Clear Sky Science · fr
Estimation de la prévalence et de la fréquence des espèces par des méthodes non supervisées
Pourquoi il est important de compter les espèces communes et rares
Quand nous imaginons la nature en danger, nous pensons souvent aux animaux rares au bord de l’extinction. Pourtant, la majeure partie du tissu vivant qui nous entoure est composée d’êtres très ordinaires qui sont soit très communs, soit en train de disparaître discrètement avant que personne ne s’en aperçoive. Savoir à quel point une espèce est réellement répandue sur un territoire donné est essentiel pour prévoir comment les écosystèmes réagiront à la pollution, à l’usage des terres ou au changement climatique. Cet article propose une méthode pour estimer simultanément la rareté ou la fréquence de nombreuses espèces en utilisant uniquement des relevés existants et des outils d’analyse modernes. L’objectif est de fournir des entrées plus objectives pour les modèles informatiques qui prédisent où les espèces peuvent vivre aujourd’hui et à l’avenir.
Des observations simples aux grandes questions écologiques
Les écologues utilisent couramment des modèles informatiques, appelés modèles de niche écologique, pour déterminer quels environnements conviennent à une espèce. Ces modèles aident à prévoir où une espèce pourrait apparaître sous des climats changeants ou dans de nouvelles régions. Un ingrédient crucial est la « prévalence » – en gros, la part des sites étudiés où une espèce est présente. Elle encode si une espèce est attendue comme commune ou rare avant de réaliser de nouvelles enquêtes. Cette attente préalable influence fortement la manière dont les modèles convertissent des scores de convenance en probabilités de présence et comment ils tracent la frontière entre « présente » et « absente » sur une carte. Si la prévalence est mal estimée, surtout pour les espèces rares, les prédictions peuvent être trompeuses et les plans de conservation risquent de cibler les mauvais lieux.
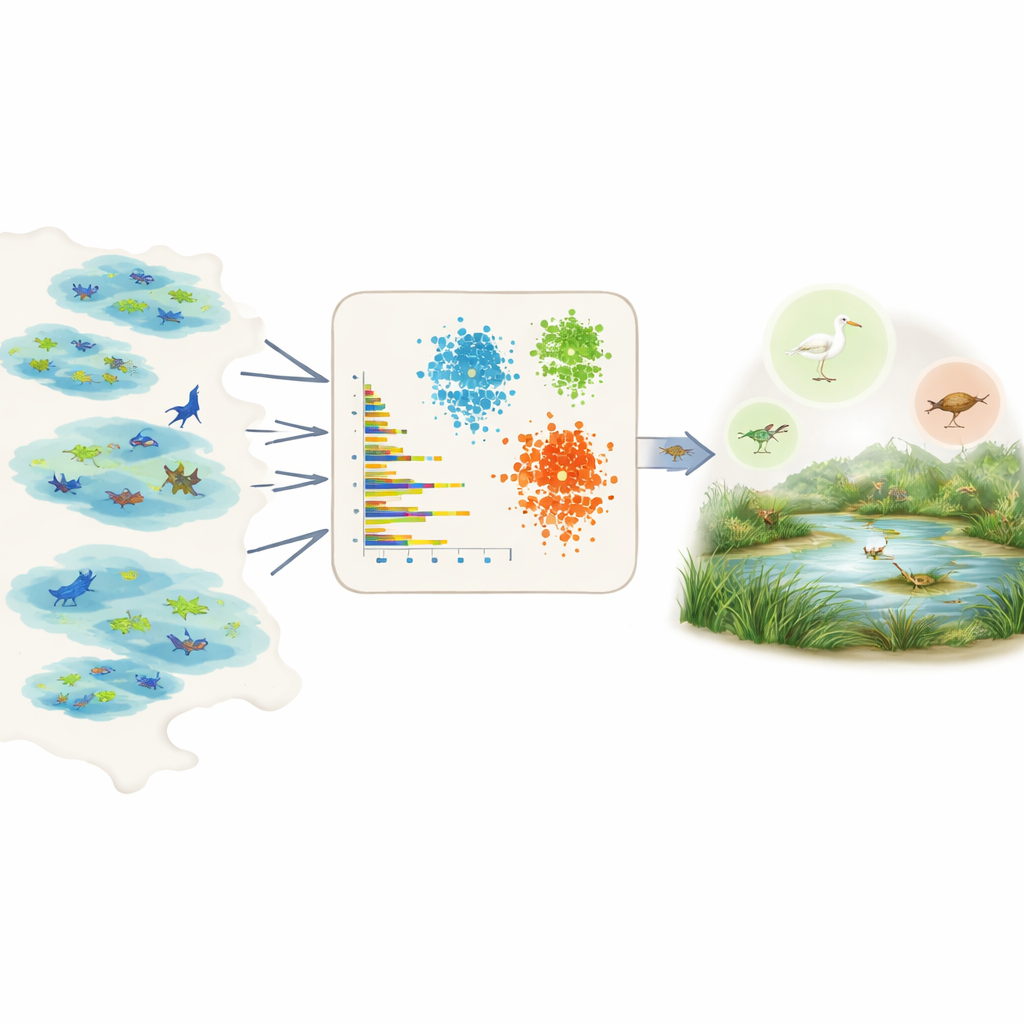
Laisser parler les données pour des centaines d’espèces
Mesurer directement la prévalence est difficile car les données de terrain sont fragmentaires et biaisées. Certaines zones sont fortement surveillées, certaines espèces sont plus faciles à observer, et beaucoup d’enregistrements proviennent de projets de science participative avec un effort inégal. Plutôt que de s’appuyer sur l’opinion d’experts ou sur des connaissances détaillées pour chaque espèce, les auteurs exploitent le Global Biodiversity Information Facility, une gigantesque base ouverte d’observations d’espèces. Pour chaque espèce d’une région choisie, ils résument les enregistrements bruts en quelques nombres simples et comparables : le nombre d’individus généralement signalés par observation, le nombre de jeux de données ou de zones humides où l’espèce apparaît, son étendue au sein de ces zones humides, et la fréquence d’observation dans le temps, y compris la fréquence des pics d’observations.
Apprendre aux machines à trier espèces communes et rares
Avec ces caractéristiques résumées en main, l’équipe applique trois outils d’apprentissage non supervisé – deux méthodes de regroupement et un modèle de deep learning connu sous le nom d’autoencodeur variationnel – qui recherchent des motifs sans être informés au préalable des espèces communes ou rares. Les méthodes de regroupement groupent les espèces partageant des similarités en abondance, répartition et fréquence d’observation. L’autoencodeur apprend à quoi ressemble un enregistrement d’espèce « typique » et signale les motifs inhabituels comme anomalies, lesquelles correspondent souvent à des espèces rares ou mal observées. Les modèles assignent ensuite chaque espèce à trois classes intuitives – très commune, assez commune ou rare – et convertissent ces classes en valeurs numériques de prévalence pouvant être directement utilisées comme probabilités a priori dans les modèles de niche écologique.
Tester l’approche dans une zone humide vulnérable
Pour évaluer la performance du cadre en pratique, les auteurs se concentrent sur le bassin du lac de Massaciuccoli en Toscane, Italie, une zone humide de faible altitude riche en oiseaux, poissons, insectes et autres animaux. Ce paysage est à la fois un hotspot de biodiversité et une destination touristique, mais il est aussi vulnérable au changement climatique, aux pénuries d’eau et à la pollution. Pour 161 espèces animales liées au lac, les modèles ont été entraînés avec des relevés provenant d’autres zones humides italiennes, puis sollicités pour inférer à quel point chaque espèce devrait être commune à Massaciuccoli. Deux experts locaux, ayant une connaissance approfondie du terrain, ont évalué indépendamment les mêmes espèces. En comparant les deux approches, le modèle de deep learning était d’accord avec l’avis combiné des experts pour environ 81–90 % des espèces, tandis que les méthodes de regroupement et un ensemble des trois modèles ont également bien performé.
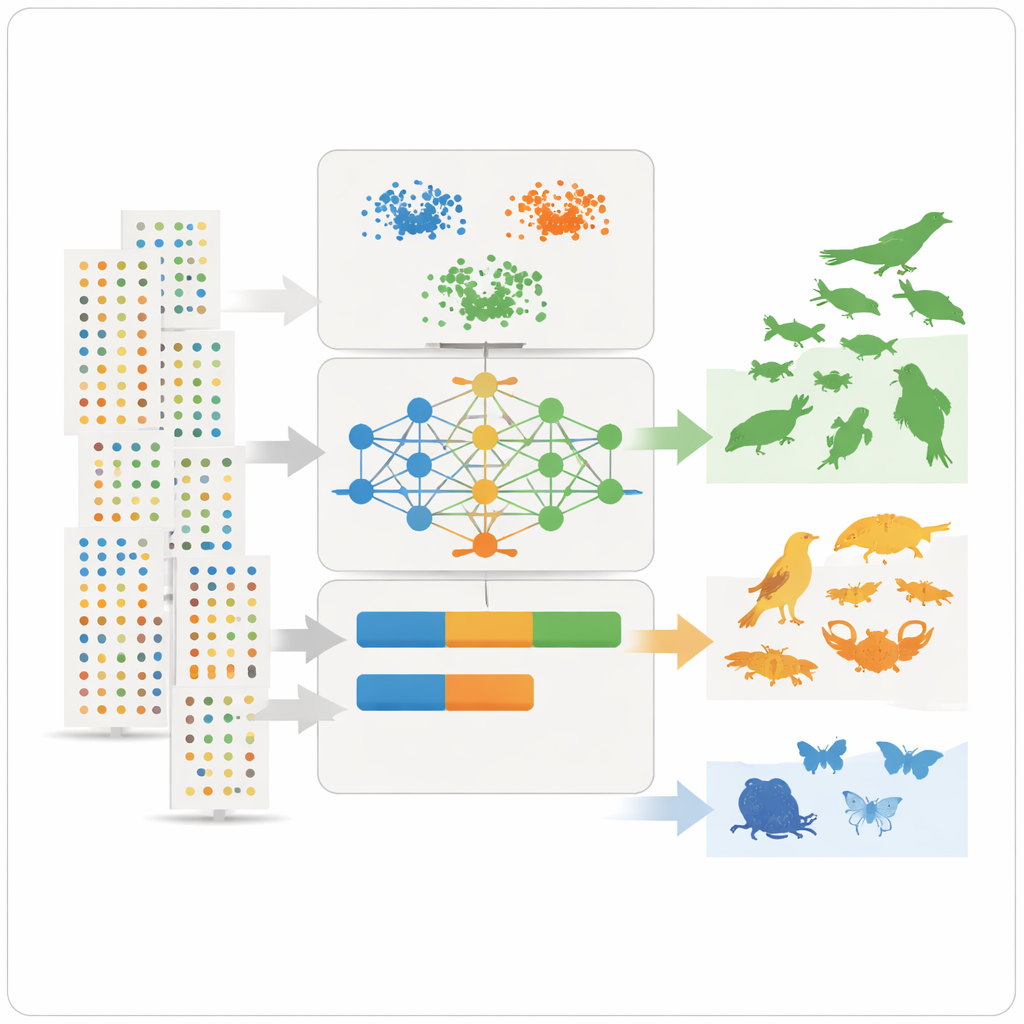
Tirer des leçons des désaccords et des biais cachés
Tous les cas ne concordaient pas parfaitement. Quelques espèces bien connues des experts comme abondantes autour du lac apparaissaient rares dans les données, souvent parce qu’elles sont furtives, sous-déclarées ou plus observées dans certaines zones humides que dans d’autres. Cela met en lumière une limite essentielle : les grandes bases de données reflètent où et comment les gens cherchent la nature, pas seulement où les espèces existent réellement. Une analyse de sensibilité a montré quelles caractéristiques importaient le plus pour les classifications, la moyenne des enregistrements par jeu de données, l’abondance par observation et la constance des observations au fil des années se révélant particulièrement informatives. Malgré les biais persistants, la méthode a produit des estimations de prévalence claires et reproductibles et peut être ajustée pour utiliser des classes plus fines ou plus larges selon les besoins de modélisation.
Ce que cela signifie pour les prévisions futures de la nature
Pour les non-spécialistes, le message principal est que nous pouvons désormais utiliser les données de biodiversité existantes de manière plus intelligente pour évaluer quelles espèces sont susceptibles d’être communes, moyennes ou rares dans un contexte donné, sans ajuster manuellement chaque cas. En transformant des relevés d’observations bruyants en estimations de prévalence transparentes et fondées sur les données, le cadre aide les modèles écologiques à produire des prédictions plus réalistes de la convenance des habitats et des tendances futures de la biodiversité. Cela peut, à son tour, soutenir une meilleure planification pour des zones humides comme Massaciuccoli et de nombreux autres écosystèmes à travers le monde, même lorsque les données de terrain sont incomplètes et que le temps des experts est limité.
Citation: Bove, P., Bertini, A. & Coro, G. Estimating species commonness and prevalence through unsupervised methods. Sci Rep 16, 8331 (2026). https://doi.org/10.1038/s41598-026-38900-1
Mots-clés: prévalence des espèces, modélisation de la biodiversité, écosystèmes de zones humides, écologie et apprentissage automatique, fréquence des espèces