Clear Sky Science · fr
Une méthode de protection de la confidentialité des données pour les modèles de prévision des maladies infectieuses, équilibrant vitesse d’entraînement et précision
Pourquoi la protection des données de santé reste essentielle
Les hôpitaux et les agences de santé s’appuient désormais sur l’intelligence artificielle pour anticiper les flambées de grippe, de COVID-19 et d’autres infections plusieurs jours ou semaines à l’avance. Ces prévisions peuvent orienter les campagnes de vaccination, la gestion des effectifs et la planification d’urgence. Pourtant, les mêmes dossiers patients détaillés qui rendent les prévisions précises sont aussi extrêmement sensibles. Les lois et l’inquiétude du public empêchent souvent la mise en commun des données entre établissements, ce qui affaiblit l’efficacité de ces modèles. Cet article présente une méthode pour former des systèmes de prédiction des maladies infectieuses de haute qualité tout en gardant les données de chaque hôpital verrouillées sur place.
Apprendre à partir de nombreux hôpitaux sans partager les dossiers
Les auteurs s’appuient sur une technique appelée apprentissage fédéré, dans laquelle plusieurs hôpitaux entraînent conjointement un modèle de prédiction partagé. Plutôt que de copier des dossiers patients bruts vers un serveur central, chaque site entraîne le modèle localement et n’envoie que des mises à jour numériques des paramètres internes du modèle. Un serveur central agrège ces mises à jour et renvoie le modèle amélioré. Cette boucle se répète de nombreuses fois. En théorie, l’apprentissage fédéré protège la vie privée parce que les informations personnelles ne quittent jamais l’établissement. En pratique, cependant, des attaquants ingénieux peuvent parfois inférer des détails sur les données sous-jacentes à partir des mises à jour partagées, si bien qu’une protection supplémentaire est nécessaire. 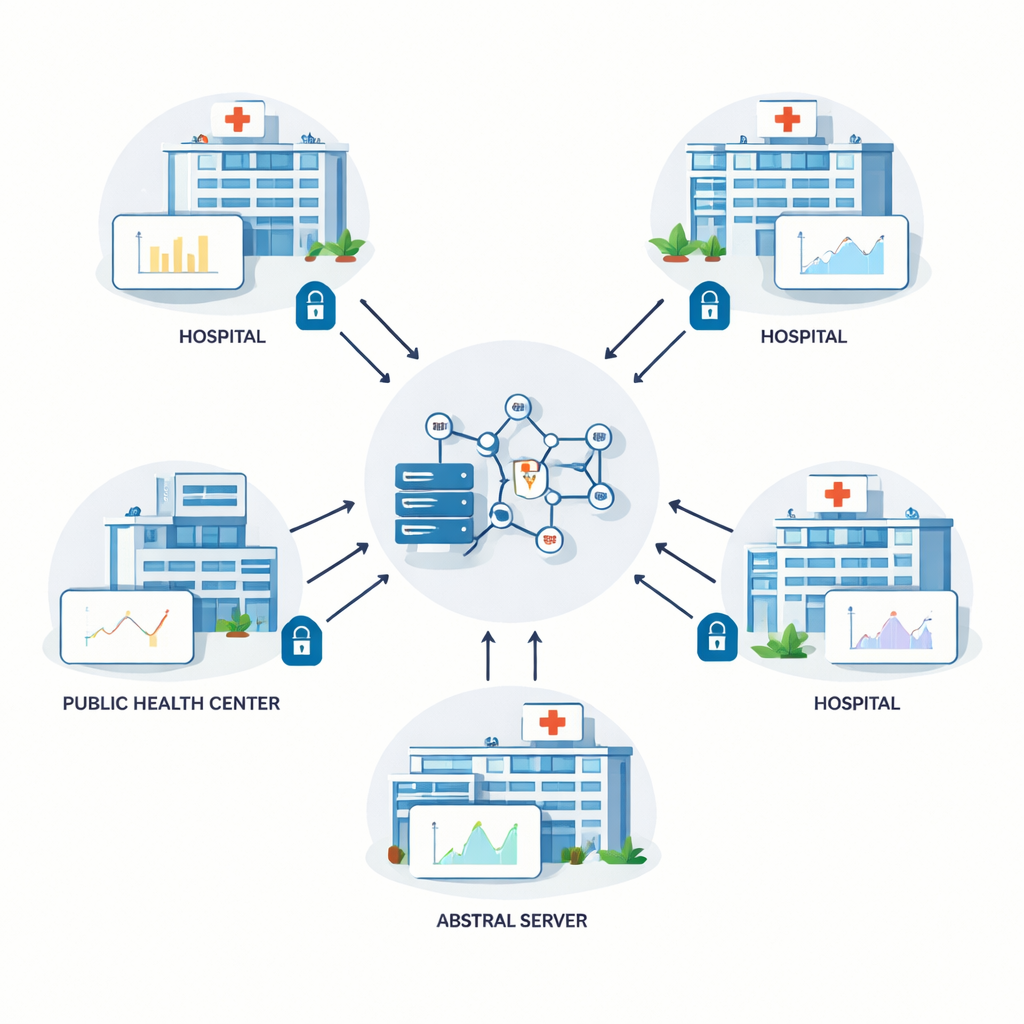
Verrouiller les valeurs avec un chiffrement intelligent
Pour renforcer la sécurité, l’équipe utilise le chiffrement homomorphe — une forme de verrou numérique qui permet d’effectuer des calculs directement sur des nombres chiffrés, sans jamais les voir en clair. Les schémas traditionnels de ce type sont très sûrs mais notoirement lents et gourmands en données, ce qui les rend difficiles à utiliser avec des modèles larges et complexes, comme ceux basés sur des réseaux LSTM (Long Short-Term Memory). Les chercheurs conçoivent un schéma hybride traitant différemment les différentes parties du modèle. Les composants les plus révélateurs sont protégés par une forme de chiffrement forte mais lourde, tandis que les parties moins sensibles reçoivent un verrou plus léger et plus rapide. De plus, un calendrier aléatoire pré-établi décide lors de quels tours d’entraînement les sites envoient effectivement des mises à jour chiffrées, leur permettant d’éviter des communications redondantes. Les tests montrent que cette combinaison accélère l’entraînement d’environ 25 % par rapport à l’utilisation du chiffrement lourd partout, tout en gardant les données protégées sous de solides hypothèses cryptographiques.
N’envoyer que les mises à jour qui comptent vraiment
Même avec un verrouillage plus intelligent, transférer chaque petite variation du modèle entre les institutions gaspille du temps et de la bande passante réseau. Les auteurs proposent donc une nouvelle règle d’entraînement appelée Data Selection–Distributed Selection Stochastic Gradient Descent (DS-DSSGD). Pendant l’entraînement, l’algorithme mesure l’ampleur de la variation de chaque partie du modèle d’un pas à l’autre. Seules les mises à jour dépassant un seuil prédéfini sont transmises ; les petites variations à faible impact sont simplement ignorées. Parallèlement, l’algorithme suit quelles observations de données sont responsables des changements les plus importants et les plus informatifs. Ces enregistrements influents sont rassemblés dans un jeu de données affiné utilisé pour une dernière phase d’entraînement. Des expérimentations sur trois ans de rapports d’infections réels de la ville de Yichang, combinés aux tendances locales de recherche web, montrent que le DS-DSSGD réduit le temps d’entraînement d’environ 10 % par rapport à plusieurs méthodes standard, sans perte significative de précision prédictive.
Une plateforme pratique pour une collaboration sécurisée
Les avancées techniques ne comptent que si les hôpitaux et les laboratoires peuvent réellement les utiliser. Pour combler cet écart, l’équipe intègre ses méthodes dans un environnement informatique réel appelé plateforme de calcul sécurisé Yi Shu Fang XDP. XDP gère l’ensemble du cycle de vie des données de santé, de la collecte et du nettoyage à l’analyse chiffrée et au partage des résultats. Elle prend en charge des outils familiers aux statisticiens, bioinformaticiens et cliniciens, et permet aux chercheurs d’institutions différentes de collaborer au sein d’un espace de travail contrôlé sans jamais télécharger de données brutes. Dans cette plateforme, le schéma de chiffrement hybride et l’algorithme DS-DSSGD fonctionnent comme des composants modulaires, transformant le cadre théorique en un système opérationnel. 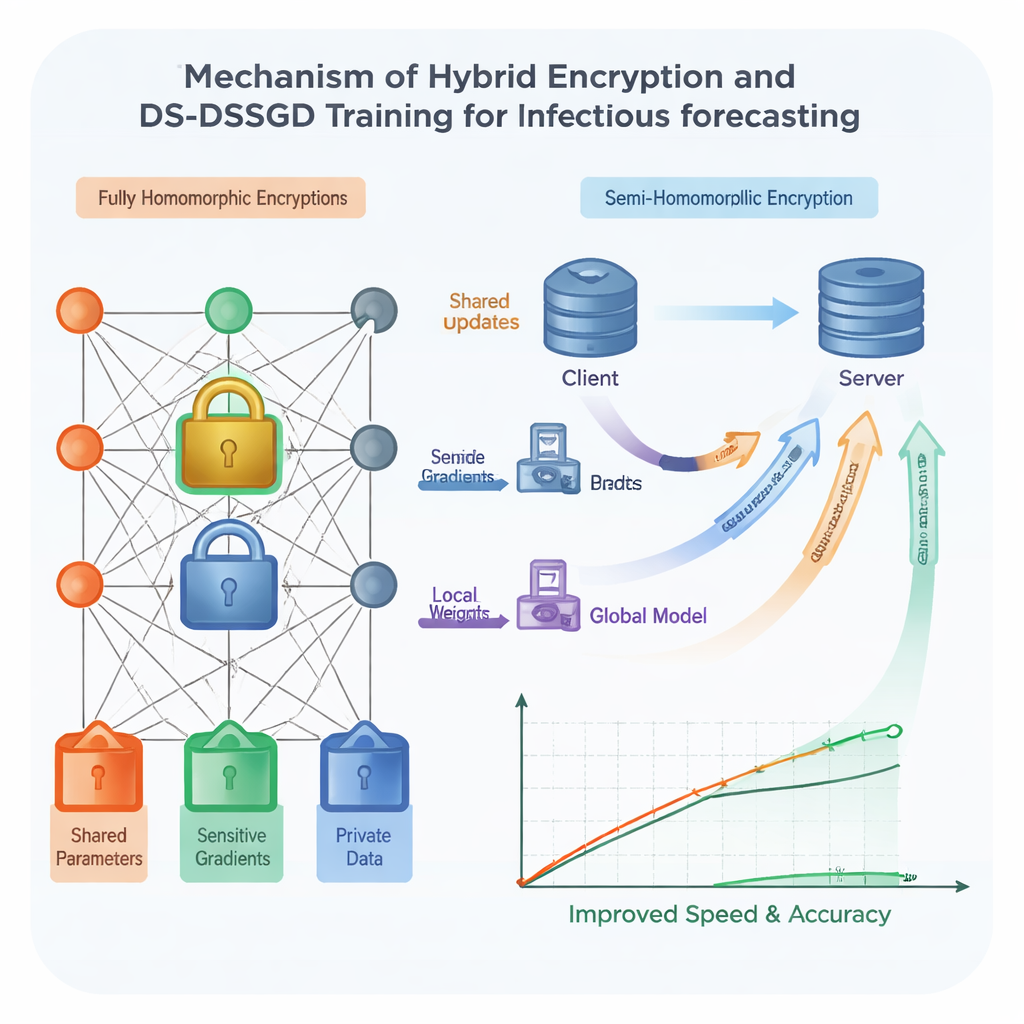
Ce que cela signifie pour la prévision des épidémies à venir
Concrètement, cette étude montre qu’il est possible de « concilier les deux » pour la prévision des maladies infectieuses : protéger la vie privée des patients tout en entraînant rapidement des modèles précis à partir de données provenant de nombreux établissements. En chiffrant différentes parties du modèle avec le niveau de sécurité adapté, en n’envoyant des mises à jour que lorsque c’est nécessaire et en encapsulant le tout dans une plateforme de collaboration sécurisée, les auteurs réduisent le coût de la confidentialité d’un fardeau paralysant à une surcharge gérable. Si ces approches étaient largement adoptées, elles pourraient permettre aux hôpitaux et aux agences de santé publique de mettre en commun leurs connaissances face à la prochaine épidémie sans jamais exposer des dossiers médicaux individuels.
Citation: Wang, X., Jiang, Y., Pan, G. et al. A data privacy protection method for infectious disease prediction models with balanced training speed and accuracy. Sci Rep 16, 7415 (2026). https://doi.org/10.1038/s41598-026-38906-9
Mots-clés: prévision des maladies infectieuses, confidentialité des données de santé, apprentissage fédéré, chiffrement homomorphe, apprentissage profond