Clear Sky Science · fr
Explorer l’interaction enseignant‑élève grâce aux grands modèles de langage multimodaux : une investigation empirique
Pourquoi il est important d’observer les classes avec l’IA
Quiconque a déjà été assis dans une salle de classe sait que la manière dont enseignants et élèves interagissent peut faire la différence entre l’ennui et un véritable apprentissage. Pourtant, il est étonnamment difficile d’étudier ces échanges au fil des moments : les observateurs se fatiguent, les jugements humains varient, et les données vidéo deviennent rapidement écrasantes. Cet article examine comment un nouveau type d’intelligence artificielle — des grands modèles de langage multimodaux capables de « voir » des images et de « lire » du texte — peut aider les chercheurs et les établissements à comprendre la vie complexe de la classe de façon plus rapide et plus objective.
Transformer des leçons réelles en données de recherche
Les chercheurs ont commencé avec des vidéos de cours ordinaires provenant d’écoles primaires et secondaires chinoises, accessibles publiquement sur une plateforme nationale d’éducation. À partir de 30 leçons, ils ont extrait près de 2 400 images fixes saisissant des moments clés d’enseignement et d’apprentissage. Chaque image a été étiquetée selon cinq types d’interaction faciles à saisir : guidée (enseignant expliquant), collaborative (élèves travaillant ensemble), interrogative (questions et réponses), indépendante (élèves travaillant seuls) et présentative (élèves exposant devant la classe). Des experts en technologie éducative ont aidé à affiner ces catégories pour qu’elles correspondent à ce que des observateurs expérimentés repèrent dans de vraies classes.
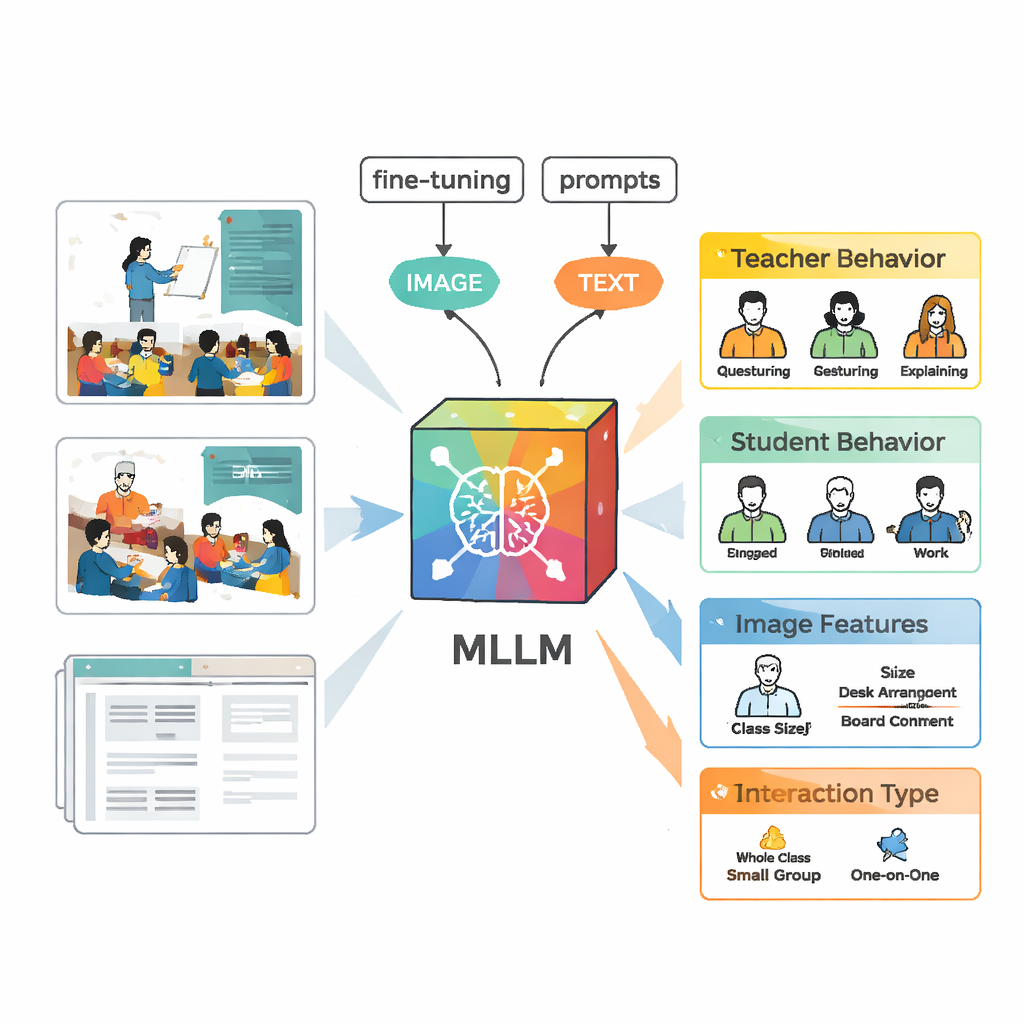
Apprendre à une IA à percevoir la dynamique de classe
Pour analyser ces scènes, l’équipe a utilisé un grand modèle de langage multimodal appelé VisualGLM‑6B, capable de prendre en entrée à la fois des images et du texte. Parce que le modèle original avait été entraîné de manière générale et non spécifiquement sur des classes, les chercheurs l’ont « affiné » à l’aide de leurs images étiquetées. Ils ont adopté une technique appelée LoRA qui n’ajuste qu’un petit nombre de paramètres internes du modèle, rendant l’entraînement plus efficace tout en restant puissant. Ils ont aussi conçu des invites soignées — des instructions structurées demandant au modèle de décrire le comportement de l’enseignant, celui des élèves, les caractéristiques visuelles et le type d’interaction selon un format cohérent — afin que les sorties soient plus faciles à comparer aux jugements d’experts humains.
Construire de meilleurs libellés avec humains et machines
Créer un jeu d’entraînement de haute qualité a requis plus que de pointer le modèle vers des vidéos. D’abord, VisualGLM a produit des descriptions de base pour chaque image. Des annotateurs humains ont ensuite corrigé les erreurs et complété le contexte manquant, par exemple qui parlait ou si les élèves écoutaient ou discutaient. Ensuite, ces descriptions retravaillées ont été fournies à ChatGPT qui, guidé par des invites personnalisées, a généré des analyses structurées suivant les cinq catégories d’interaction. Des experts ont de nouveau révisé et édité ces analyses générées par l’IA. Le résultat final est un jeu de données riche dans lequel chaque image porte un compte rendu détaillé et fiable de ce que faisaient enseignants et élèves.
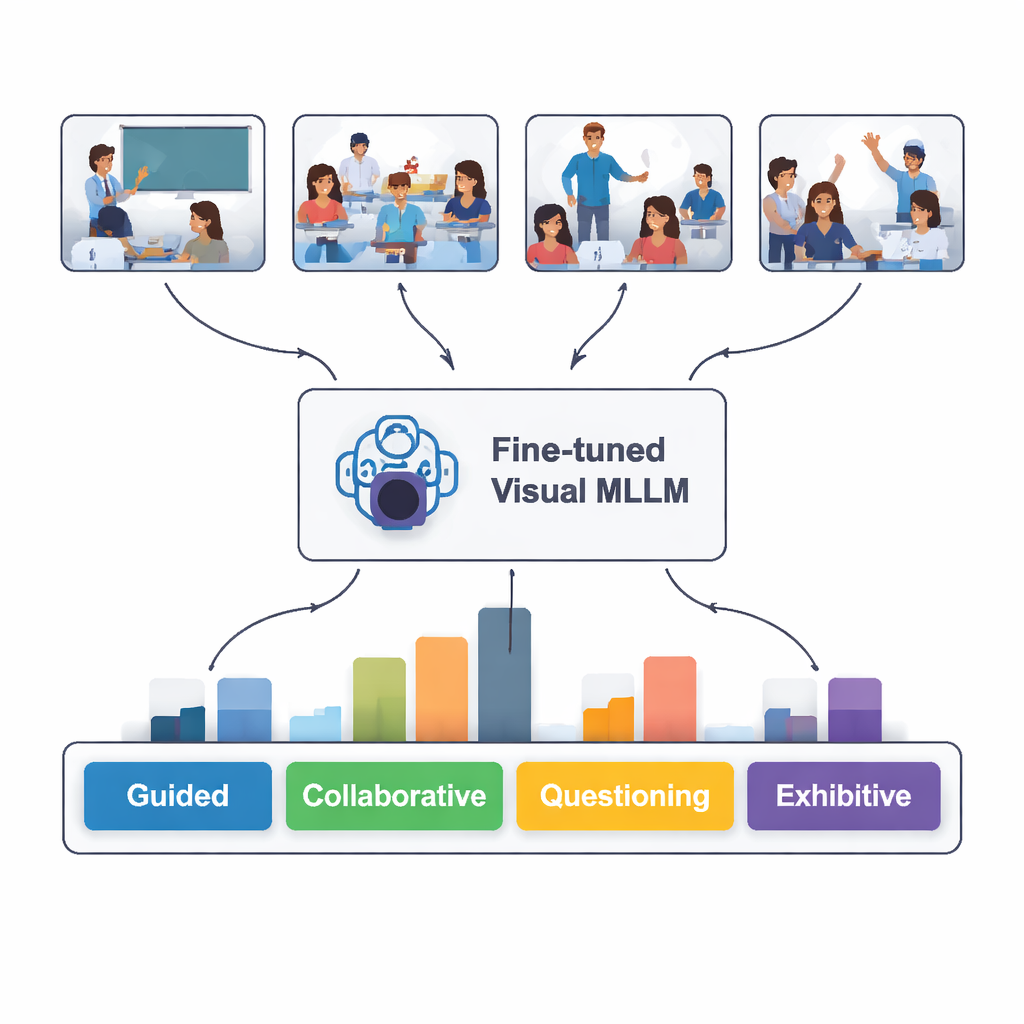
Dans quelle mesure l’IA a‑t‑elle « lu » la classe ?
Testé sur 100 nouvelles images de classe jamais vues auparavant, le modèle affiné a identifié correctement le type d’interaction dans 82 % des cas. Il a été le plus performant pour reconnaître les situations guidées, indépendantes et présentatives — lorsque l’enseignant explique clairement, que les élèves travaillent silencieusement de leur côté, ou qu’un élève fait une présentation devant la classe. Il a eu plus de difficultés avec le travail collaboratif et les séances d’interrogation, où le langage corporel et la disposition des sièges peuvent être ambigus même pour des observateurs humains. Une comparaison textuelle plus approfondie a montré que les descriptions écrites du modèle correspondaient souvent étroitement aux analyses d’experts, bien qu’il arrive qu’il « hallucine » des détails non présents dans les images ou interprète mal un geste subtil.
Ce que cela signifie pour les classes de demain
Pour un lecteur non spécialiste, le message principal est que les systèmes d’IA deviennent capables d’observer des classes et de résumer comment se déroulent l’enseignement et l’apprentissage, avec un niveau de structure et de cohérence difficile à maintenir pour des humains sur des milliers de scènes. Bien qu’ils ne soient pas parfaits — notamment pour les formes subtiles de discussion et d’interrogation —, l’approche montre que les grands modèles de langage multimodaux peuvent déjà soutenir la recherche en éducation et, à terme, des outils de retour pour la classe. À mesure que ces modèles intégreront le son, les gestes et des jeux de données plus larges et variés, ils pourront aider les enseignants à repérer des motifs dans leur pratique qui étaient auparavant cachés, offrant une nouvelle perspective sur la manière dont les interactions quotidiennes façonnent l’apprentissage des élèves.
Citation: Chen, G., Han, G., Niu, J. et al. Exploring teacher-student interaction through multimodal large language models: an empirical investigation. Sci Rep 16, 7602 (2026). https://doi.org/10.1038/s41598-026-38626-0
Mots-clés: interaction enseignant‑élève, analyse de classe, IA multimodale, technologie éducative, grands modèles de langage