Clear Sky Science · fr
Récolter des enseignements : l’apprentissage automatique interprétable pour comprendre les facteurs environnementaux des rendements de maïs et de soja aux États-Unis
Pourquoi cela compte pour nos assiettes
Le maïs et le soja sont les piliers de l’agriculture américaine, nourrissant les populations et le bétail au pays et à l’étranger. Alors que le climat devient moins prévisible, agriculteurs et scientifiques s’efforcent de comprendre comment les vagues de chaleur, les variations des précipitations et les conditions pédologiques affecteront les récoltes. Cette étude montre comment des outils modernes d’apprentissage automatique, rendus plus transparents et interprétables, peuvent trier des montagnes de données agricoles et environnementales pour révéler quels facteurs météo et paysage déterminent le plus fortement les rendements de maïs et de soja dans les grandes régions de culture des États-Unis.
Observer de près de vraies parcelles
Plutôt que de s’appuyer sur des moyennes au niveau du comté, les chercheurs ont utilisé des données détaillées de « moniteurs de rendement » collectées par les moissonneuses‑batteuses lors de la récolte de 134 parcelles de maïs et de soja réparties dans neuf États entre 2007 et 2021. Chaque parcelle a été découpée en une fine grille de l’ordre d’un petit lot résidentiel, capturant la variation des rendements d’une zone à l’autre. Ils ont relié chaque cellule de la grille à des cartes publiques de météo quotidienne, de propriétés des sols et de caractéristiques du terrain comme la pente et l’altitude. Après nettoyage des erreurs, suppression des valeurs aberrantes et harmonisation à une résolution commune de 30 mètres, ils ont assemblé un grand jeu de données décrivant la performance de chaque petite parcelle sous sa combinaison unique de conditions.
Apprendre aux machines à prédire les récoltes
Avec ce jeu de données riche, l’équipe a testé plusieurs approches d’apprentissage automatique, y compris des méthodes modernes basées sur les arbres et des réseaux neuronaux, pour déterminer lesquelles prédisaient le mieux le rendement à partir des seules informations environnementales. En utilisant des outils automatisés pour sélectionner les meilleurs modèles et les variables les plus informatives, ils ont atteint une grande précision : pour le maïs, le modèle final expliquait environ 87 % de la variation des rendements ; pour le soja, environ 90 %. Ces modèles ont bien performé non seulement globalement, mais aussi lorsqu’ils ont été testés séparément par année et par État, ce qui suggère que les relations apprises se généralisent à différentes saisons et régions plutôt que de simplement mémoriser les données d’entraînement. Des tests spatiaux des erreurs restantes ont montré que la plupart des grandes tendances étaient capturées, avec seulement une certaine variation fine à l’intérieur des parcelles restant inexpliquée.
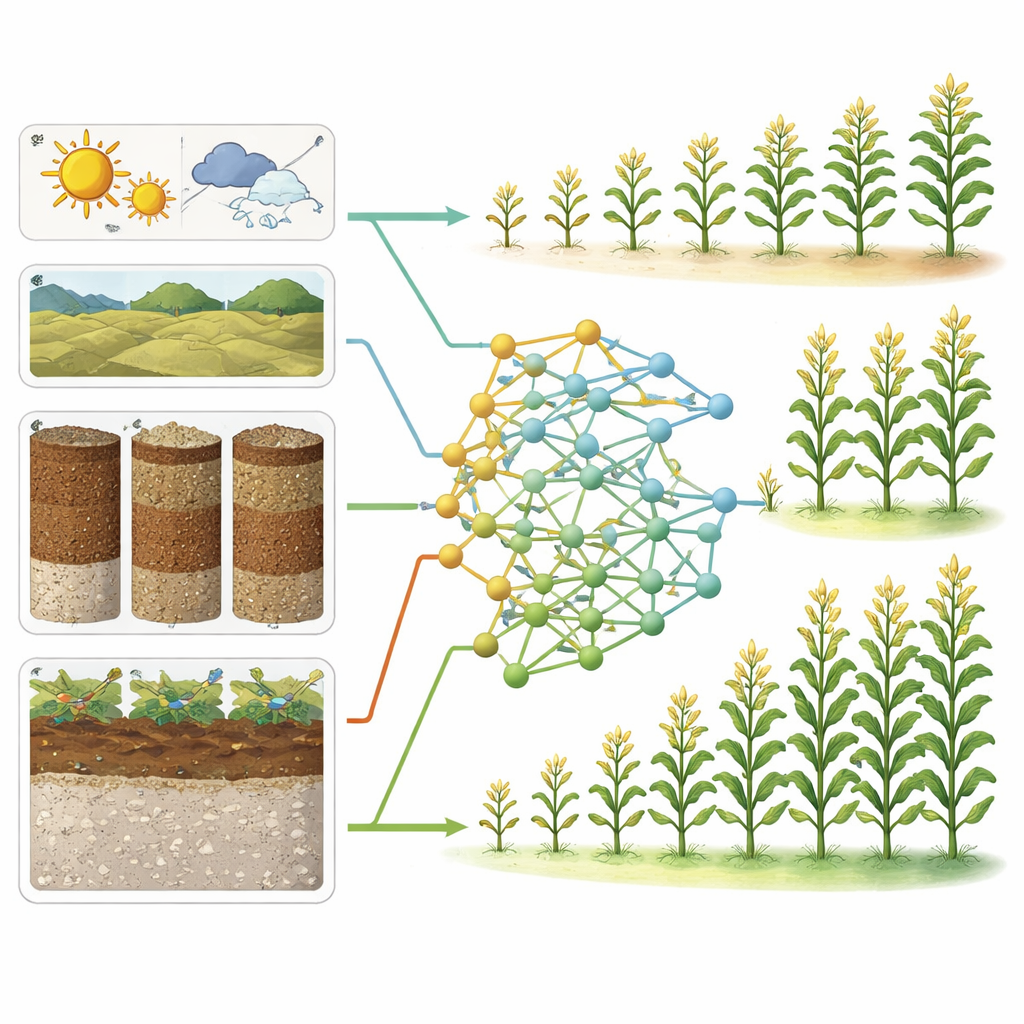
Ce qui détermine réellement les rendements de maïs et de soja
Pour ouvrir la « boîte noire » de l’apprentissage automatique, les auteurs ont utilisé des outils modernes d’interprétation connus sous le nom de valeurs SHAP et d’importance par permutation. Ces techniques révèlent quelles entrées comptent le plus et comment elles influencent les prédictions à la hausse ou à la baisse. Pour le maïs, la météo dominait nettement : les températures maximales quotidiennes durant la saison de croissance, l’ensoleillement et la variabilité quotidienne des précipitations figuraient parmi les principaux prédicteurs. Le modèle a indiqué un point de basculement net : lorsque les températures maximales quotidiennes dépassaient environ 36–38 °C (environ 97–100 °F), les rendements prédits de maïs commençaient à chuter fortement, rappelant des preuves expérimentales de stress thermique pendant des stades de croissance sensibles. En revanche, le modèle pour le soja s’appuyait davantage sur des caractéristiques du terrain et du sol comme la pente, l’altitude et des mesures liées à la capacité du sol à stocker l’eau, la pluviométrie du début de l’été jouant un rôle de soutien. Ensemble, ces signaux suggèrent que le rendement du maïs est particulièrement vulnérable aux extrêmes de chaleur et aux variations météorologiques, tandis que le rendement du soja est plus étroitement lié à la manière dont l’eau circule et est stockée dans le paysage.
Des motifs à la sélection et aux décisions agricoles
En identifiant les stress environnementaux qui affectent le plus les rendements, ce travail offre des orientations pratiques tant pour les sélectionneurs que pour les gestionnaires de parcelles. Pour le maïs, le seuil de chaleur identifié souligne la nécessité de variétés capables de maintenir la nouaison et le remplissage du grain lors de courtes mais intenses vagues de chaleur, ainsi que de stratégies de gestion comme l’irrigation ou l’ajustement des dates de semis dans les régions sujettes à des températures extrêmes. Pour le soja, la forte influence du terrain et du sol oriente vers la sélection de tolérances améliorées à la sécheresse et à l’excès d’eau, et vers des décisions au niveau parcellaire qui tirent parti de l’écoulement naturel, comme un drainage ciblé ou des pratiques de conservation qui améliorent la structure du sol. Bien que les modèles restent corrélationnels et ne puissent remplacer des expériences contrôlées, ils montrent comment l’apprentissage automatique interprétable, associé à des cartes environnementales largement disponibles et à des données de terrain, peut révéler des points de vulnérabilité cachés dans notre système alimentaire et aider à rendre la production américaine de cultures plus résiliente dans un climat plus chaud et moins prévisible.
Citation: Smith, H.W., Heffernan, C.J., Ashworth, A.J. et al. Harvesting insights: interpretable machine learning to understand environmental drivers of U.S. maize and soybean yield. Sci Rep 16, 8994 (2026). https://doi.org/10.1038/s41598-026-38724-z
Mots-clés: prévision du rendement des cultures, maïs, soja, apprentissage automatique, impacts climatiques