Clear Sky Science · fr
Classification incrémentale intelligente utilisant un réseau neuronal dynamique amélioré par des sauterelles pour flux de données
Pourquoi les données en perpétuel changement comptent
Des réseaux électriques et des usines aux paiements en ligne, les systèmes modernes génèrent des données chaque seconde. Cachés dans ces flux continus se trouvent des signaux précurseurs de pannes d’équipement, de cyberattaques ou de fortes variations de prix. Le défi est que ce flot d’informations ne s’arrête jamais et que son comportement évolue dans le temps. L’article résumé ici présente une nouvelle façon d’entraîner des réseaux neuronaux pour qu’ils continuent d’apprendre à partir de ces données en direct sans ralentir ni perdre en précision, ce qui les rend plus utiles pour la surveillance et la prise de décision en conditions réelles.
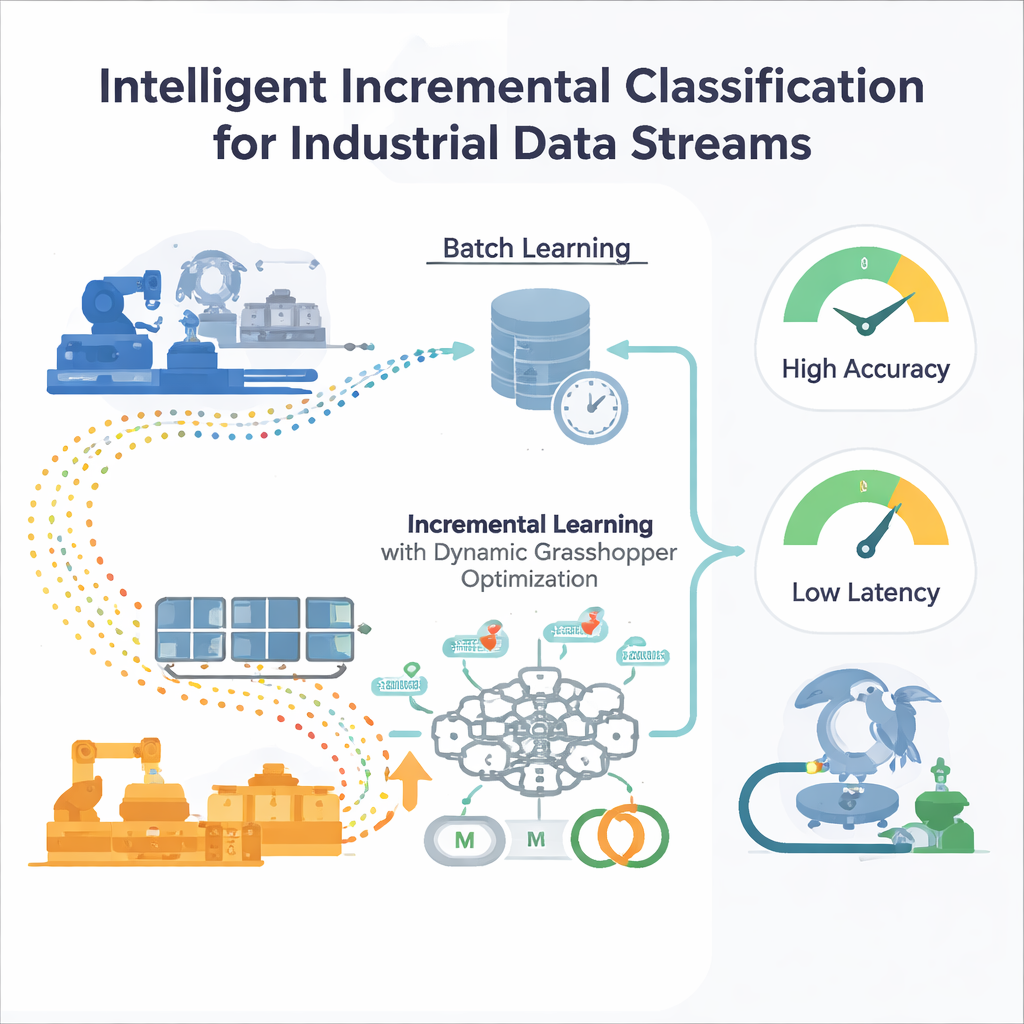
Les limites de l’entraînement ponctuel
La plupart des modèles d’apprentissage automatique traditionnels sont entraînés par « lots » : les ingénieurs rassemblent un grand jeu de données historique, ajustent le modèle, puis le déploient. Cela fonctionne si le monde reste à peu près constant. Mais en milieu industriel, les conditions dérivent — les schémas de demande changent, les capteurs vieillissent, les marchés fluctuent. Un modèle figé dans le temps devient progressivement aveugle aux nouveaux motifs, et le réentraîner depuis zéro sur des jeux de données de plus en plus grands est coûteux et lent. Les méthodes d’optimisation automatique classiques, comme la recherche en grille ou les algorithmes évolutionnaires, supposent elles aussi des données fixes, et doivent donc être relancées chaque fois que la distribution des données change, ce qui est impraticable pour des systèmes toujours actifs.
Un réseau neuronal qui apprend en continu
Les auteurs proposent un cadre d’apprentissage incrémental centré sur un perceptron multi-couches (MLP), un type courant de réseau neuronal. Plutôt que d’alimenter le réseau avec toutes les données passées d’un coup, le flux entrant est découpé en fenêtres gérables. Chaque nouvelle fenêtre constitue une petite étape d’entraînement qui met à jour les poids internes du réseau puis est supprimée — une stratégie « entraîner-et-oublier » qui maintient une faible empreinte mémoire. Surtout, le système ne repose pas sur des réglages d’entraînement fixes. Deux paramètres clés qui contrôlent le comportement d’apprentissage — le taux d’apprentissage (l’amplitude de chaque mise à jour) et le momentum (la fluidité des mises à jour) — sont continuellement ajustés au fil du flux, afin que le modèle reste réactif sans devenir instable.
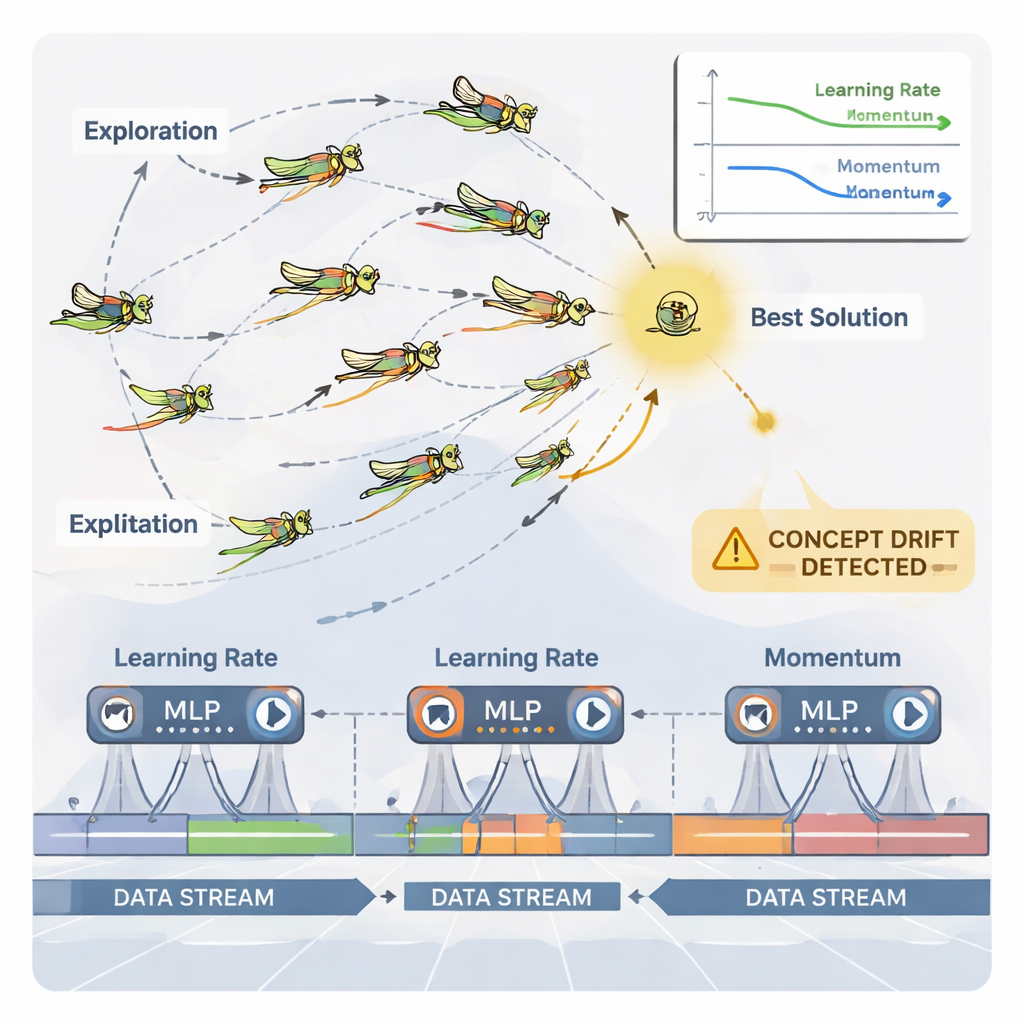
Les sauterelles comme réglage intelligent des paramètres
Pour gérer cet ajustement continu, l’article utilise un optimiseur inspiré de la nature appelé Dynamic Grasshopper Optimization Algorithm (DGOA). Imaginez un essaim de sauterelles virtuelles explorant des combinaisons possibles de taux d’apprentissage et de momentum. Au départ, elles se déplacent largement pour rechercher de bonnes régions ; plus tard, elles resserrent leurs mouvements pour affiner les choix prometteurs. Dans cette variante dynamique, leur taille de pas et leur attraction vers la meilleure solution évoluent dans le temps en fonction des performances du réseau neuronal. Le système surveille également le « concept drift » — des changements brusques dans les erreurs de prédiction ou dans les données elles-mêmes. Lorsqu’un drift est détecté, certaines sauterelles sont réinitialisées et leurs pas deviennent temporairement plus grands, ce qui permet à l’optimiseur de rechercher rapidement de nouvelles régions et d’échapper à des réglages obsolètes.
Mise à l’épreuve de la méthode
Les chercheurs ont évalué leur approche sur un jeu de données réel du marché de l’électricité en Australie, où l’objectif était de prédire si les prix allaient monter ou baisser. Comparée à des méthodes d’ajustement courantes telles que la recherche en grille, la recherche aléatoire, l’optimisation par essaim particulaire, les algorithmes génétiques, l’optimisation par colonie de fourmis et l’algorithme standard des sauterelles, la version dynamique couplée à l’apprentissage incrémental a atteint la meilleure précision (environ 89,5 %) tout en consommant moins de temps de calcul et moins d’itérations. Des expériences complémentaires ont montré que la méthode s’adapte mieux aux flux de données stables comme changeants, qu’elle évolue de milliers à des milliards d’échantillons tout en maîtrisant la mémoire, et qu’elle est performante sur des tâches comme la maintenance prédictive, la détection d’anomalies et la détection de fraude, ainsi que sur des bancs d’essai d’optimisation mathématique standard.
Ce que cela signifie en pratique
Pour les non-spécialistes, la conclusion est que ce travail propose un moyen de garder les réseaux neuronaux « vivants » et bien réglés dans des environnements où les données ne s’arrêtent jamais et où les conditions évoluent constamment. Plutôt que d’arrêter le système à répétition pour reconstruire les modèles depuis zéro, le cadre proposé permet à un réseau léger de se mettre à jour fenêtre par fenêtre, tandis qu’un optimiseur en essaim ajuste en continu la vitesse et la fluidité de l’apprentissage. Le résultat est une adaptation plus rapide aux nouveaux motifs, une meilleure précision à long terme et une utilisation plus efficace des ressources de calcul — des éléments clés pour une prise de décision fiable en temps réel dans des secteurs comme l’énergie, l’industrie et la finance.
Citation: Darwish, S.M., El-Shoafy, N.A. Intelligent incremental classification using a dynamic grasshopper-enhanced neural network for data streams. Sci Rep 16, 7730 (2026). https://doi.org/10.1038/s41598-026-38571-y
Mots-clés: flux de données, apprentissage incrémental, réseaux neuronaux, optimisation des hyperparamètres, intelligence en essaim