Clear Sky Science · fr
Pré-entraînement sur ImageNet et apprentissage par transfert en deux étapes pour la classification d’images de chromosomes
Des vues plus nettes de nos chromosomes
Nos chromosomes contiennent les instructions pour construire et faire fonctionner notre organisme, et les médecins étudient leur forme pour détecter des troubles génétiques et certains cancers. Aujourd’hui, les ordinateurs peuvent aider à lire des images de chromosomes, mais apprendre à le faire correctement est difficile parce que les images médicales sont rares et très différentes des photos du quotidien. Cette étude pose une question simple aux implications pratiques importantes : les ordinateurs apprennent-ils mieux à partir d’images médicales apparentées, et pas seulement à partir d’immenses collections de photos de chats, chiens ou voitures ?
Pourquoi les images de chromosomes comptent
À l’hôpital, des spécialistes disposent les 46 chromosomes d’une personne dans un tableau appelé caryotype, regroupés en 24 types (22 paires numérotées plus X et Y). De subtils bandes claires et foncées le long de chaque chromosome aident à révéler des pièces manquantes ou supplémentaires liées à des affections comme la trisomie 21 ou certaines leucémies. Traditionnellement, les experts classent ces bandes à l’œil, ce qui est lent et subjectif. L’apprentissage profond propose d’automatiser ce travail, mais ces systèmes partent généralement de modèles entraînés sur ImageNet, un jeu de données massif d’images ordinaires. Ce saut — des photos de vacances aux vues microscopiques des chromosomes — est énorme, et on ne sait pas clairement dans quelle mesure cette expérience est transferable.
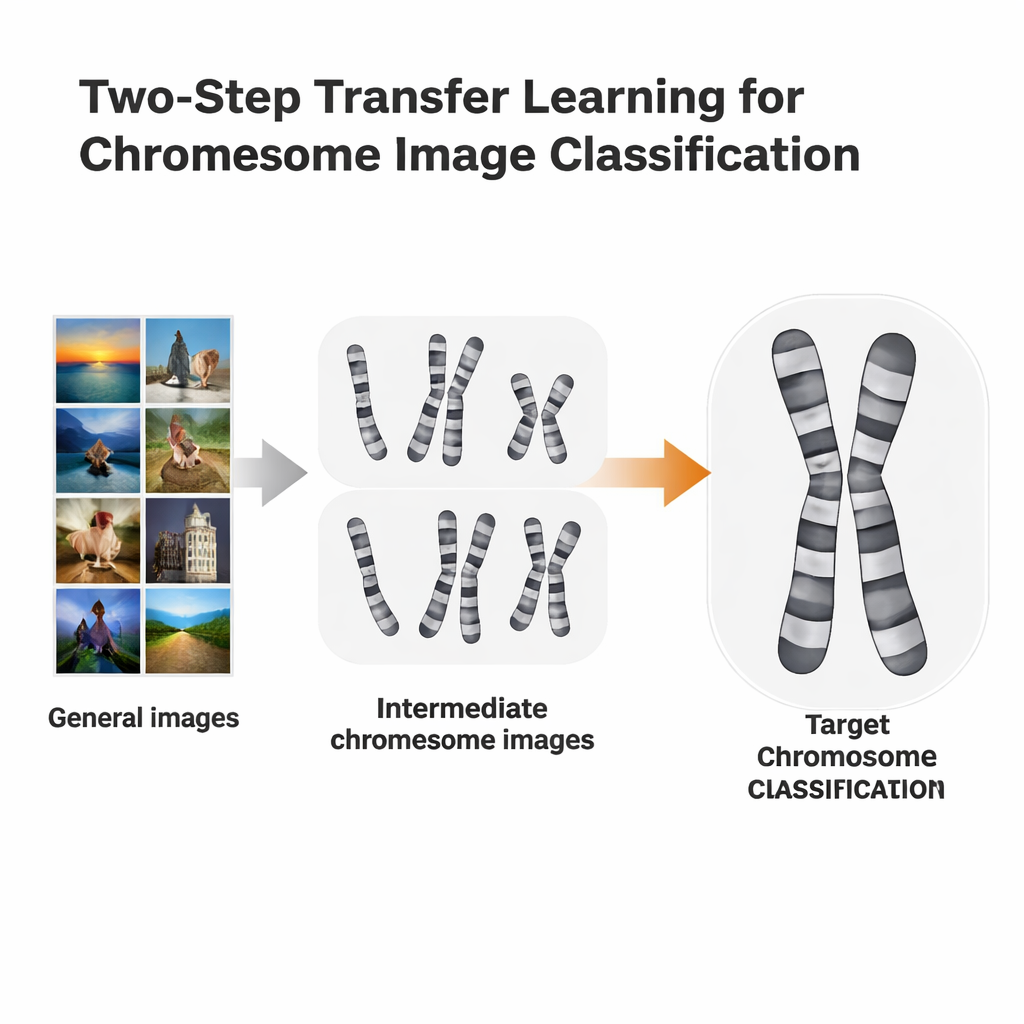
Un raccourci d’apprentissage en deux étapes
Les chercheurs ont testé une voie d’entraînement plus adaptée, appelée apprentissage par transfert en deux étapes. Plutôt que d’aller directement d’ImageNet à une tâche chromosomique spécifique, ils ont d’abord ajusté (fine-tuning) des modèles pré-entraînés sur ImageNet avec des images de chromosomes issues d’une méthode de coloration, puis ils ont affiné à nouveau sur une seconde méthode légèrement différente. Ils ont utilisé deux jeux de données ouverts : les images à bande Q, de qualité inférieure et plus difficiles à lire, et les images à bande G, plus propres et plus détaillées. Chaque jeu a tour à tour servi de « pierre d’étape » pour l’autre. L’idée est comparable à l’apprentissage des langues : si vous connaissez déjà l’espagnol, il peut être plus facile d’apprendre l’italien que de passer directement de l’anglais.
Tester de nombreux « yeux » informatiques
Pour déterminer quand cette étape supplémentaire aide, l’équipe a entraîné 66 classifieurs différents, combinant 11 architectures neuronales populaires avec trois stratégies : entraînement depuis zéro, fine-tuning depuis ImageNet seulement, et transfert en deux étapes. Ils ont évalué les performances avec la Macro-F1, un score qui traite tous les types chromosomiques équitablement, y compris les rares. D’abord, ils ont confirmé que les images Q-band et G-band sont statistiquement plus similaires entre elles que chacune ne l’est à ImageNet, ce qui en fait des candidats prometteurs comme étapes intermédiaires. Ensuite, ils ont comparé l’apprentissage des différents modèles selon chaque stratégie sur les jeux de données faciles (G-band) et difficiles (Q-band).
Quand l’étape supplémentaire est payante
Sur les images de meilleure qualité (G-band), presque tous les modèles performaient déjà très bien après un simple fine-tuning depuis ImageNet, avec des scores autour de 97–98 %. Ici, l’entraînement en deux étapes n’apportait que de très petits gains — souvent moins d’un point de pourcentage — et pouvait parfois pénaliser les architectures plus anciennes. En revanche, sur les images plus difficiles (Q-band), le tableau changeait. Les architectures modernes et compactes telles que ConvNeXt, Swin Transformer, Vision Transformer et MobileNetV3 ont clairement bénéficié de la voie en deux étapes, s’améliorant d’environ 0,8 à 3,3 points de pourcentage par rapport à ImageNet seul. Des cartes visuelles montrant où les modèles « regardaient » expliquent pourquoi : avec le transfert en deux étapes, les réseaux se focalisaient de façon plus homogène le long des bandes des deux bras du chromosome, plutôt que de ne considérer que les contours ou une région unique. En revanche, des réseaux volumineux et plus anciens comme VGG n’ont pas gagné et se sont parfois dégradés, ce qui suggère qu’un meilleur design peut l’emporter sur la simple taille.
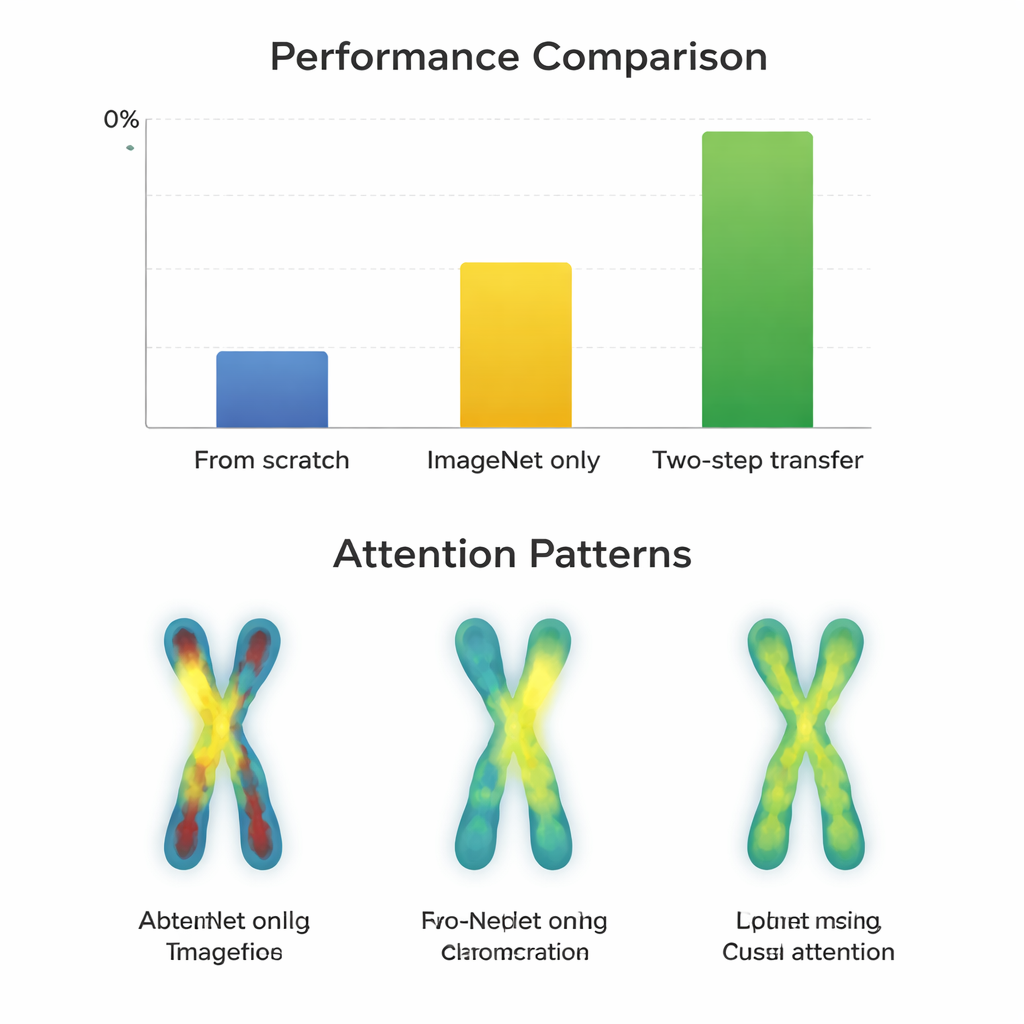
Des limites imposées par les données elles‑mêmes
Les chercheurs ont aussi examiné les erreurs sur les images G-band. Certaines fautes n’étaient pas dues à la stratégie d’apprentissage mais à des entrées défectueuses, comme des chromosomes mal recadrés lors de la séparation de formes superposées. Dans ces cas, toutes les méthodes d’entraînement ont peiné, et les cartes d’attention étaient dispersées ou fixées sur des bords trompeurs. Cela souligne un message pratique pour les cliniques et les développeurs : même le meilleur pipeline d’entraînement ne peut pas entièrement compenser une mauvaise qualité d’image ou des erreurs de prétraitement, surtout avec des jeux de données de taille modeste comme ceux disponibles pour l’imagerie chromosomique.
Ce que cela implique pour le diagnostic en pratique
Pour les non‑spécialistes, la conclusion principale est que la réutilisation intelligente d’images médicales apparentées peut rendre la lecture automatisée des chromosomes plus précise — en particulier lorsque les données cibles sont bruyantes ou rares et lorsqu’on utilise des réseaux neuronaux modernes et bien conçus. Pour des images de haute qualité, l’entraînement classique basé sur ImageNet peut déjà suffire. Mais lorsque les pathologistes travaillent avec des jeux de données plus difficiles, une étape d’apprentissage supplémentaire utilisant un type d’image étroitement lié peut affiner le « regard » de l’ordinateur, portant les performances dans une fourchette de 93–98 %. Cette approche pourrait s’étendre au‑delà des chromosomes à de nombreux domaines de l’imagerie médicale où les données étiquetées sont limitées, aidant à rapprocher des outils d’IA fiables de la pratique clinique courante.
Citation: Chen, T., Xie, C., Zhang, W. et al. ImageNet pre-training and two-step transfer learning in chromosome image classification. Sci Rep 16, 7572 (2026). https://doi.org/10.1038/s41598-026-38662-w
Mots-clés: classification des chromosomes, IA en imagerie médicale, apprentissage par transfert, modèles d’apprentissage profond, caryotypage