Clear Sky Science · fr
Un cadre d’apprentissage profond à double flux pour la reconnaissance continue de la langue des signes afin d’améliorer l’accessibilité à la communication dans la région de Ha’il
Combler le fossé de la communication
Pour de nombreuses personnes sourdes, la langue des signes est le principal moyen de communication, mais la plupart des ordinateurs, téléphones et services publics ne la comprennent toujours pas. Cet article présente un nouveau système d’intelligence artificielle capable d’analyser des vidéos de signes continus et de les convertir en texte de manière plus précise. En prêtant attention non seulement aux mouvements des mains mais aussi à la position de la tête et aux indices faciaux, le système vise à rendre la communication assistée par la technologie plus naturelle et plus accessible — en particulier pour les communautés sourdes de la région de Ha’il en Arabie saoudite, où le soutien numérique reste limité. 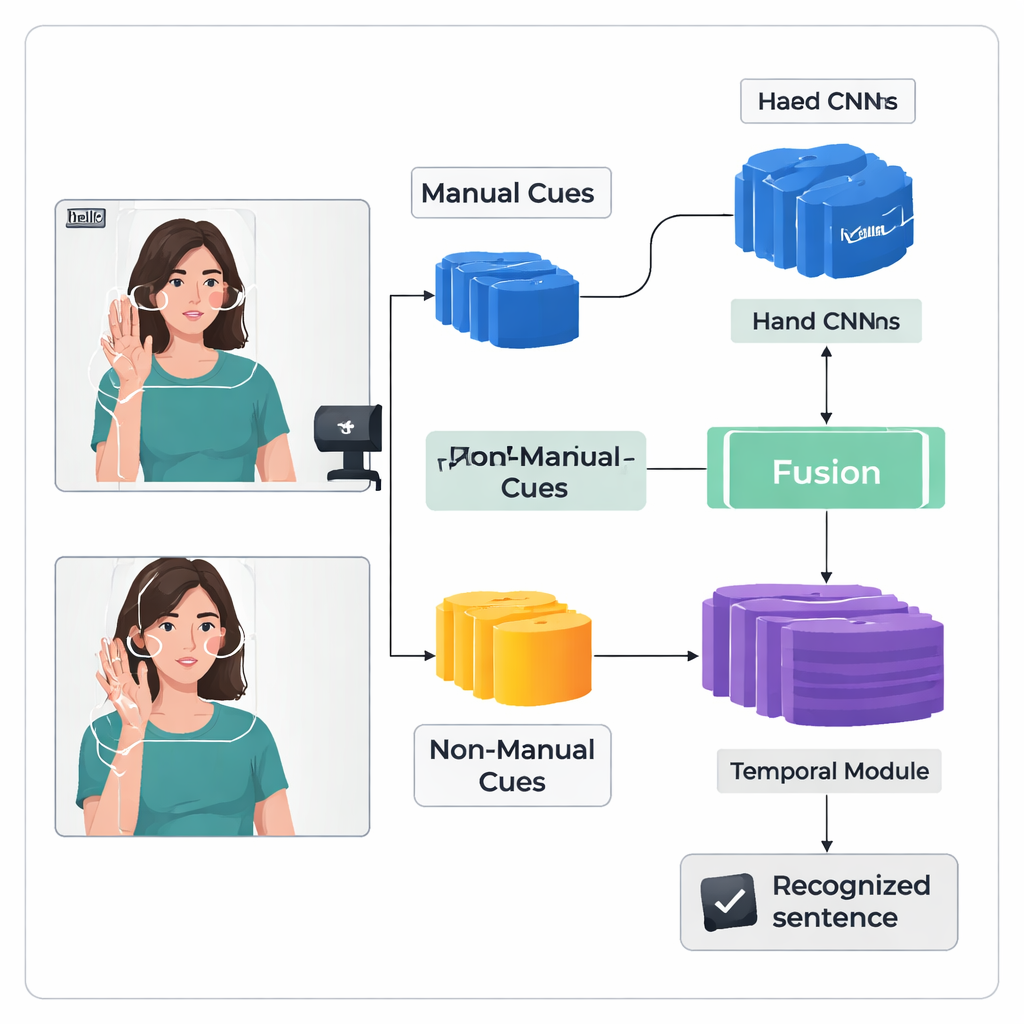
Pourquoi les mains ne suffisent pas
Les langues des signes sont des systèmes riches et complexes qui mobilisent le haut du corps dans son ensemble. Le sens ne provient pas seulement des mouvements des mains, mais aussi des expressions faciales, du regard et de l’inclinaison ou du hochement de la tête. Ces signaux non manuscrits peuvent marquer des questions, la négation, l’emphase ou l’émotion. Les humains lisent tout cela sans effort, mais la plupart des systèmes informatiques de reconnaissance de la langue des signes se concentrent presque entièrement sur les mains. Ce raccourci simplifie l’entraînement mais fait perdre des indices importants, en particulier lorsque les signes s’enchaînent rapidement dans des phrases continues plutôt que sous forme de mots isolés.
Deux flux travaillant en parallèle
Les auteurs présentent un cadre d’apprentissage profond « à double flux » nommé TS-CNN qui traite séparément les mains et la tête, puis les combine. Un flux se concentre sur des images recadrées des mains du signant, apprenant des motifs de forme, de mouvement et de position. L’autre flux reçoit une carte compacte du visage et de la tête, dérivée de points repères et d’estimations de l’orientation de la tête. Les deux flux utilisent un type standard de réseau de vision pour transformer chaque image vidéo en caractéristiques numériques. Le système fusionne ensuite ces caractéristiques image par image, en respectant le fait que les indices des mains et de la tête apparaissent simultanément dans la langue des signes. Un module temporel ultérieur analyse de nombreuses images pour comprendre le déroulement des signes dans le temps, et une couche récurrente produit une séquence d’unités de signe prédite, ou glosses.
Affiner la mémoire des signes du système
La reconnaissance de la langue des signes continue est difficile car les données d’entraînement sont limitées et les signes se confondent sans étiquettes précises image par image. Pour y remédier, les auteurs ajoutent un module d’amélioration des caractéristiques qui apporte une supervision supplémentaire pendant l’entraînement. Une technique largement utilisée aligne la séquence de glosses prédite avec la vidéo, produisant des positions probables de chaque gloss dans le temps. Le nouveau module prend ces suggestions d’alignement et les utilise comme supervision directe pour affiner la représentation interne des caractéristiques de gloss. En termes simples, le système apprend non seulement à produire la bonne séquence, mais aussi à construire des « mémoires » internes plus claires et plus cohérentes de l’apparence de chaque signe à travers différentes vidéos.
Évaluer l’approche
L’équipe évalue TS-CNN sur deux ensembles de données reconnus : RWTH-PHOENIX-Weather 2014 pour la langue des signes allemande et CSL Split II pour la langue des signes chinoise. Ils mesurent les performances à l’aide du taux d’erreur de mots, une métrique standard similaire à celle utilisée en reconnaissance vocale. Par rapport à un modèle de base ne prenant en compte que les mouvements des mains, l’ajout de l’information d’orientation de la tête réduit les erreurs d’environ 4 points de pourcentage sur les données allemandes et de 3–4 points sur les données chinoises. L’ajout du module d’amélioration des caractéristiques apporte des gains encore plus importants, réduisant les erreurs d’environ 10–14 % au total sur les deux ensembles. Le système fonctionne également de manière efficace, atteignant des vitesses en temps réel sur un processeur graphique moderne, ce qui est crucial pour une utilisation en interprétation en direct ou dans des outils mobiles. 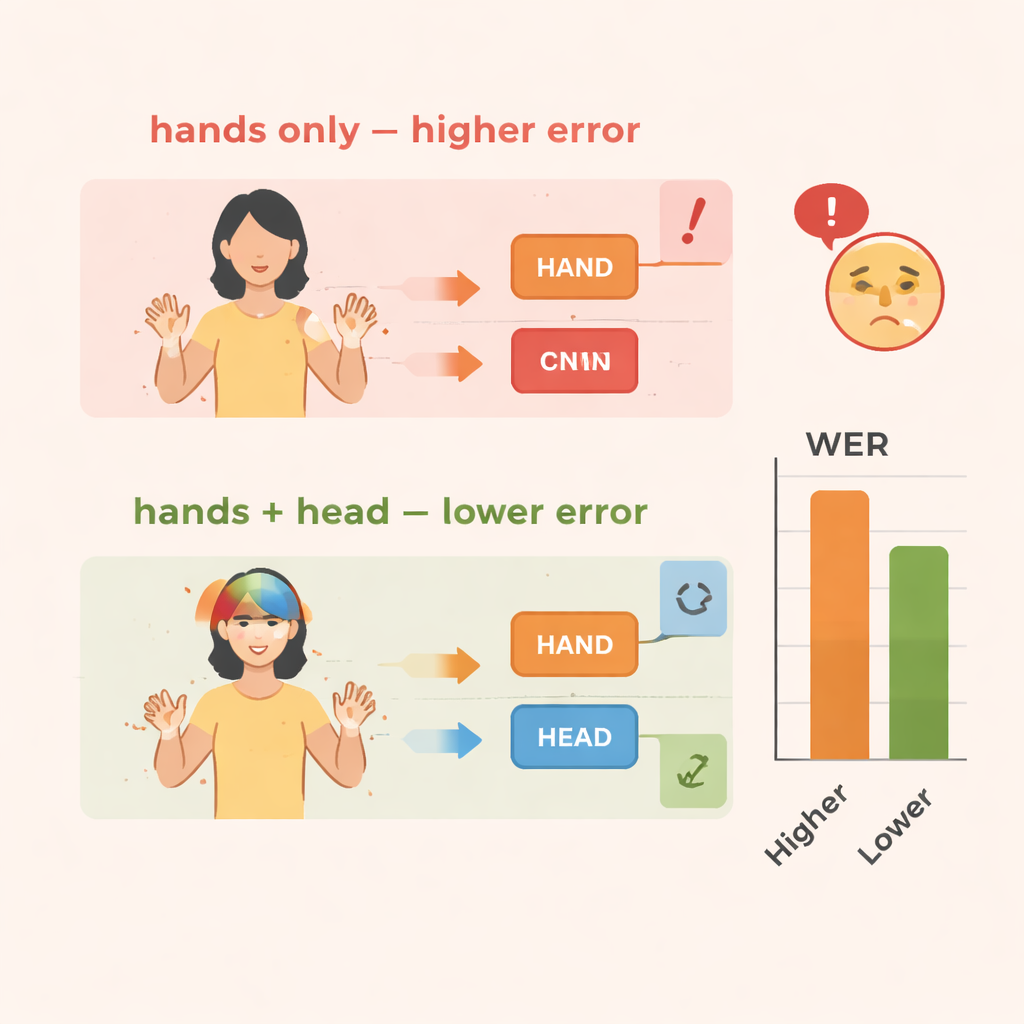
Ce que cela signifie pour la vie quotidienne
Concrètement, cette recherche montre que les ordinateurs peuvent mieux comprendre la langue des signes lorsqu’ils observent l’ensemble du signant, pas seulement les mains. En modélisant les mouvements de la tête et les indices faciaux parallèlement aux gestes des mains, et en raffinant soigneusement l’apprentissage à partir de données d’entraînement limitées, le cadre TS-CNN se rapproche de systèmes pratiques pouvant assister les personnes sourdes dans les classes, les hôpitaux et les administrations publiques. Pour des régions comme Ha’il, où les interprètes humains sont rares et où les projets technologiques sont encore émergents, un tel système pourrait à terme favoriser une communication plus inclusive — aidant à combler le fossé entre les signants et le monde entendant sans remplacer la richesse de l’expérience humaine du signe en elle‑même.
Citation: Harrouch, H., Guesmi, H., Alalfy, H. et al. A dual-stream deep learning framework for continuous sign language recognition to enhance communication accessibility in the Ha’il region. Sci Rep 16, 7070 (2026). https://doi.org/10.1038/s41598-026-38912-x
Mots-clés: reconnaissance de la langue des signes, apprentissage profond, accessibilité, vision par ordinateur, interaction homme‑machine