Clear Sky Science · fr
Classification de textes de paroles basée sur des réseaux profonds hybrides adaptatifs en cascade et optimisés
Pourquoi des filtres de chansons plus intelligents sont importants
La musique entre presque en continu dans nos vies, et une grande partie de ce que nous écoutons est choisie par des algorithmes. Pourtant, beaucoup de ces systèmes peinent encore à répondre à une question simple : que disent exactement les paroles d’une chanson, et à qui sont-elles adaptées ? Cet article aborde ce problème en construisant un modèle avancé d’intelligence artificielle (IA) qui lit automatiquement les paroles et les classe selon l’humeur, le genre, le sentiment, et même le type d’interprète. L’objectif est d’aider à créer des listes de lecture plus sûres pour les enfants, des recommandations basées sur l’humeur plus précises et de meilleurs outils pour les chercheurs en musique.
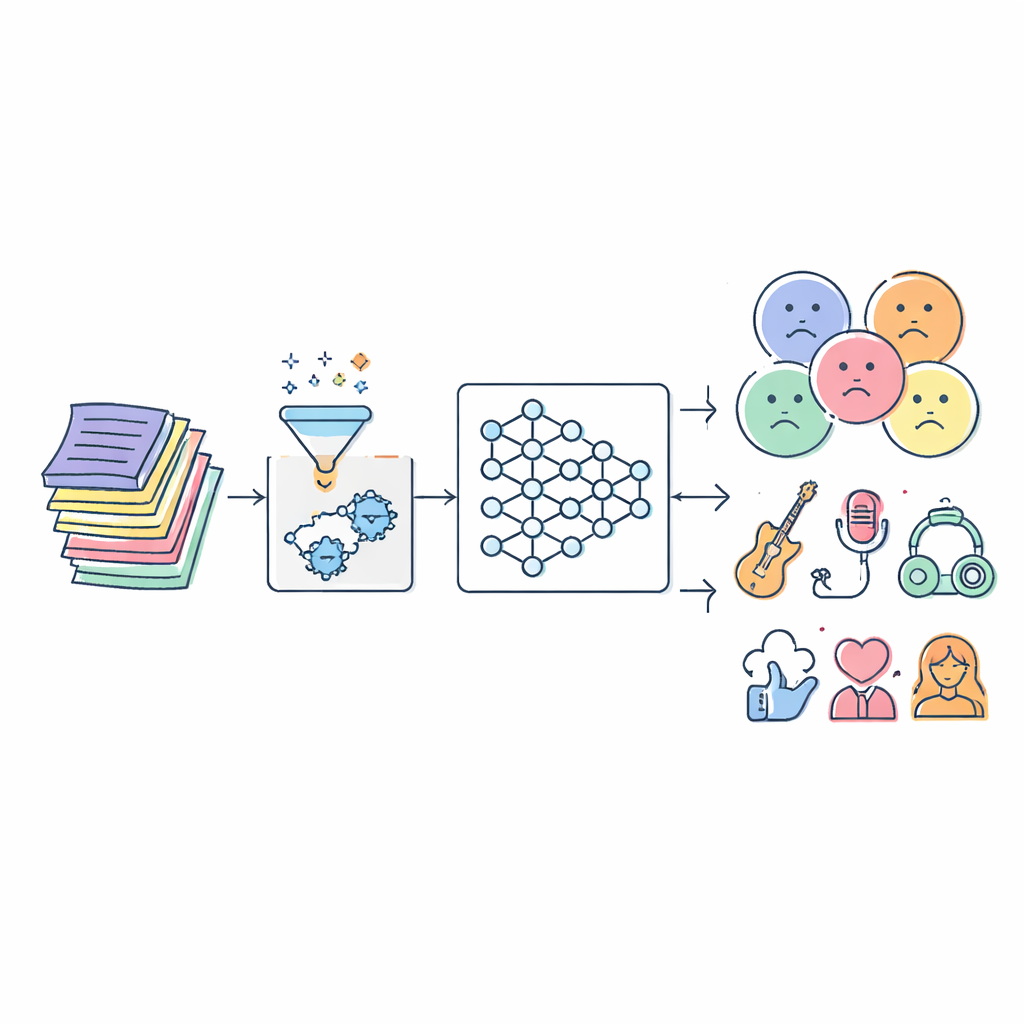
Le défi caché dans les mots des chansons
Les paroles sont bien plus complexes qu’une simple liste de mots offensants ou non. Une même phrase peut sembler tendre dans une chanson et menaçante dans une autre, et les auditeurs projettent leurs propres expériences sur ce qu’ils entendent. Les filtres traditionnels s’appuient généralement sur des listes statiques de termes offensants ou sur des techniques statistiques simples. Ces approches manquent de contexte, ne suivent pas l’évolution de l’argot et étiquettent souvent mal les chansons. Parallèlement, l’explosion de la musique numérique signifie qu’il y a des millions de titres à analyser, dans de nombreuses langues et styles, ce qui surcharge l’annotation manuelle et les anciens algorithmes.
Nettoyer les paroles brutes
Les auteurs commencent par rassembler de larges corpus de paroles provenant de trois jeux de données publics qui couvrent ensemble des centaines de milliers de chansons dans plusieurs genres et langues. Avant que l’IA puisse apprendre du texte, les paroles doivent être nettoyées. Le système supprime la ponctuation, les symboles spéciaux et les fragments répétés ou non pertinents, puis ramène les formes de mots apparentées à une racine commune (par exemple « singing », « sings » et « sang » deviennent « sing »). Cette étape de prétraitement élimine le bruit tout en conservant le sens, de sorte que les étapes suivantes puissent se concentrer sur le ton émotionnel et le sujet plutôt que sur des particularités de formatage ou des variations orthographiques.
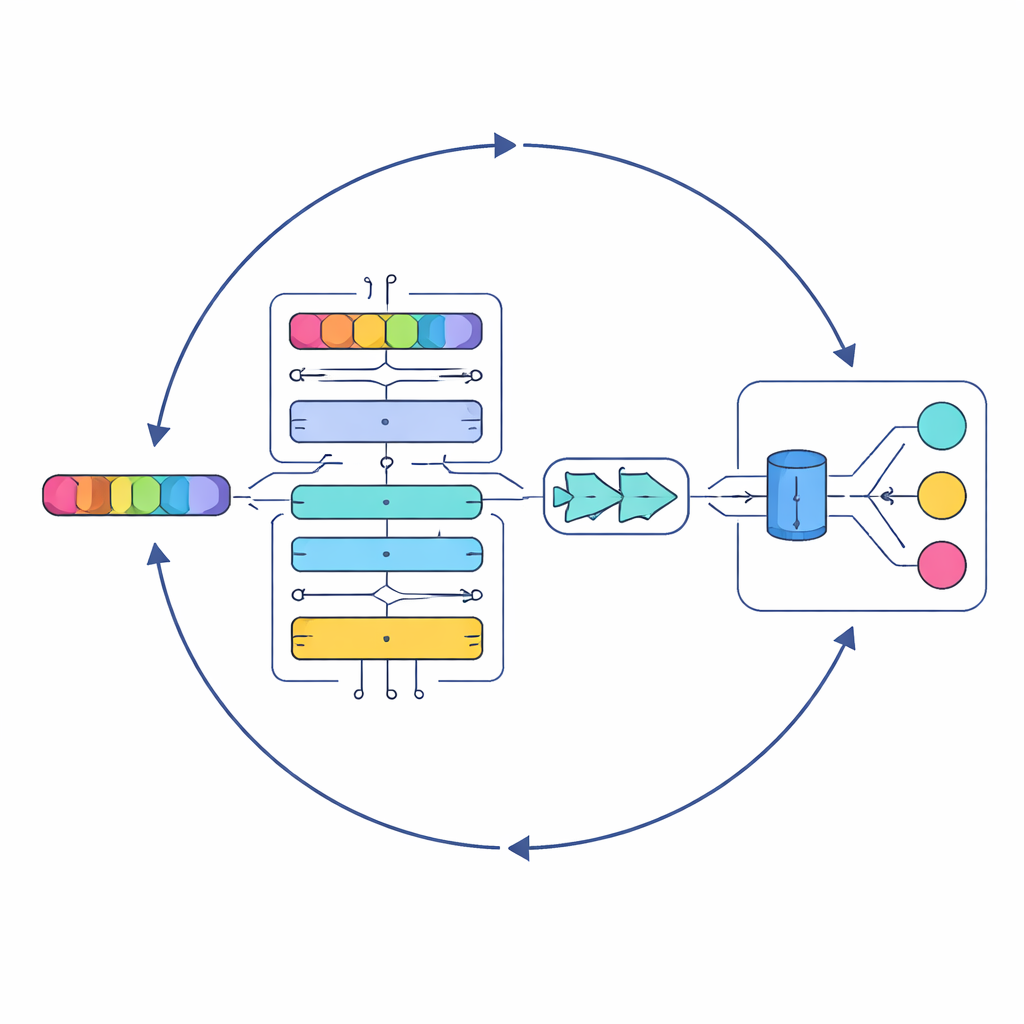
Une IA à étages qui lit comme un auditeur attentif
Au cœur de l’étude se trouve un nouveau modèle appelé Serial Cascaded Hybrid Adaptive Deep Network, ou SCHADNet. Il combine trois idées puissantes de l’IA linguistique moderne. D’abord, un encodeur basé sur les transformers capture les relations entre les mots sur l’ensemble d’une parole, pas seulement entre voisins immédiats. Ensuite, une couche Long Short-Term Memory bidirectionnelle lit la parole à la fois dans le sens direct et inverse, aidant le système à comprendre comment des lignes antérieures influencent le sens des suivantes. Enfin, une couche Gated Recurrent Unit affine ces informations en un résumé compact adapté à la prise de décision finale. Ensemble, ces composants fonctionnent comme une chorale de lecteurs spécialisés, chacun se concentrant sur des aspects différents du texte de la chanson.
Emprunter une stratégie à la mer
Empiler des couches d’apprentissage profond ne suffit pas ; leurs paramètres internes — par exemple le nombre de neurones ou la durée d’entraînement — influencent fortement les performances. Plutôt que d’ajuster ces choix manuellement, les auteurs ont recours à une approche d’optimisation inspirée des modes de chasse des prédateurs marins. Leur Improved Marine Predators Algorithm (IMPA) explore de nombreuses combinaisons de paramètres possibles, se concentrant progressivement sur celles qui donnent les meilleurs résultats. En supprimant des parties de l’algorithme d’origine qui n’étaient pas utiles dans ce contexte, ils améliorent la convergence, ce qui signifie que le système trouve de bonnes solutions plus rapidement et de manière plus fiable.
Quelle est la performance du système
Les chercheurs testent SCHADNet avec IMPA sur trois jeux de données de paroles différents et le comparent à une palette de méthodes établies, incluant des classificateurs classiques d’apprentissage automatique et plusieurs modèles populaires d’apprentissage profond tels que le LSTM simple, des systèmes uniquement basés sur transformers et des réseaux hybrides. Sur la précision, le rappel (combien de chansons réellement pertinentes sont trouvées) et d’autres mesures de qualité, la nouvelle approche arrive systématiquement en tête. Sur un grand corpus multilingue, elle classe correctement environ 93 % des chansons et obtient une valeur prédictive négative particulièrement élevée, ce qui signifie qu’elle reconnaît très bien les paroles qui ne relèvent pas d’une catégorie signalée — crucial pour éviter une censure excessive ou des étiquetages erronés.
Ce que cela signifie pour les auditeurs et les créateurs
Pour un non-spécialiste, le message est simple : les auteurs ont conçu un lecteur des paroles plus nuancé et plus fiable. Plutôt que de s’appuyer sur des listes grossières de mots, leur système examine des phrases entières, le contexte et les motifs présents dans de larges collections de musique, puis attribue automatiquement des étiquettes telles que l’humeur, le style ou l’adéquation pour un jeune public. Bien que le modèle soit complexe et gourmand en calcul, il ouvre la voie à des contrôles parentaux plus intelligents, des listes de lecture par humeur plus riches et de nouvelles façons d’étudier les tendances de la musique populaire. Les travaux futurs visent à réduire sa soif de données et à accélérer l’entraînement, mais même dans sa forme actuelle, SCHADNet annonce un avenir où les plateformes musicales comprennent les paroles presque aussi attentivement qu’un auditeur humain attentif.
Citation: Jasmine, R.L., Mukherjee, S., Robin, C.R.R. et al. Serial cascaded hybrid adaptive deep networks-based lyrics text classification using optimization approach. Sci Rep 16, 8527 (2026). https://doi.org/10.1038/s41598-026-38813-z
Mots-clés: recommandation musicale, analyse des paroles, classification de texte, apprentissage profond, modération de contenu