accessibles susceptibles, un jour, d’aider médecins et programmes de santé publique dans le monde entier.
Transformer de simples questions en signaux utiles
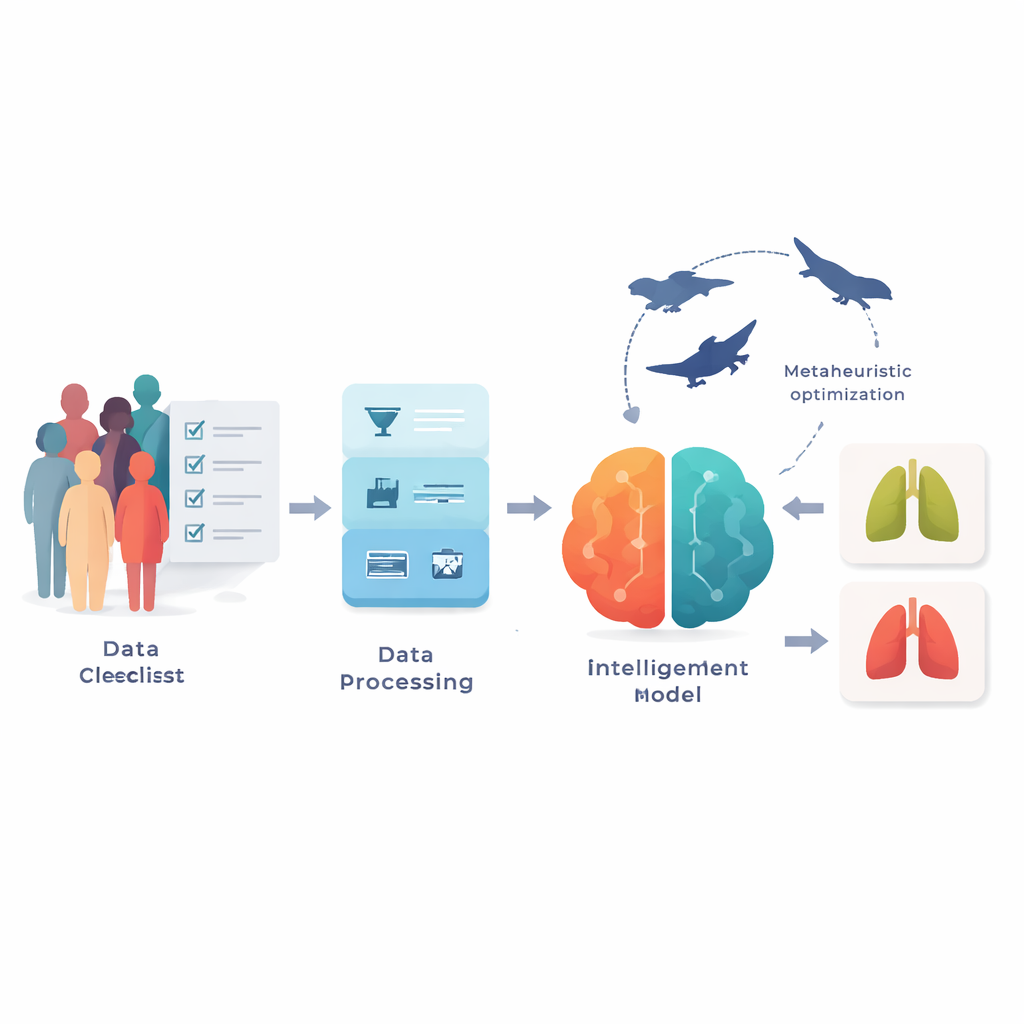
Les chercheurs ont utilisé deux jeux de données publics du site Kaggle, couvrant ensemble plus de 3 300 personnes. Plutôt que des images médicales, chaque enregistrement contient 15 éléments que l’on trouve sur un formulaire clinique : âge, sexe, statut tabagique, doigts jaunis, toux, essoufflement, douleur thoracique et autres facteurs de risque et symptômes, ainsi qu’une étiquette indiquant la présence ou non d’un cancer du poumon. Parce que les données d’enquête réelles sont désordonnées, l’équipe a d’abord nettoyé l’information en corrigeant les valeurs manquantes, en supprimant les doublons et en harmonisant le codage des réponses entre les deux jeux. Ils ont aussi mis les valeurs à la même échelle et utilisé une méthode d’équilibrage pour corriger l’importante prédominance de cas de cancer dans le plus petit jeu de données, afin d’éviter que le modèle ne soit biaisé vers la prédiction de la classe majoritaire.
Laisser l’ordinateur choisir les questions les plus révélatrices
Toutes les questions d’un formulaire ne sont pas également utiles pour détecter une maladie, et en utiliser trop peut brouiller un modèle. Pour se concentrer sur l’essentiel, les auteurs ont employé une stratégie de recherche inspirée des essaims appelée Binary Particle Swarm Optimization. Concrètement, de nombreux « ensembles de questions » candidats sont testés en parallèle ; ils explorent l’espace des possibilités en imitant et en améliorant les meilleurs éléments. Au fil du processus, on est arrivé à des jeux compacts d’environ sept questions clés, mettant régulièrement en avant des éléments tels que le tabagisme, les doigts jaunis, la toux, la douleur thoracique, la respiration sifflante, l’essoufflement et les maladies chroniques. Ces sous-ensembles ciblés ont amélioré la précision de plusieurs points de pourcentage par rapport à l’utilisation des 15 questions, tout en rendant le modèle final plus facile à interpréter et plus rapide à exécuter.

Un moteur plus intelligent pour lire les motifs dans les réponses
Pour transformer les réponses du questionnaire en une prédiction binaire de cancer, l’équipe a construit un modèle hybride qui combine deux unités d’apprentissage profond liées et souvent utilisées pour des séquences : Long Short-Term Memory (LSTM) et Gated Recurrent Unit (GRU). Bien que les réponses d’un questionnaire ne soient pas des séries temporelles comme la parole ou la vidéo, des groupes de symptômes et d’habitudes forment néanmoins des motifs qui peuvent être traités comme de courtes séquences. Le modèle alimente d’abord les questions sélectionnées dans des couches LSTM capables de stocker et d’oublier sélectivement des informations, puis dans des couches GRU qui affinent ces motifs avec moins d’opérations internes et un coût de calcul réduit. Pour éviter les tâtonnements de conception, les auteurs ont réglé des paramètres cruciaux — tels que le taux d’apprentissage, le nombre d’unités cachées, la taille des lots et le dropout — à l’aide d’une couche secondaire de recherche inspirée de la nature qui combine l’exploration large des « loups gris » et les ajustements fins des « baleines ». Cet optimiseur conjoint recherche des combinaisons d’hyperparamètres qui donnent de manière consistante une haute précision lors de la validation croisée.
Performances du système
Après entraînement, le modèle hybride LSTM–GRU a été comparé à plusieurs références solides, notamment des réseaux LSTM et GRU isolés, un réseau de neurones convolutionnel, des machines à vecteurs de support classiques, et des méthodes basées sur les arbres comme les forêts aléatoires et le gradient boosting. Sur le plus petit jeu de données de 309 personnes, le système proposé a correctement classé chaque cas dans la partition de test mise de côté, atteignant 100 % de précision, précision positive, rappel et F1-score. Sur le plus grand jeu de 3 000 personnes, il est resté quasi parfait, avec environ 99,3 % de précision et des scores tout aussi élevés pour les autres mesures, surpassant tous les modèles concurrents d’apprentissage profond et classiques. Les auteurs ont aussi montré que leur stratégie en deux étapes — d’abord la sélection de questions par la recherche par essaim, puis le réglage du réseau hybride avec l’optimiseur loups‑et‑baleines — donnait des résultats plus stables à travers des exécutions répétées de validation croisée que des configurations plus simples.
Ce que cela signifie pour le dépistage futur du poumon
Concrètement, ce travail montre qu’un système d’IA soigneusement conçu peut lire des réponses de questionnaires ordinaires et distinguer avec une grande précision, sur des jeux de données de référence, les personnes avec et sans cancer du poumon. Il ne remplace pas les scanners, les médecins ni les essais cliniques, et les auteurs soulignent que leurs données sont limitées et pas encore prêtes pour une utilisation directe en milieu hospitalier. Néanmoins, l’approche démontre que combiner une sélection intelligente de questions avec des moteurs d’apprentissage profond finement réglés peut transformer des formulaires peu coûteux en puissants outils d’alerte précoce. Avec des tests supplémentaires sur des populations plus larges et cliniquement validées et des méthodes d’explicabilité améliorées pour montrer pourquoi le modèle signale une personne comme à risque, des systèmes similaires pourraient un jour aider à décider qui doit être orienté vers des examens d’imagerie plus approfondis, favorisant un diagnostic plus précoce tout en maintenant le dépistage abordable et non invasif.
Citation: Amrir, M.M.S., Ayid, Y.M., Elshewey, A.M. et al. A hybrid LSTM-GRU framework for lung cancer classification using GWO-WOA algorithm for hyperparameter tuning and BPSO for feature selection. Sci Rep 16, 8600 (2026). https://doi.org/10.1038/s41598-026-39020-6
Mots-clés: dépistage du cancer du poumon, données de questionnaire, apprentissage profond, sélection de caractéristiques, IA médicale