Clear Sky Science · fr
Reconnaissance des expressions faciales via l'inférence variationnelle
Lire les émotions sur les visages
Nos visages diffusent en permanence ce que nous ressentons, mais ces signaux sont rarement simples. Un sourire peut masquer de la nervosité, et un regard « neutre » peut mêler ennui et irritation. Cette étude présente POSTER-Var, un nouveau système d’intelligence artificielle (IA) qui vise à lire ces émotions subtiles et mixtes de façon plus précise que les outils actuels de reconnaissance faciale, ce qui pourrait améliorer tout, de l’interaction homme‑machine au suivi de la santé mentale.
Pourquoi les émotions ne sont pas simplement allumées ou éteintes
La plupart des systèmes de reconnaissance d’expressions faciales existants traitent les émotions comme des cases distinctes et ordonnées : heureux, triste, en colère, etc. En réalité, la psychologie montre que les expressions sont des mélanges d’émotions de base, avec des intensités différentes qui coexistent sur un même visage. Les modèles d’IA traditionnels forcent généralement chaque image dans une seule étiquette stricte, ignorant l’incertitude et la nature continue et graduelle des sentiments. Cela les rend fragiles dans des contextes réels désordonnés, où l’éclairage, l’angle et même des annotations humaines incohérentes ajoutent du bruit. Les auteurs soutiennent que les systèmes futurs doivent reconnaître qu’un visage peut suggérer plusieurs émotions à différentes intensités, et que les ordinateurs devraient raisonner en termes de probabilités plutôt que de décisions oui/non.
Laisser le modèle embrasser l’incertitude
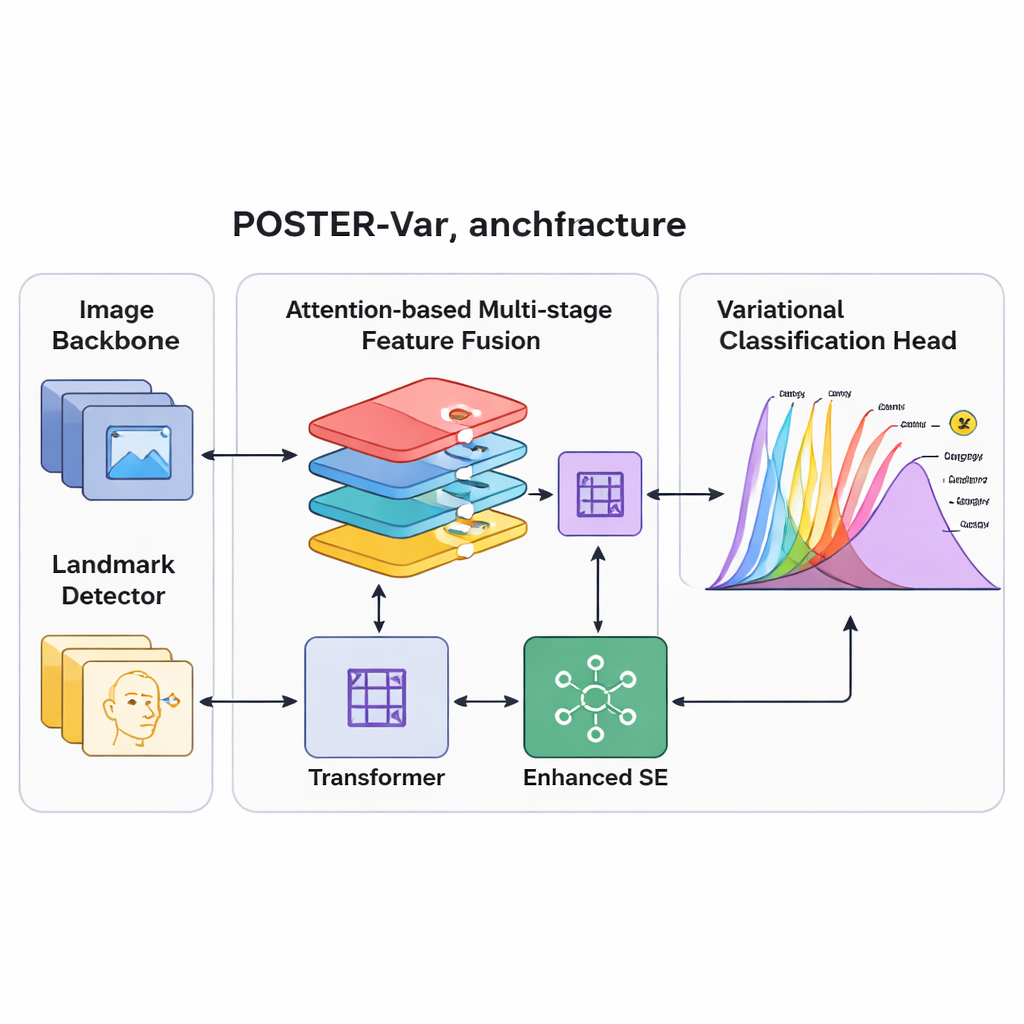
Pour mieux refléter cette réalité désordonnée, l’équipe s’appuie sur une technique de la modélisation probabiliste moderne appelée inférence variationnelle. Au lieu de produire un score unique et fixe pour chaque émotion, leur système POSTER-Var projette les caractéristiques faciales dans un « espace latent » où chaque émotion est représentée par une distribution de probabilité, généralement en forme de courbe en cloche. Pendant l’entraînement, le système prélève des échantillons de ces distributions apprises, l’encourageant à explorer une gamme d’interprétations possibles pour chaque visage. Au moment du test, il utilise cependant les centres de ces distributions pour donner des prédictions stables. De façon cruciale, POSTER-Var supprime les décodages supplémentaires et les couches entièrement connectées utilisées dans les conceptions variationnelles antérieures, traitant la représentation probabiliste elle‑même comme le signal décisionnel final. Cette « tête de classification basée sur l’inférence variationnelle », ou VICH, permet au modèle de quantifier l’incertitude tout en restant efficace et précis.
Voir le visage à plusieurs échelles
Reconnaître les expressions exige aussi d’examiner différentes parties du visage et différents niveaux de détail : la courbure de la bouche, la forme des yeux et la configuration générale comptent tous. POSTER-Var étend un système antérieur performant (POSTER++) en améliorant la façon dont ces caractéristiques multi‑échelles sont combinées. Il utilise plusieurs mécanismes d’attention pour fusionner l’information provenant d’un réseau de base d’image standard et d’un détecteur de repères faciaux, qui suit des points clés tels que les coins des yeux et les bords de la bouche. Un « embedding de couche » marque chaque carte de caractéristiques par sa position et son niveau sémantique dans la pyramide de traitement, aidant le réseau à savoir d’où proviennent les détails. Des transformations non linéaires et un bloc d’attention de canaux amélioré rééquilibrent ensuite ces caractéristiques, renforçant celles qui sont les plus informatives pour les expressions tout en supprimant les distractions comme le bruit de fond ou les particularités liées à l’identité.
Soumettre le système à l’épreuve
Les chercheurs ont évalué POSTER-Var sur trois jeux de données réels largement utilisés : RAF-DB, AffectNet et FER+. Ces collections comptent des centaines de milliers de visages capturés dans des conditions non contrôlées, chacun annoté avec l’une des émotions de base. Sur tous les bancs d’essai, POSTER-Var a égalé ou dépassé les méthodes de pointe actuelles. Par exemple, il a atteint environ 93 % de précision sur RAF-DB et près de 92 % sur FER+, et a légèrement amélioré les résultats sur les versions à 7 et 8 classes d’AffectNet. Des expériences d’ablation, où des composants individuels ont été retirés, ont montré que l’embedding de couche et la tête variationnelle contribuaient nettement aux performances, la composante variationnelle étant particulièrement utile sur des jeux de données plus difficiles et déséquilibrés. Des visualisations des cartes d’attention ont révélé que POSTER-Var se focalise sur des régions faciales plus larges et plus significatives que la référence, et des graphiques de ses distributions d’émotions apprises ont illustré comment il sépare mieux, par exemple, « triste » de « neutre » dans des cas ambigus.
Ce que cela signifie pour les applications réelles
Concrètement, POSTER-Var apprend aux machines à traiter les expressions faciales moins comme des feux de signalisation et plus comme des bulletins météorologiques : il peut y avoir une humeur principale « ensoleillée » avec des indices « nuageux » dispersés, et la prévision doit prendre en compte l’incertitude. En modélisant des distributions complètes sur les émotions plutôt qu’un seul pronostic, le système devient plus robuste aux annotations bruitées et aux expressions subtiles et mélangées. L’étude suggère que de telles approches probabilistes pourraient soutenir la prochaine génération de technologies sensibles aux affects, rendant les assistants virtuels, les robots sociaux et les outils de recherche comportementale plus à l’écoute de la vie émotionnelle complexe que nos visages ne révèlent que de façon imparfaite.
Citation: Lv, G., Zhang, J. & Tsoi, C. Facial expression recognition via variational inference. Sci Rep 16, 7323 (2026). https://doi.org/10.1038/s41598-026-38734-x
Mots-clés: reconnaissance des expressions faciales, IA des émotions, modélisation probabiliste, inférence variationnelle, vision par ordinateur