Clear Sky Science · fr
Prédiction précise et interprétable de la demande chimique en oxygène à l’aide d’algorithmes de boosting explicables avec analyse SHAP
Pourquoi surveiller l’oxygène d’une rivière est important
Les rivières sont l’élément vital des villes et des exploitations agricoles, mais lorsqu’elles se remplissent de matières organiques provenant d’usines, d’égouts ou de champs, l’eau peut manquer d’oxygène et devenir dangereuse pour les personnes et les écosystèmes. Un contrôle courant de l’état sanitaire des rivières est la « demande chimique en oxygène » (DQO), une mesure de la quantité d’oxygène nécessaire pour décomposer la pollution. La mesure de la DQO en laboratoire est lente et coûteuse, aussi cette étude examine-t-elle si des outils d’apprentissage automatique avancés mais explicables peuvent prédire de façon fiable la DQO à partir de données de capteurs routiniers — et montrer clairement ce qui cause la pollution. 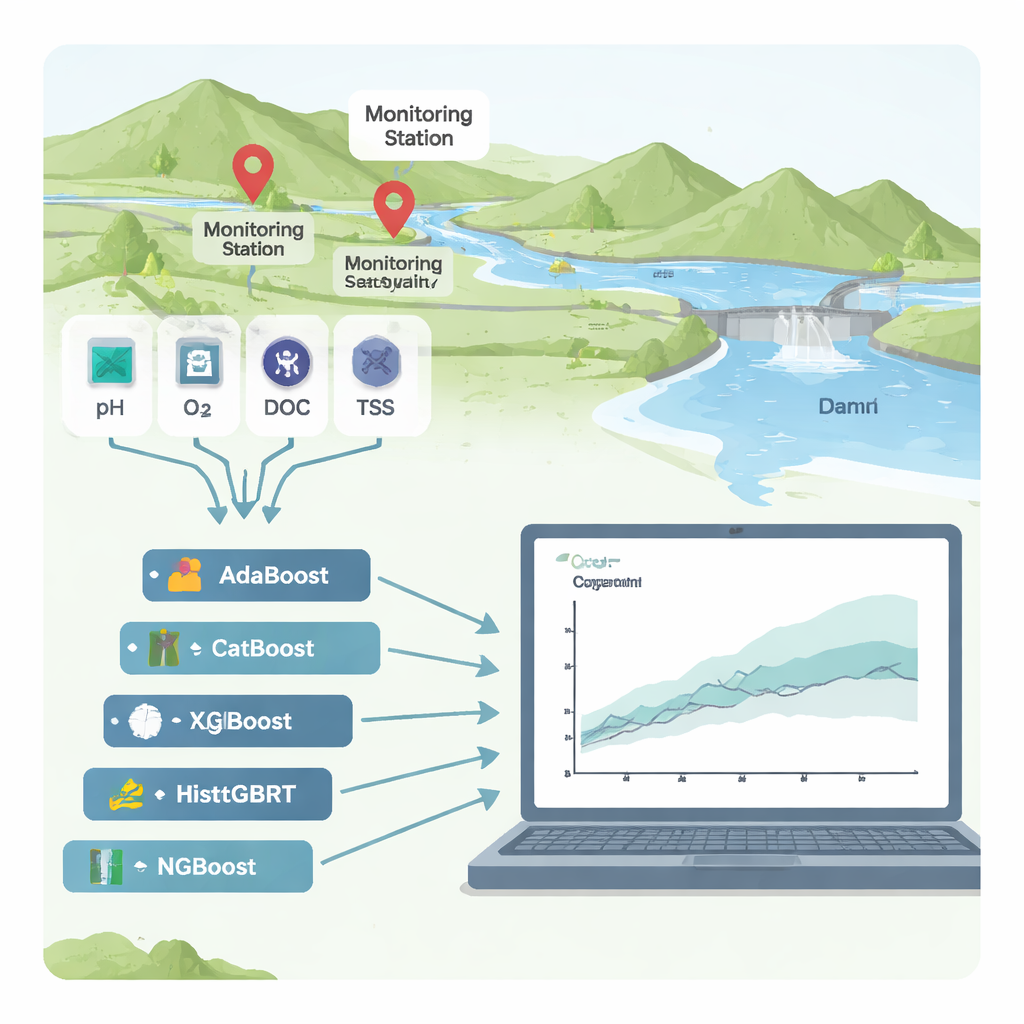
Des modèles intelligents pour un monde pollué
Les chercheurs se sont concentrés sur deux stations de surveillance des rivières en Corée du Sud, Hwangji et Toilchun, juste en amont du barrage polyvalent de Yeongju. À ces stations, des enregistrements pluriannuels existent pour des indicateurs courants de la qualité de l’eau : acidité (pH), oxygène dissous, matières en suspension (particules fines dans l’eau), nutriments tels que l’azote et le phosphore, carbone organique total (COT), demande biochimique en oxygène (DBO₅), température de l’eau, conductivité électrique et débit de la rivière. Plutôt que de construire un modèle traditionnel fondé sur la physique — qui peut être difficile à transférer d’une rivière à l’autre — ils ont testé six algorithmes de « boosting », une famille puissante de méthodes d’apprentissage automatique qui combinent de nombreux arbres de décision simples en un prédicteur performant.
Trouver le meilleur « prévisionniste » de rivière
Pour comparer les six méthodes de boosting (AdaBoost, CatBoost, XGBoost, LightGBM, HistGBRT et NGBoost), l’équipe a entraîné les modèles sur environ 70 % des données historiques et évalué les performances sur les 30 % restants. Ils ont jugé la précision à l’aide de plusieurs statistiques qui mesurent la proximité des prédictions par rapport aux mesures réelles de DQO et la capacité des modèles à généraliser à des conditions inédites. À la station de Toilchun, le modèle NGBoost — qui prédit non seulement une valeur unique mais une distribution de probabilité complète pour la DQO — s’est imposé nettement, capturant presque toute la variation de la DQO avec des erreurs très faibles. À Hwangji, site plus complexe, CatBoost a offert le meilleur compromis entre précision et stabilité. Certains modèles, en particulier XGBoost, paraissaient presque parfaits sur les données d’entraînement mais ont flanché sur les données de test, signe classique de « surapprentissage », où un modèle mémorise le bruit plutôt que d’apprendre des motifs réels.
Ouvrir la boîte noire de l’IA
Un objectif central de l’étude était non seulement de prédire la DQO, mais aussi d’expliquer pourquoi les modèles produisaient ces prédictions. Pour cela, les auteurs ont utilisé SHAP (Shapley Additive Explanations), une technique qui attribue à chaque variable d’entrée une contribution — positive ou négative — à chaque prédiction individuelle. Pour les deux rivières et pour la plupart des algorithmes, trois variables sont ressorties de façon cohérente comme principales déterminantes de la DQO : le carbone organique total (COT), la demande biochimique en oxygène (DBO₅) et les matières en suspension (MES). En termes simples, plus il y a de matière organique et de particules fines dans l’eau, plus la demande en oxygène est élevée. Les modèles ont aussi révélé des différences propres aux sites : à Toilchun, le débit et le phosphore total jouaient un rôle plus marqué, suggérant une influence plus forte de sources diffuses comme le ruissellement agricole ; à Hwangji, des schémas de conductivité et de matières en suspension laissaient entrevoir des sources plus localisées ou industrielles. 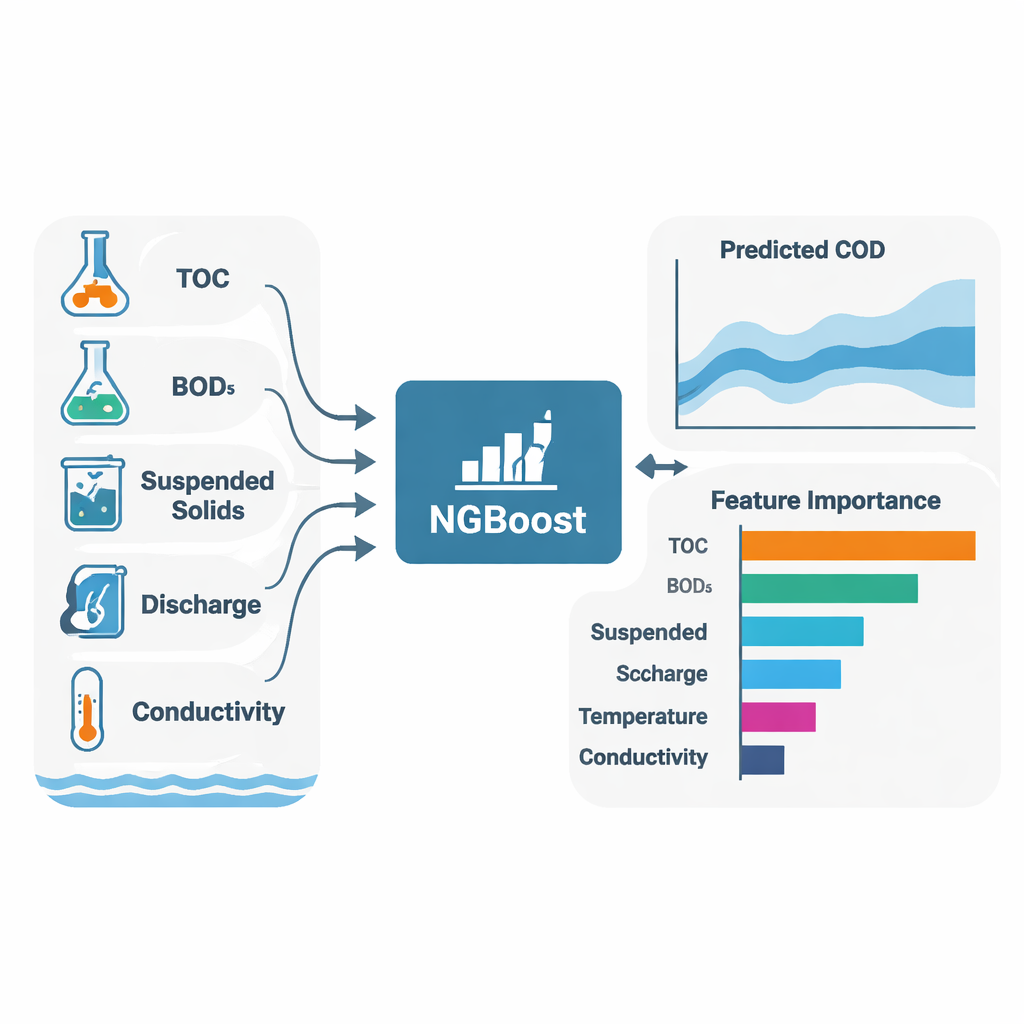
Ce que signifient les résultats pour les rivières réelles
Ces enseignements montrent que les modèles de boosting, associés à SHAP, peuvent dépasser le statut d’« boîte noire » opaque. Ils fournissent à la fois des prévisions nettes de la demande en oxygène des rivières et un récit physiquement cohérent sur les facteurs qui pilotent la pollution à chaque site. Cela a une importance pour les gestionnaires de barrages et de bassins fluviaux qui doivent prioriser ce qu’il faut surveiller et où intervenir : si le COT et la DBO₅ sont les leviers les plus puissants, contrôler les apports de déchets organiques permettra d’obtenir les améliorations les plus marquées de la qualité de l’eau. Les prévisions probabilistes de NGBoost offrent également une estimation de l’incertitude, cruciale pour les systèmes d’alerte précoce et les décisions fondées sur le risque. En bref, l’étude démontre qu’une IA explicable et conçue avec soin peut aider à protéger les réservoirs d’eau potable et la vie aquatique en transformant des relevés de capteurs routiniers en prédictions fiables et transparentes de l’état des rivières.
Citation: Merabet, K., Kim, S., Heddam, S. et al. Accurate and interpretable prediction of chemical oxygen demand using explainable boosting algorithms with SHAP analysis. Sci Rep 16, 6359 (2026). https://doi.org/10.1038/s41598-026-38757-4
Mots-clés: qualité de l’eau, demande chimique en oxygène, apprentissage automatique, pollution des rivières, IA explicable