Clear Sky Science · fr
Évaluation des performances des grands modèles linguistiques aux examens de rhumatologie en persan : précision et raisonnement clinique de GPT-4o vs. GPT-5.1
Pourquoi c’est important pour les médecins et les patients
L’intelligence artificielle s’invite rapidement dans les amphithéâtres et les cabinets médicaux, mais la plupart des évaluations de ces outils portent sur l’anglais. Cette étude pose une question qui concerne des millions de locuteurs persans : dans quelle mesure des chatbots IA avancés, en l’occurrence GPT‑4o et GPT‑5.1, traitent-ils correctement des questions complexes de rhumatologie rédigées en persan ? La réponse aide les enseignants, les stagiaires et les patients à comprendre où ces outils peuvent soutenir l’apprentissage en toute sécurité et où l’expertise humaine reste indispensable.
Mettre l’IA à l’épreuve
Les chercheurs ont rassemblé 204 questions à choix multiple issues des examens officiels du conseil iranien de rhumatologie de 2023 et 2024, les mêmes épreuves que doivent réussir les spécialistes pour être certifiés. Après avoir éliminé sept questions défectueuses, 197 items ont été retenus. Chaque question, y compris les images ou graphiques accompagnants, a été saisie en persan dans GPT‑4o et GPT‑5.1 dans des conversations séparées et neuves. On a demandé aux modèles de choisir la meilleure réponse et d’expliquer leur raisonnement, reproduisant la façon dont un stagiaire pourrait interroger un outil d’IA pendant ses révisions.
Vérifier à la fois les réponses et le raisonnement
Les performances ont été évaluées de deux façons. D’abord, les options choisies par les modèles ont été comparées à la clé de réponses officielle, fournissant une mesure simple de justesse (bon ou faux). Ensuite, six rhumatologues certifiés ont évalué indépendamment la qualité de chaque explication sur une échelle de cinq points, allant d’un raisonnement manifestement erroné à un raisonnement complet et cliniquement solide. Les réponses de chaque modèle ont été notées par deux rhumatologues différents, aveugles les uns aux autres et à la clé officielle. Cela a permis aux chercheurs de mesurer non seulement si l’IA « devinait juste », mais aussi si sa logique ressemblait à celle des spécialistes.
Performance du modèle le plus récent
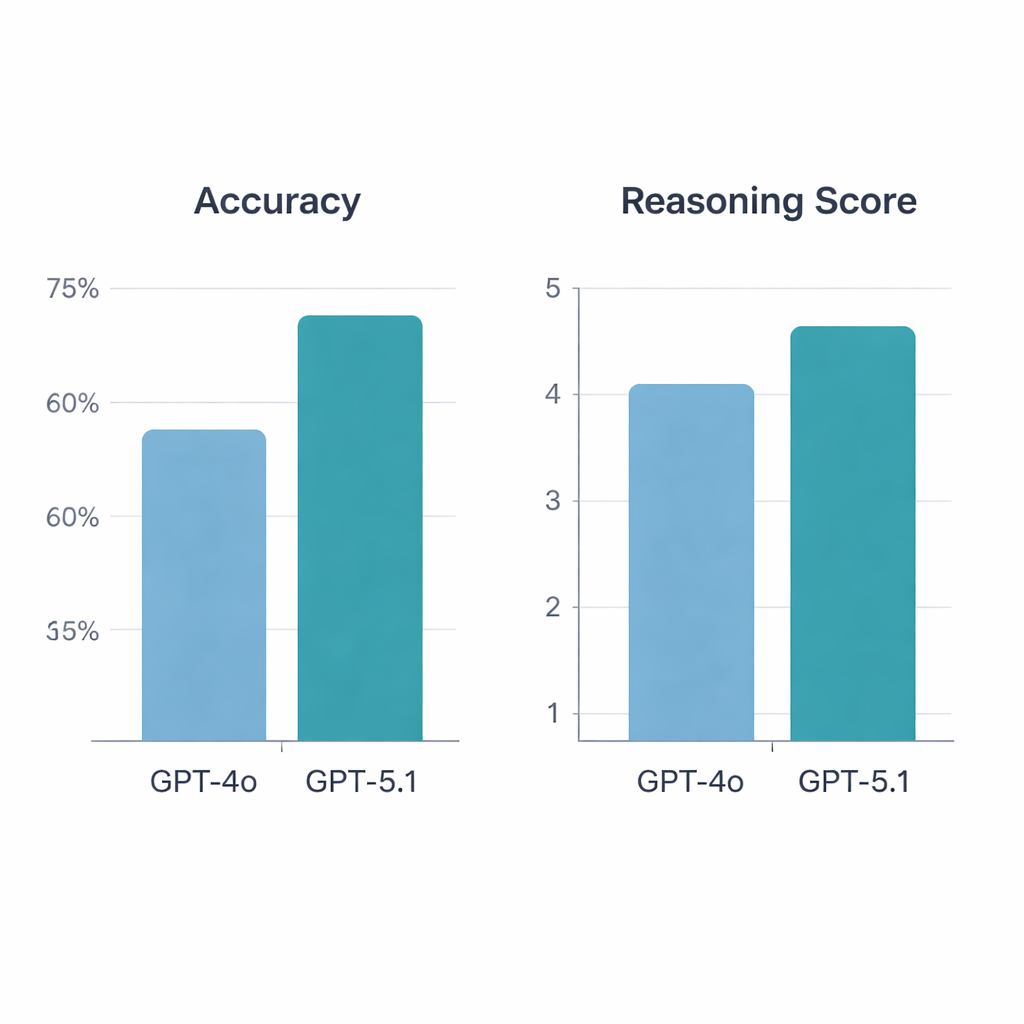
GPT‑5.1 a nettement surpassé GPT‑4o. Sur les 197 questions valides, GPT‑4o a répondu correctement à 64,5 % d’entre elles, tandis que GPT‑5.1 a atteint 76 % de bonnes réponses — une progression statistiquement significative. Les deux modèles ont obtenu 113 bonnes réponses et 34 mauvaises en commun, mais GPT‑5.1 a seul résolu 36 questions supplémentaires que GPT‑4o avait manquées ; GPT‑4o était uniquement correct sur seulement 13 questions. Lorsque les rhumatologues ont noté les explications, GPT‑5.1 est encore arrivé en tête, avec un score moyen de raisonnement de 4,47 sur 5 contre 4,13 pour GPT‑4o, et il a reçu davantage de notes maximales. Contrairement à GPT‑4o, dont la qualité de raisonnement variait selon que la question portait sur les sciences fondamentales, des vignettes cliniques, le diagnostic ou le traitement, GPT‑5.1 a maintenu une performance plus homogène à travers toutes les catégories.
Points forts, lacunes et désaccords humains
L’étude a mis en évidence des nuances importantes. Même lorsqu’un modèle donnait une mauvaise réponse finale, les spécialistes pouvaient parfois juger son raisonnement relativement cohérent, soulignant un écart entre la notation d’examen et la pensée clinique du monde réel. Parallèlement, l’accord entre les évaluateurs rhumatologues n’a été que modéré, ce qui souligne que les cliniciens eux‑mêmes divergent sur ce qui constitue un « bon raisonnement ». La langue semble aussi jouer un rôle : des travaux antérieurs en anglais et en espagnol ont rapporté des scores plus élevés pour des modèles similaires, suggérant que l’IA maîtrise encore mieux les grandes langues mondiales que le persan. Les auteurs insistent sur le fait que ces chatbots peuvent produire des explications convaincantes qui masquent des erreurs factuelles et que leurs performances peuvent évoluer au fil des mises à jour des systèmes.
Ce que cela implique pour l’avenir
Pour le grand public, le message est que la génération la plus récente de chatbots IA s’améliore pour traiter des examens médicaux spécialisés en persan, mais qu’elle n’est pas prête à se substituer à une formation rigoureuse ni au jugement d’experts. GPT‑5.1 peut être un compagnon d’étude utile pour les stagiaires en rhumatologie — résumant des sujets, déroulant des analyses de cas et offrant des explications structurées —, mais il ne doit pas être considéré comme la parole finale pour des décisions à fort enjeu concernant le diagnostic ou le traitement. Les auteurs appellent à des études plus larges et multilingues, à des tests répétés dans le temps et à des simulations cliniques réalistes pour déterminer comment ces outils peuvent être intégrés en toute sécurité à l’enseignement médical et, à terme, aux soins quotidiens des patients.
Citation: Rafiei, F., Sadeghipour, S., Sheikhalishahi, S. et al. Evaluation of large Language model performance on Persian rheumatology board exams: accuracy and clinical reasoning of GPT-4o vs. GPT-5.1. Sci Rep 16, 7274 (2026). https://doi.org/10.1038/s41598-026-38716-z
Mots-clés: rhumatologie, enseignement médical en persan, grands modèles de langage, raisonnement clinique, examens de certification