Clear Sky Science · fr
Des grands modèles de langue ajustés par fine-tuning avec des prompts structurés permettent la construction efficace de graphes de connaissances sur le cancer du poumon
Pourquoi transformer le texte médical en cartes importe
Le cancer du poumon est l’un des cancers les plus meurtriers au monde, et les informations sur son diagnostic et son traitement sont dispersées dans des articles de recherche, des notes hospitalières, des consultations en ligne et des recueils de médecine traditionnelle. Les médecins et les chercheurs peinent à suivre ce flux massif de texte. Cette étude explore une nouvelle méthode pour transformer automatiquement ces connaissances éparses en une « carte » unique et navigable — un graphe de connaissances sur le cancer du poumon — en utilisant un grand modèle de langue ajusté par fine-tuning et des prompts soigneusement structurés. L’objectif est de rendre ce savoir médical complexe plus facile à interroger par les ordinateurs et plus utile pour les experts dans des outils d’aide à la décision.
Des récits dispersés aux faits connectés
Les auteurs partent d’une idée simple : si l’on peut extraire de manière fiable qui fait quoi à quoi dans le texte médical, on peut assembler ces faits en un graphe. Concrètement, il s’agit de convertir des phrases libres en petits blocs élémentaires appelés triples — des paires d’entités reliées par une relation, par exemple « cancer du poumon – traité par – chimiothérapie ». Les méthodes traditionnelles de construction de tels graphes nécessitent soit des armées d’annotateurs, soit des règles fragiles qui manquent de nuance et ne captent pas les découvertes récentes. Pour surmonter ces limites, l’équipe ajuste par fine-tuning un modèle chinois existant, ChatGLM-6B, afin qu’il se spécialise dans la détection de triples médicalement signifiants sur le cancer du poumon à partir d’un large éventail de sources, des discussions patients‑médecins en ligne aux bases de données structurées et aux dossiers de médecine traditionnelle chinoise. 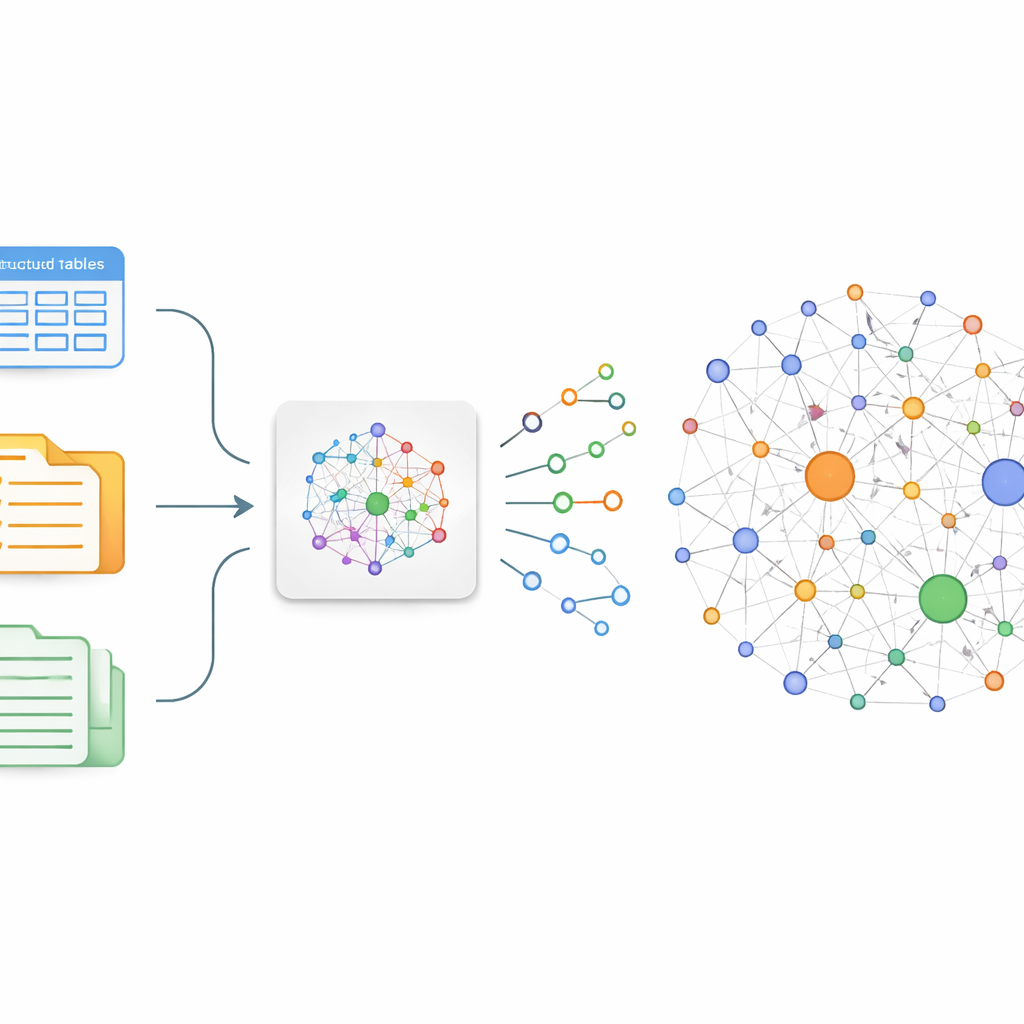
Apprendre à une IA à penser en unités nettes
Demander simplement à un modèle de langue généraliste « d’extraire des informations » produit souvent des réponses désordonnées et verbeuses. Les chercheurs conçoivent donc un schéma de prompt strict puis ajustent le modèle sur près de 50 000 exemples de bonne pratique. Chaque exemple présente une instruction et la sortie attendue exactement au format triple. Le prompt demande au modèle d’agir comme un expert professionnel en fouille de texte, de produire uniquement des triples structurés dans un format lisible par machine et de « penser pas à pas » lorsque les phrases contiennent des détails imbriqués — par exemple un traitement, le médicament utilisé et sa posologie. Cette combinaison de cadrage du rôle, de règles de format et de raisonnement pas à pas transforme le modèle — désormais appelé KGLM — d’un assistant conversationnel en un extracteur discipliné de faits prêts pour les machines.
Fusionner de nombreuses voix en un seul graphe clair
Les triples bruts extraits du texte ne constituent qu’une partie de l’histoire. La même maladie ou le même médicament apparaît souvent sous des noms différents — « bronchopneumopathie chronique obstructive » versus « BPCO », par exemple. Pour éviter l’encombrement et la confusion, les auteurs conçoivent une étape de fusion qui regroupe les entités équivalentes provenant de trois flux de données : texte web non structuré, cas cliniques semi‑structurés et graphes de connaissances médicaux existants. D’abord, un contrôle de similarité rapide basé sur les chaînes de caractères signale les correspondances évidentes. Lorsque cela ne suffit pas, un modèle de similarité sémantique plus profond (Sentence-BERT) compare les significations dans leur contexte. Les entités jugées dupliquées sont fusionnées en un nœud canonique unique, en privilégiant les noms plus courts et en conservant les autres formes comme alias. Des experts examinent ensuite les cas limites et suppriment les énoncés trompeurs ou de faible qualité, produisant un graphe de connaissances sur le cancer du poumon plus propre et plus cohérent, stocké dans une base Neo4j. 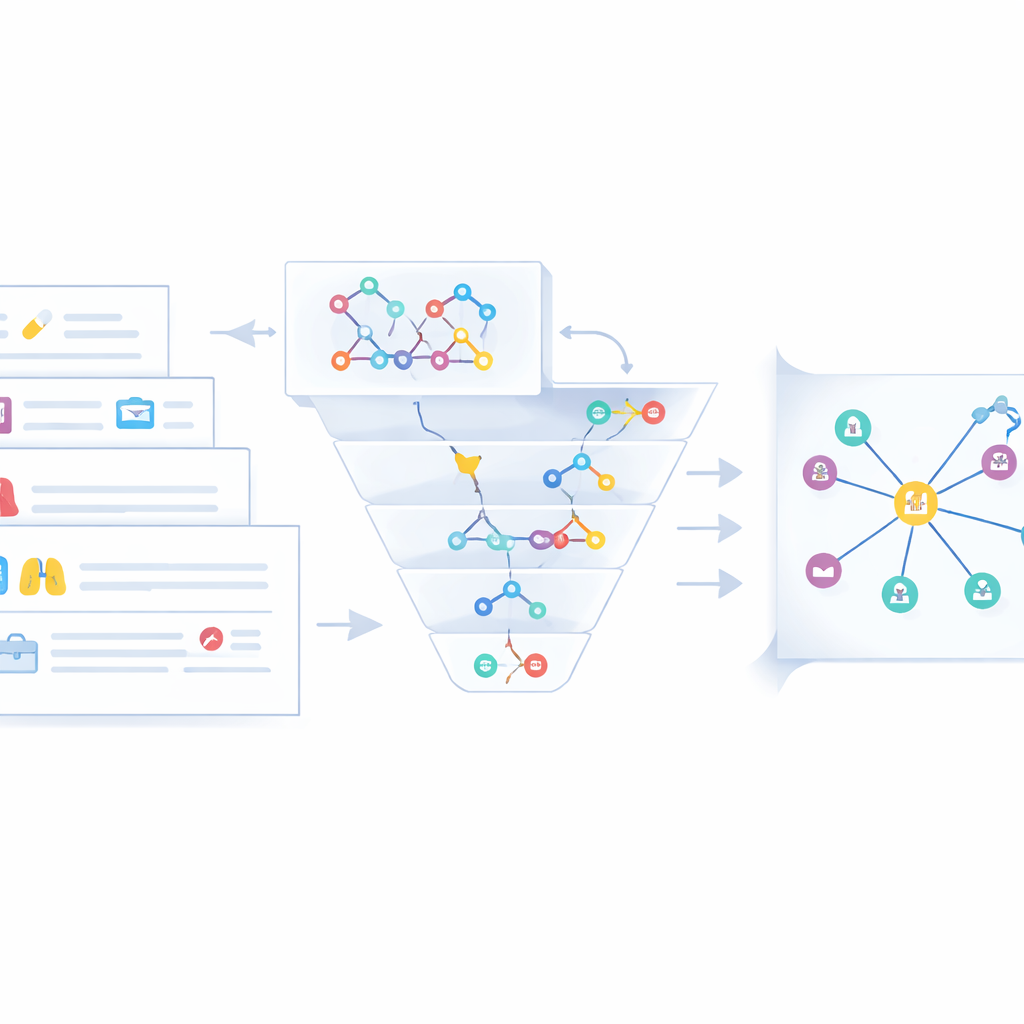
Quelle est l’efficacité de cette carte de connaissances ?
Pour évaluer la performance, l’équipe compare KGLM à des approches d’apprentissage profond standard basées sur BERT et des réseaux convolutionnels, ainsi qu’au modèle ChatGLM d’origine non ajusté. Sur la tâche d’extraction de relations — décider quelles entités sont liées et comment — le KGLM ajusté et guidé par des prompts atteint un score F1 d’environ 0,82, surpassant toutes les méthodes de référence testées et améliorant d’environ 25 % le modèle de départ. Des tests d’ablation montrent que chaque composante du prompt compte : supprimer le rôle d’expert, le format strict en triples ou la consigne « penser pas à pas » dégrade la précision, en particulier pour les phrases complexes avec attributs imbriqués ou terminologie de la médecine traditionnelle chinoise. Un panel d’experts cliniques et en informatique juge également le graphe obtenu plus précis, utilisable et pertinent cliniquement que les graphes construits sans fine‑tuning ni prompts structurés.
Ce que cela signifie pour les futurs outils médicaux
En termes simples, l’étude montre qu’avec le bon entraînement et des instructions appropriées, un grand modèle de langue peut transformer efficacement des textes réels et désordonnés sur le cancer du poumon en un réseau structuré et interrogeable de faits. Ce graphe de connaissances sur le cancer du poumon, bien qu’il reste un prototype de recherche et limité à des sources en langue chinoise et à une seule pathologie, ouvre la voie à un avenir où des « cartes de connaissances » constamment mises à jour pourraient alimenter des systèmes d’aide à la décision, des outils pédagogiques et l’exploration de la recherche. Les auteurs insistent sur le fait que de tels graphes doivent être rigoureusement validés et régulièrement mis à jour, et ne sont pas prêts à guider la prise en charge sans la supervision d’experts. Néanmoins, leurs résultats suggèrent que des modèles de langue ajustés et des prompts intelligents peuvent rendre la tâche ardue d’organisation des connaissances médicales plus évolutive et plus opportune.
Citation: Zhou, C., Gong, Q., Luan, H. et al. Fine-tuned large language models with structured prompts enable efficient construction of lung cancer knowledge graphs. Sci Rep 16, 9505 (2026). https://doi.org/10.1038/s41598-026-38959-w
Mots-clés: cancer du poumon, graphe de connaissances, grand modèle de langue, extraction de relations, IA médicale