Clear Sky Science · fr
FedSCOPE : Recommandation séquentielle inter-domaines fédérée avec apprentissage contrastif découplé et amélioration sémantique préservant la vie privée
Pourquoi des recommandations plus intelligentes et plus sûres comptent
Chaque fois que vous parcourez des films, faites des achats en ligne ou lisez des avis, des systèmes de recommandation décident discrètement de ce qu’il faut vous proposer ensuite. À mesure que notre vie numérique s’étend sur de nombreuses applications et sites, ces systèmes pourraient être bien meilleurs s’ils pouvaient apprendre de l’ensemble de vos activités — sans jamais exposer vos données privées. Cet article présente FedSCOPE, une nouvelle méthode permettant à différentes plateformes de collaborer pour produire des recommandations à la fois plus précises et plus respectueuses de la vie privée des utilisateurs.
Le problème des moteurs de recommandation d’aujourd’hui
La plupart des systèmes de recommandation actuels vivent au sein d’une seule application ou d’un seul site et ne voient qu’une tranche étroite de votre comportement. Ils ont donc du mal avec les utilisateurs « cold-start » qui ont peu d’historique, ou avec des produits de niche peu fréquentés. Lorsque les entreprises tentent de combiner des données entre domaines — par exemple livres et films, ou alimentation et ustensiles de cuisine — elles rencontrent trois gros obstacles : les données sont souvent clairsemées, les plateformes présentent des types d’utilisateurs et d’activités très différents, et des règles strictes de confidentialité rendent risqué le fait de regrouper des données brutes en un seul endroit. Les remèdes simples, comme ajouter la même quantité de bruit préservant la vie privée pour tous, ont tendance soit à affaiblir la protection, soit à dégrader fortement la précision.
Laisser les modèles de langage combler les lacunes
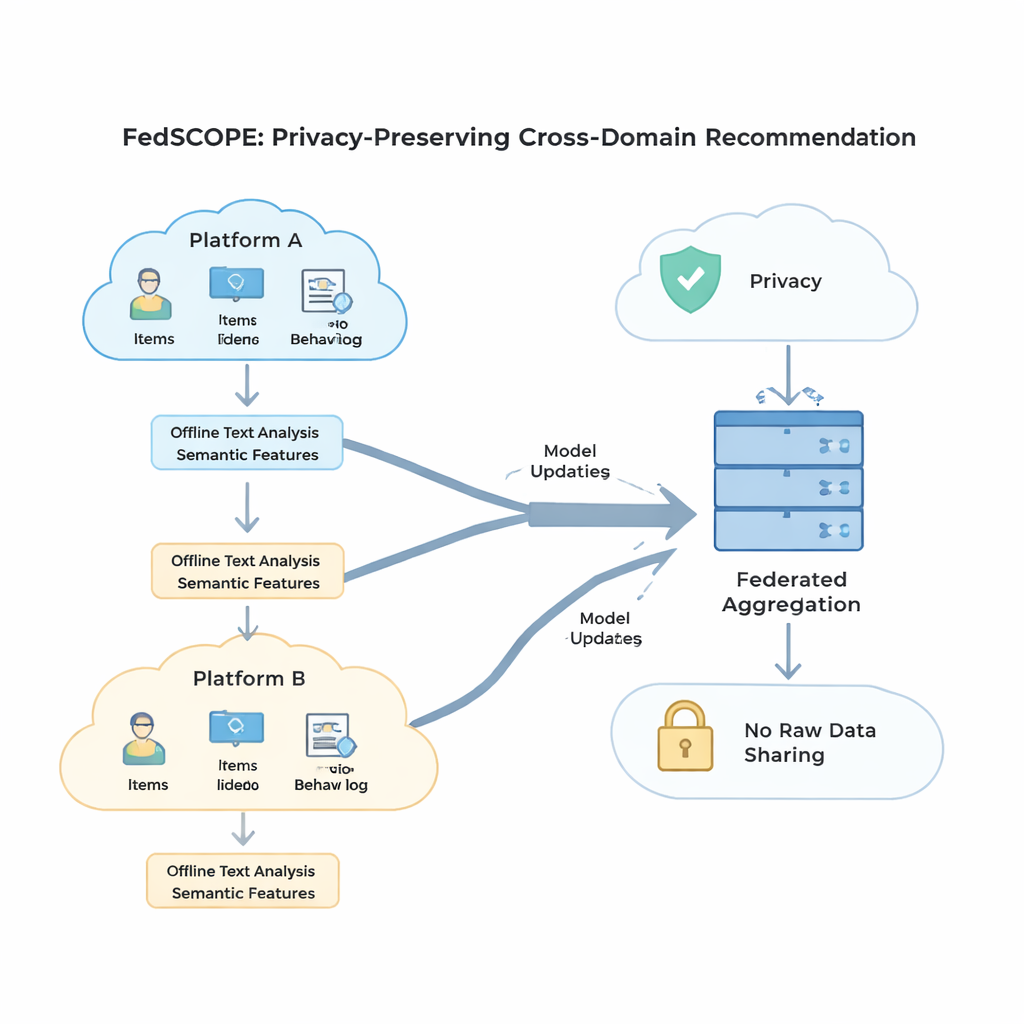
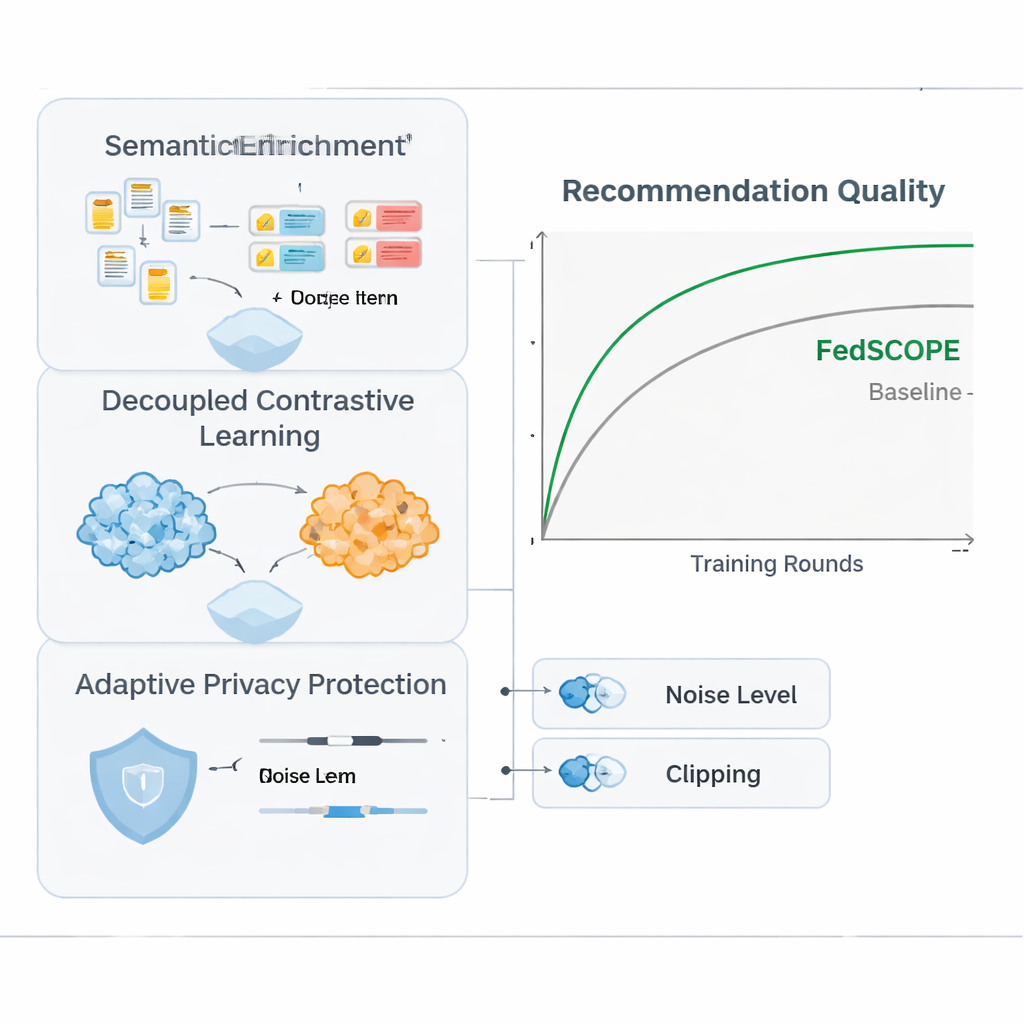
FedSCOPE s’attaque au problème de la rareté en faisant enrichir chaque plateforme ses données par un grand modèle de langage (LLM), mais d’une manière inhabituelle et soucieuse de la confidentialité. Plutôt que d’envoyer les historiques utilisateur à un service d’IA distant à chaque recommandation, chaque client exécute un processus hors ligne et ponctuel : il fournit au LLM les titres et informations basiques sur les items (par exemple le nom et le genre d’un film) et demande des descriptions structurées, comme les thèmes probables, les habitudes de consommation ou les intérêts associés. Ces attributs générés restent sur l’appareil ou le serveur local et sont fusionnés avec les historiques de clics et de visionnage via un réseau neuronal léger. Cela donne au système une compréhension plus riche des utilisateurs et des items, ce qui est particulièrement utile lorsqu’il n’existe que peu d’interactions enregistrées. Parce que le processus est hors ligne et local, le comportement brut ne quitte jamais la plateforme et il n’y a pas de dépendance continue à des services d’IA externes.
Séparer ce qui est personnel de ce qui peut être partagé
Pour exploiter des comportements provenant de plusieurs domaines sans mélanger les signaux de manière préjudiciable, FedSCOPE introduit une stratégie d’entraînement appelée apprentissage contrastif découplé. En termes simples, le système apprend deux choses à la fois. D’une part, au sein de chaque domaine — par exemple seulement la partie films — il rapproche les utilisateurs qui se comportent de façon similaire et écarte ceux qui ne le sont pas, affinant ainsi la notion de goût personnel dans cet environnement. D’autre part, entre les domaines, il aligne les représentations d’un même utilisateur tout en maintenant la distinction entre utilisateurs différents, de sorte que ce que vous regardez puisse aider à prédire ce que vous pourriez lire ou acheter, sans vous confondre avec d’autres. En traitant séparément ces objectifs « intra-domaine » et « inter-domaine », la méthode évite le piège courant qui consiste à forcer tout le monde dans un même modèle partagé et à détruire les préférences fines.
Protéger la vie privée sans sacrifier l’utilité
La forte confidentialité mathématique, connue sous le nom de confidentialité différentielle, implique généralement d’ajouter un bruit aléatoire aux mises à jour du modèle avant qu’elles ne soient partagées avec un serveur central. De nombreux systèmes antérieurs utilisaient les mêmes paramètres de confidentialité pour tous les participants, ce qui convient mal lorsque certains clients comptent des millions d’utilisateurs et d’autres seulement quelques milliers. FedSCOPE attribue plutôt à chaque client un budget de confidentialité personnalisé et adapte la quantité de rognage et de perturbation de ses mises à jour en fonction de la taille de ses données et de son comportement passé. Les grandes plateformes riches en données peuvent fournir des informations plus précises sans être excessivement bruitées, tandis que les plus petites sont protégées plus fortement. Toutes les mises à jour sont ensuite agrégées via une agrégation sécurisée, de sorte que le serveur ne voit jamais aucune contribution individuelle en clair.
Ce que montrent les expériences en pratique
Les auteurs ont testé FedSCOPE sur des données d’achat réelles d’Amazon, en associant des domaines comme Films avec Livres et Alimentation avec Cuisine. Ils l’ont comparé à un éventail de méthodes de recommandation modernes, y compris d’autres approches préservant la vie privée et inter-domaines. Sur plusieurs mesures de précision, FedSCOPE se classait systématiquement en tête ou près du sommet. Il a convergé plus rapidement lors de l’entraînement, mieux fonctionné pour les utilisateurs ayant très peu d’interactions passées et tenu bon lorsque le nombre de clients participants ou la fraction échantillonnée à chaque tour changeait. Importamment, lorsque l’équipe a renforcé les contraintes de confidentialité, la stratégie adaptative de FedSCOPE a maintenu des performances bien supérieures à celles des systèmes utilisant une confidentialité différentielle uniforme pour tous.
Ce que cela signifie pour les utilisateurs quotidiens
Du point de vue d’un non-spécialiste, FedSCOPE ouvre la voie à un futur où vos applications préférées peuvent collaborer pour mieux comprendre vos goûts sans jamais regrouper vos données brutes. En enrichissant des historiques clairsemés grâce à l’apport des modèles de langage, en séparant soigneusement ce qui est spécifique à un domaine de ce qui peut être partagé et en ajustant les contrôles de confidentialité à chaque participant, le cadre offre des recommandations à la fois plus pertinentes et plus respectueuses des informations personnelles. Concrètement, cela peut se traduire par de meilleures suggestions sur ce que regarder, lire ou acheter ensuite — sans avoir à sacrifier votre vie privée numérique.
Citation: Zhao, L., Lin, Y., Qin, S. et al. FedSCOPE: Federated cross-domain sequential recommendation with decoupled contrastive learning and privacy-preserving semantic enhancement. Sci Rep 16, 7420 (2026). https://doi.org/10.1038/s41598-026-38628-y
Mots-clés: recommandation fédérée, IA préservant la vie privée, personnalisation inter-domaines, grands modèles de langage, confidentialité différentielle