Clear Sky Science · fr
Améliorer la détection de la fraude aux abonnements par l’apprentissage ensembliste : le cas d’Ethio Telecom
Pourquoi la fraude téléphonique concerne tout le monde
Chaque fois que nous passons un appel, envoyons un SMS ou utilisons des données mobiles, nous faisons confiance au fait que la facture reflète notre consommation réelle. Mais des criminels peuvent exploiter les réseaux téléphoniques en ouvrant des lignes avec de fausses identités, en accumulant d’importantes charges impayées, et même en employant ces lignes pour d’autres délits. Cette étude se concentre sur Ethio Telecom, l’opérateur national éthiopien, et montre comment des méthodes avancées basées sur les données peuvent repérer les abonnements suspects bien plus précisément que les outils traditionnels, contribuant à maintenir des services téléphoniques abordables et sécurisés pour des millions d’utilisateurs.
Le coût caché des comptes téléphoniques fictifs
La fraude aux abonnements survient lorsqu’une personne souscrit à un service téléphonique avec des informations fausses ou volées sans intention de payer. À l’échelle mondiale, il s’agit d’une des formes les plus dommageables de fraude dans les télécoms, coûtant à l’industrie des dizaines de milliards de dollars par an. Pour Ethio Telecom à lui seul, on estime que la fraude vide près d’un milliard de dollars annuellement, les abonnements fictifs représentant environ 40 % de cette perte. Au‑delà des pertes de revenus, ces lignes peuvent être utilisées pour des escroqueries, la revente d’appels internationaux ou d’autres activités illicites, posant des risques tant pour les clients que pour la sécurité nationale.
Des règles faites main à l’apprentissage à partir des données
Comme beaucoup d’opérateurs, Ethio Telecom s’appuyait traditionnellement sur des experts qui établissaient des règles fixes pour signaler les comportements suspects — par exemple, bloquer une ligne après trop d’appels internationaux en peu de temps. Ces systèmes à base de règles sont faciles à comprendre mais peinent lorsque les fraudeurs changent de tactique ou lorsque les modèles d’utilisation sont complexes. Les auteurs soutiennent que le machine learning, qui apprend les motifs directement à partir des données historiques, peut réagir plus vite et avec plus de finesse. Plutôt que de dépendre d’un seul modèle, ils explorent des méthodes « ensemblistes » qui combinent plusieurs modèles, et des méthodes « adaptatives » qui se mettent à jour au fil de l’arrivée de nouvelles données.
Ce que les chercheurs ont construit à partir de vrais enregistrements d’appels
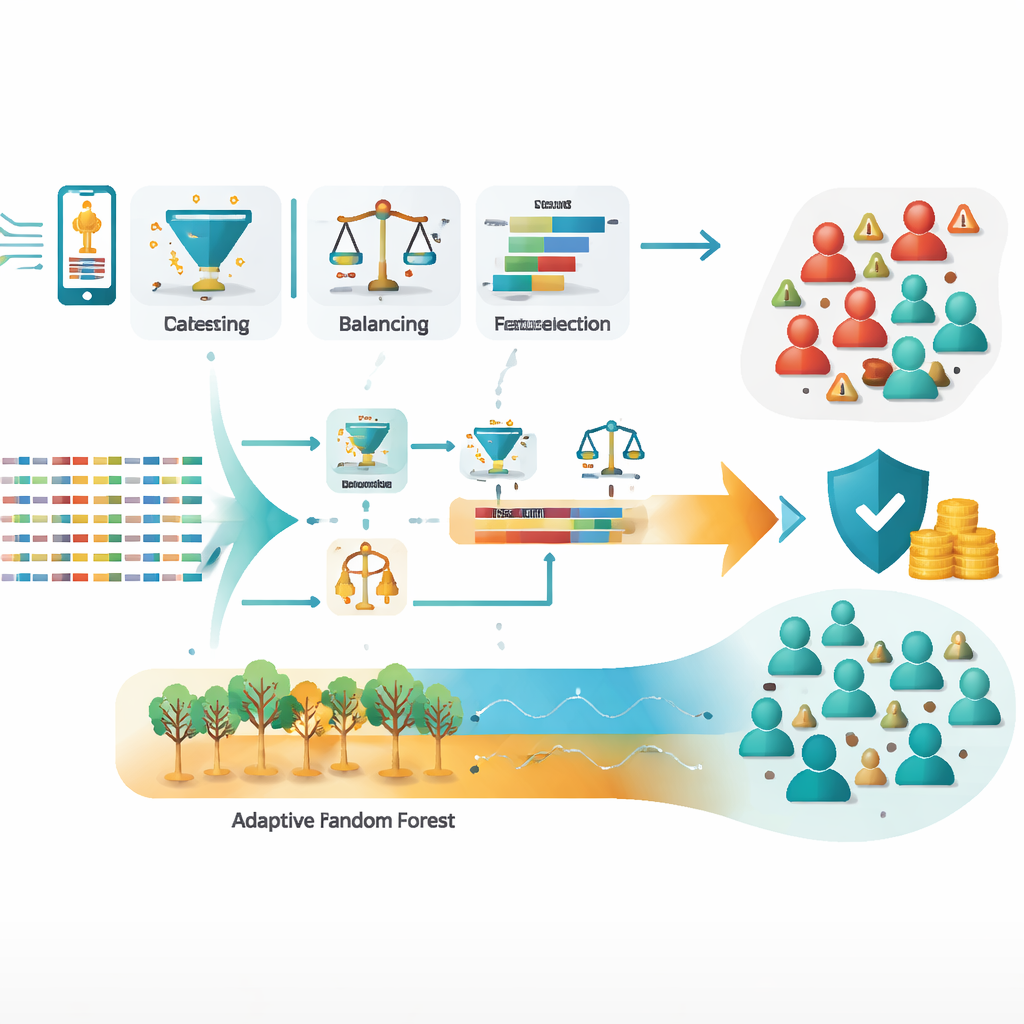
L’équipe a travaillé avec un large ensemble d’enregistrements de détail d’appels — journaux indiquant qui a appelé qui, combien de temps, et dans quelles conditions — sur une période de deux mois connue pour une forte activité frauduleuse. À partir d’environ un million d’enregistrements bruts, ils ont nettoyé les données, supprimé les erreurs et les doublons, équilibré des classes fortement déséquilibrées (beaucoup plus d’utilisateurs honnêtes que de fraudeurs), et conçu de nouvelles caractéristiques capturant mieux les comportements suspects. Parmi les mesures particulièrement importantes figuraient le nombre de numéros internationaux composés par un abonné, la part des appels internationaux sur l’ensemble des appels, et le ratio de numéros uniques contactés par rapport au nombre total d’appels. Ces signaux distillés distinguent souvent l’usage normal des abus organisés bien mieux que de simples comptes ou données démographiques.
Comment la combinaison de modèles améliore la détection
Les chercheurs ont testé trois modèles standards — arbres de décision, régression logistique et réseaux neuronaux artificiels — aux côtés de plusieurs stratégies ensemblistes telles que le bagging (Random Forest), le boosting (XGBoost), le vote et le stacking, ainsi que des modèles adaptatifs conçus pour des flux de données continus (Hoeffding Tree et Adaptive Random Forest). Après un réglage soigneux des paramètres de chaque modèle, l’approche de stacking, qui apprend à combiner les forces de plusieurs modèles de base, a atteint environ 99,3 % de précision sur des données non vues. La Adaptive Random Forest a été presque aussi performante, avec environ 99,2 % de précision, tout en étant capable de s’ajuster à l’évolution des schémas de fraude. Ces deux approches ont fortement réduit l’erreur la plus dangereuse — manquer une fraude réelle — comparées aux modèles individuels.
Suivre les astuces changeantes en temps réel
Puisque les fraudeurs modifient constamment leurs méthodes, un modèle statique peut rapidement devenir obsolète. Pour y remédier, les auteurs ont utilisé une technique de sélection de caractéristiques en ligne qui réévalue continuellement quels signaux sont les plus pertinents, sans avoir à reconstruire le système depuis zéro. Ils insistent également sur l’importance de la protection de la vie privée : tous les identifiants personnels dans les données ont été anonymisés avant l’analyse, et ils recommandent des contrôles d’accès stricts et des pistes d’audit. Pour un déploiement pratique, l’étude esquisse une architecture en temps réel dans laquelle de nouveaux enregistrements d’appels transitent via des outils comme Apache Kafka vers des modèles adaptatifs qui se mettent à jour à la volée tout en surveillant les changements brusques de comportement.
Ce que cela signifie pour les utilisateurs et les opérateurs
Concrètement, l’étude montre que laisser plusieurs modèles intelligents « voter » ensemble, et leur permettre d’apprendre en continu, peut détecter les abonnements fictifs avec une précision remarquable tout en maintenant les fausses alertes à un niveau gérable. Pour Ethio Telecom, cela pourrait se traduire par des économies substantielles, une tarification plus stable et une meilleure protection contre l’usage criminel du réseau. Pour les clients, cela signifie que des usages inhabituels mais légitimes sont moins susceptibles d’être pris pour de la fraude, tandis que les lignes réellement risquées sont détectées et fermées plus rapidement. Les auteurs concluent que l’apprentissage ensembliste et adaptatif, fondé sur des indicateurs choisis avec soin et adaptés au contexte, offre une feuille de route puissante et évolutive pour la détection moderne de la fraude dans les télécoms.
Citation: Desta, E.A., Azale, K.W., Hailu, A.A. et al. Enhancing subscription fraud detection through ensemble learning the case of Ethio telecom. Sci Rep 16, 7867 (2026). https://doi.org/10.1038/s41598-026-38790-3
Mots-clés: fraude dans les télécoms, fraude aux abonnements, apprentissage ensembliste, forêt aléatoire adaptative, enregistrements de détail d’appel