Clear Sky Science · fr
Réseau de fusion de caractéristiques multiniveaux guidé par l'entropie pour la recherche d'images par contenu à haute précision
Trouver la bonne image, rapidement
Chaque jour, nous créons et stockons un nombre stupéfiant de photos — des clichés médicaux et images satellite aux vidéos de surveillance et aux instantanés personnels. Étiqueter et rechercher ces images manuellement est lent et peu fiable. Cet article présente une manière plus intelligente pour les ordinateurs de « regarder » directement les images et de retrouver celles que nous voulons avec une grande précision, même dans des collections très vastes et hétérogènes.
Pourquoi regarder les pixels ne suffit pas
La recherche d'images traditionnelle s'appuie souvent sur les noms de fichiers ou des étiquettes simples comme « chat » ou « bâtiment ». Mais les gens n'étiquettent pas toujours les images avec soin, et les ordinateurs ne voient que des pixels bruts, pas la richesse des significations que les humains en déduisent. Les premiers systèmes basés sur le contenu ont tenté de combler ce fossé en utilisant des indices visuels simples comme la couleur, la texture et la forme. Ces indices ont aidé, mais ils étaient généralement combinés avec des niveaux d'importance fixes. Autrement dit, le système considérait certaines caractéristiques comme toujours plus importantes que d'autres, même si une recherche donnée bénéficierait d'un mélange différent. En conséquence, la précision diminuait lorsque le type d'image, l'éclairage ou la scène changeait.
Mélanger plusieurs manières de voir
Les auteurs proposent un nouveau cadre de recherche qui fusionne deux types principaux d'indices visuels. D'abord, il utilise des modèles d'apprentissage profond — des réseaux bien connus tels que ResNet50 et VGG16 — qui ont appris à reconnaître des motifs complexes dans les images. Ensuite, il ajoute des descripteurs « artisanaux » classiques qui capturent les distributions de couleur, les contours et les textures de manière plus contrôlée. Plutôt que de deviner à l'avance l'importance de chaque type de caractéristique, le système laisse les données en décider. Il mesure l'utilité de chaque caractéristique pour une recherche donnée et ajuste leur influence à la volée. Ce mélange multiniveau d'indices de haut niveau et de bas niveau aide l'ordinateur à former une compréhension plus riche et plus flexible du contenu d'une image.
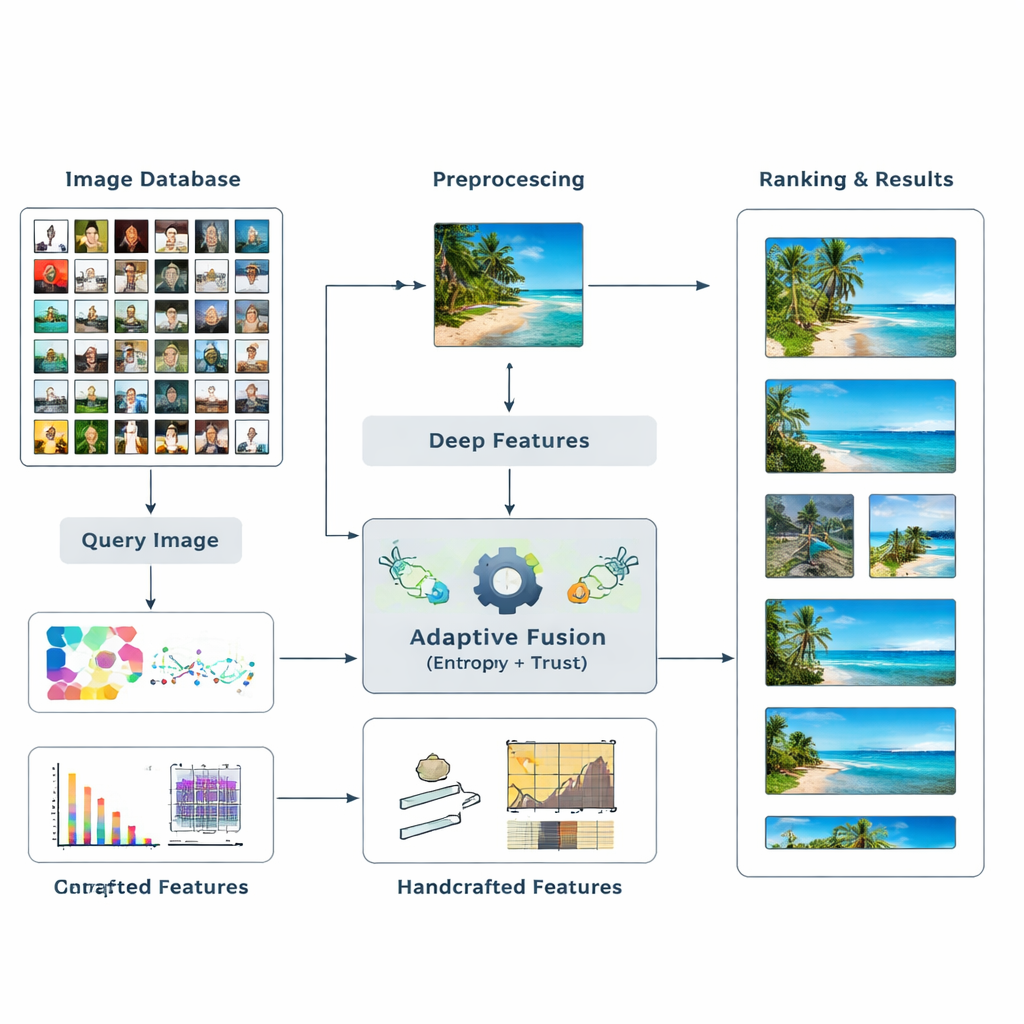
Laisser l'information et la confiance fixer les poids
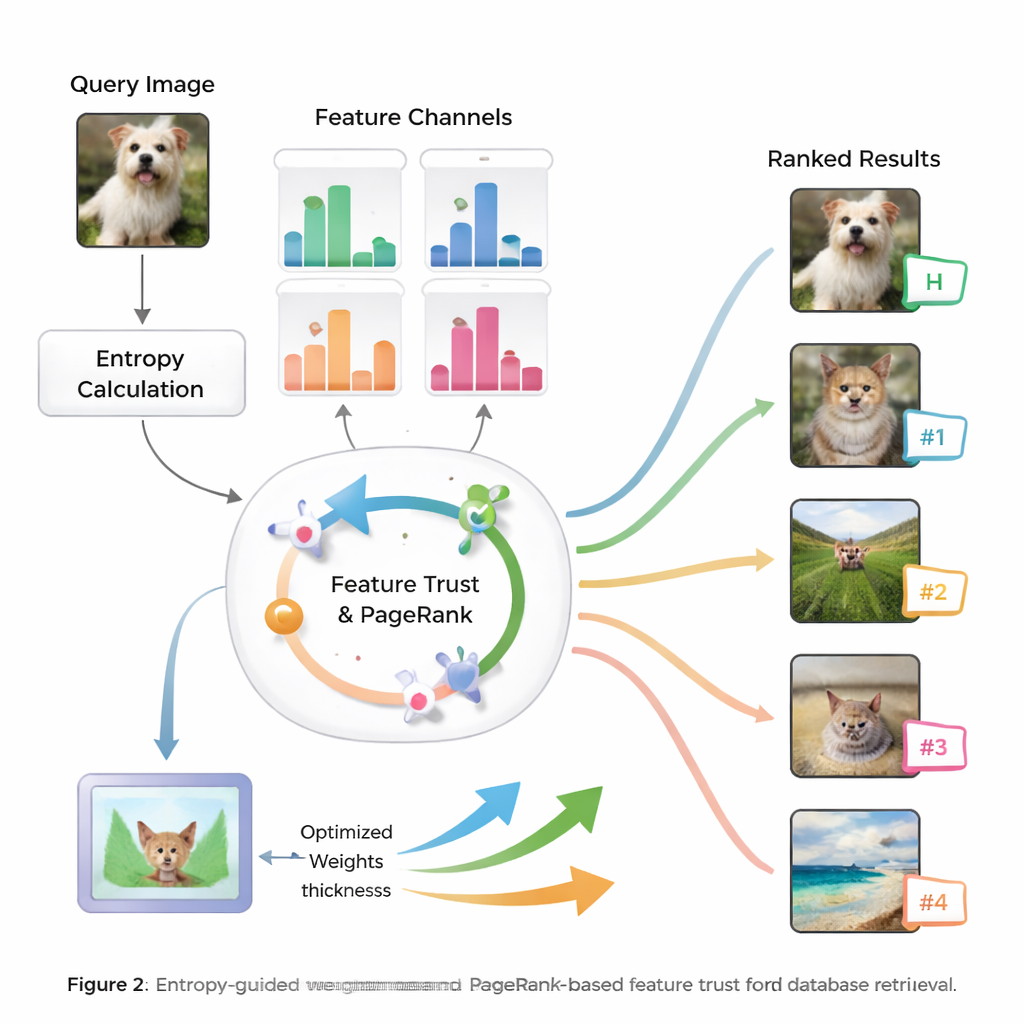
Au cœur de la méthode se trouve l'idée d'entropie, une mesure de l'incertitude ou de la dispersion de l'information. Les caractéristiques qui séparent de manière constante les images pertinentes des images non pertinentes ont une entropie plus faible et sont traitées comme plus « discriminantes ». Pour une nouvelle requête, le système évalue le comportement de chaque caractéristique à travers la base de données et lui attribue un score d'importance initial. Il examine ensuite la fiabilité des résultats de recherche de chaque caractéristique — si les meilleures correspondances ressemblent vraiment à la requête — construisant ainsi une notion de « confiance » pour chaque type d'indice. Ces scores de confiance sont intégrés dans un processus de type PageRank, semblable à la manière dont les premiers moteurs de recherche du web déterminaient l'importance des pages, afin d'affiner les poids des caractéristiques via un réseau de transfert probabiliste.
Des poids intelligents à de meilleurs classements
Une fois que le système a appris combien il faut faire confiance à chaque caractéristique pour la requête en cours, il combine leurs scores de similarité en une mesure globale pour chaque image de la base. Les images sont ensuite classées selon ce score global, de sorte que celles qui correspondent le mieux à la requête dans les sens les plus pertinents remontent en tête. Les auteurs testent leur approche sur des benchmarks d'images largement utilisés et la comparent à plusieurs méthodes existantes. Ils signalent des gains allant jusqu'à 8,6 % en moyenne de précision et des améliorations notables de la qualité des dix premiers résultats, tant en précision qu'en pertinence de l'ordre. Des tests statistiques montrent que ces améliorations sont peu susceptibles d'être dues au hasard, ce qui suggère que le système est à la fois précis et stable sur de nombreux types d'images.
Ce que cela signifie pour la recherche d'images au quotidien
En termes simples, cette recherche montre comment concevoir des moteurs de recherche d'images qui s'adaptent à chaque requête au lieu de s'appuyer sur des règles rigides. En laissant le contenu informationnel et la confiance acquise décider quels indices visuels importent le plus, le système peut retrouver plus souvent les bonnes images, que ce soit pour repérer une empreinte digitale dans une vaste base de données criminelle, localiser un bâtiment précis dans des photographies satellite ou afficher le bon examen médical. Les auteurs reconnaissent que la méthode est plus coûteuse en calcul que des systèmes plus simples, mais soutiennent que sa fiabilité et sa précision supérieures la rendent bien adaptée aux grands référentiels d'images critiques où trouver la bonne image est essentiel.
Citation: Lavanya, M., Vennira Selvi, G., Gopi, R. et al. Entropy guided multi level feature fusion network for high precision content based image retrieval. Sci Rep 16, 7449 (2026). https://doi.org/10.1038/s41598-026-38699-x
Mots-clés: recherche d'images basée sur le contenu, apprentissage profond, fusion de caractéristiques, recherche d'images, pondération par entropie