Clear Sky Science · fr
Un modèle d’apprentissage automatique interprétable utilisant des données cliniques de routine pour prédire précocement la récidive du carcinome hépatocellulaire
Pourquoi cela compte pour les patients et leurs proches
Pour les personnes qui subissent une intervention chirurgicale visant à retirer un cancer du foie, l’une des questions les plus pressantes est : « Le cancer va‑t‑il récidiver rapidement ? » Aujourd’hui, les médecins ne peuvent proposer que des estimations approximatives, souvent fondées sur des systèmes de stadification larges qui traitent de nombreux patients comme s’ils étaient identiques. Cette étude présente une nouvelle façon d’utiliser des informations déjà collectées par les hôpitaux — analyses sanguines de routine et résultats d’imagerie — associées à une intelligence artificielle interprétable, afin d’offrir à chaque patient une image plus claire et personnalisée de son risque à court terme de récidive.
Un cancer fréquent avec un taux de récidive tenace
Le carcinome hépatocellulaire est le type le plus courant de cancer primitif du foie et une cause majeure de décès par cancer dans le monde. Même lorsque les chirurgiens retirent complètement les tumeurs visibles, plus de 70 % des patients voient la maladie réapparaître dans les cinq ans. La récidive précoce — dans les deux ans environ après la chirurgie — est particulièrement préoccupante, car elle reflète généralement des cellules cancéreuses agressives déjà disséminées dans le foie et dégrade fortement la survie. Les systèmes de stadification cliniques existants, tels que TNM ou le Barcelona Clinic Liver Cancer (BCLC), classent grossièrement les patients en grandes catégories mais échouent souvent à identifier précisément qui est réellement à haut risque d’une récidive précoce.
Transformer des tests courants en score de risque
Les chercheurs se sont appuyés sur les dossiers de 1 120 patients ayant bénéficié d’une chirurgie apparemment curative du foie dans deux grands hôpitaux en Chine entre 2014 et 2024. Ils se sont concentrés uniquement sur les informations disponibles avant l’intervention : âge et sexe, caractéristiques à l’imagerie comme la taille de la plus grande tumeur et la présence de tumeurs multiples, ainsi qu’un large panel d’analyses biologiques standard réalisées dans les jours précédant la chirurgie. À partir de ces données, ils ont retenu neuf prédicteurs clés liés au risque de récidive. Plutôt que de s’en remettre à une seule formule mathématique, ils ont combiné trois approches d’apprentissage automatique différentes et moyenné leurs sorties pour obtenir un score de risque entre 0 et 1. Les patients ont ensuite été répartis en catégories de risque faible, modéré et élevé sur la base de ce score. 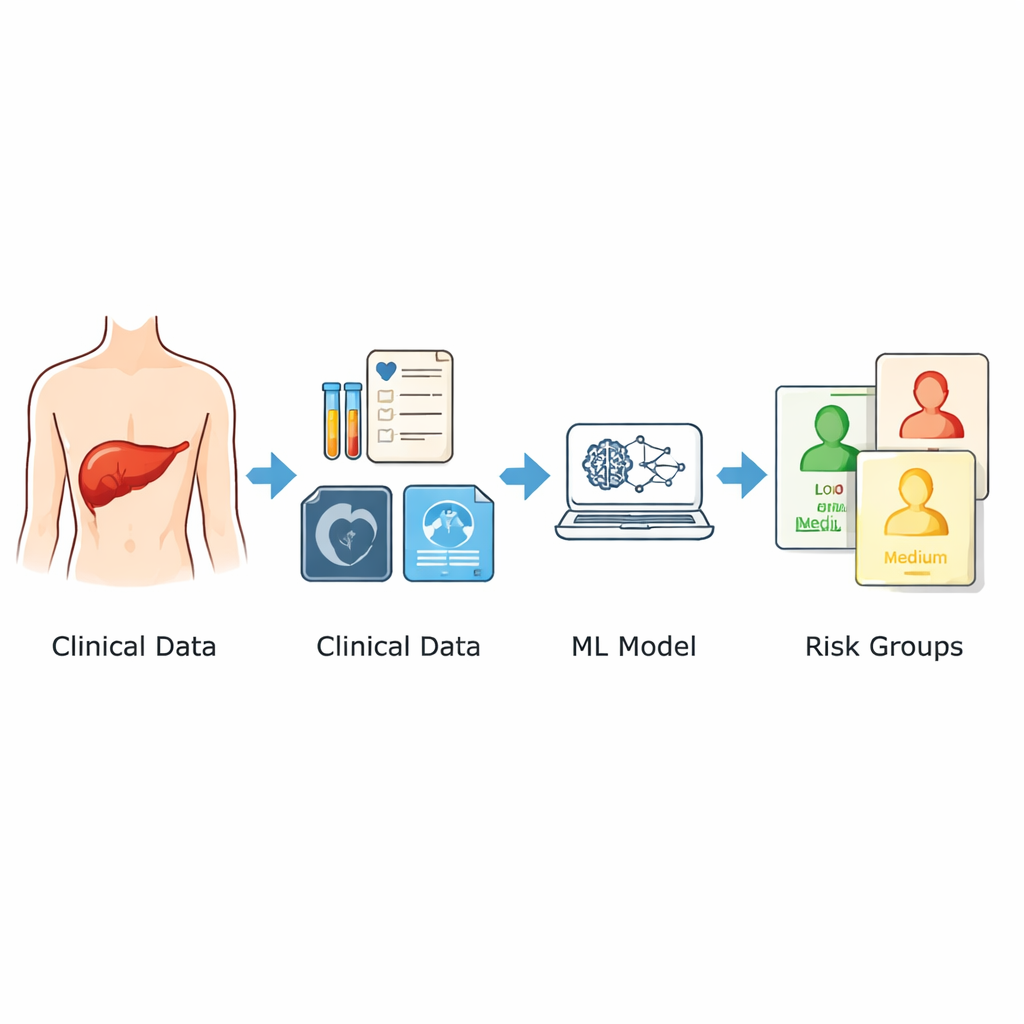
Surpasser les systèmes de stadification classiques
Pour évaluer les performances du modèle, l’équipe l’a d’abord testé sur un ensemble de patients « réservé » de l’hôpital d’origine, puis sur un groupe indépendant de l’autre hôpital. Dans les deux contextes, le nouveau modèle distinguait nettement mieux qui resterait sans cancer et qui récidiverait dans les 24 mois comparé aux systèmes de stadification traditionnels. Dans le groupe de test interne, la précision du modèle dans le temps, mesurée par une statistique standard appelée aire sous la courbe, était d’environ 0,76, contre environ 0,55 à 0,64 pour les méthodes de stadification courantes. Les personnes du groupe à haut risque présentaient la pire survie sans récidive ; celles du groupe à risque modéré voyaient leur risque de récidive réduit d’environ 60 % ; et celles du groupe à faible risque avaient un risque d’environ 90 % inférieur à celui du groupe à haut risque. Ces différences marquées se sont maintenues dans l’hôpital externe et sont restées cohérentes dans la plupart des sous‑groupes, par exemple selon l’âge, le sexe ou la taille des tumeurs.
Ouvrir la « boîte noire » de l’intelligence artificielle
Une critique fréquente de l’apprentissage automatique en médecine est qu’il fonctionne comme une boîte noire : il prédit bien, mais même les spécialistes ne voient pas toujours pourquoi. Pour y remédier, les auteurs ont appliqué une méthode appelée SHapley Additive exPlanations (SHAP), qui décompose chaque prédiction en contributions provenant de chaque facteur d’entrée. L’analyse a montré que la taille de la tumeur était le facteur unique le plus influent sur l’augmentation du risque dans les trois algorithmes, suivie par des caractéristiques comme le nombre de tumeurs et des indicateurs sanguins de la fonction hépatique et de l’inflammation. Fait intéressant, le taux de chlorure sanguin tendait à faire baisser le risque, agissant comme un facteur protecteur dans ce jeu de données. Pour les patients individuels, le modèle peut générer de simples graphiques en barres montrant, par exemple, comment un grand diamètre tumoral et des marqueurs sanguins défavorables augmentent le score de risque, tandis qu’une meilleure fonction hépatique le réduit. 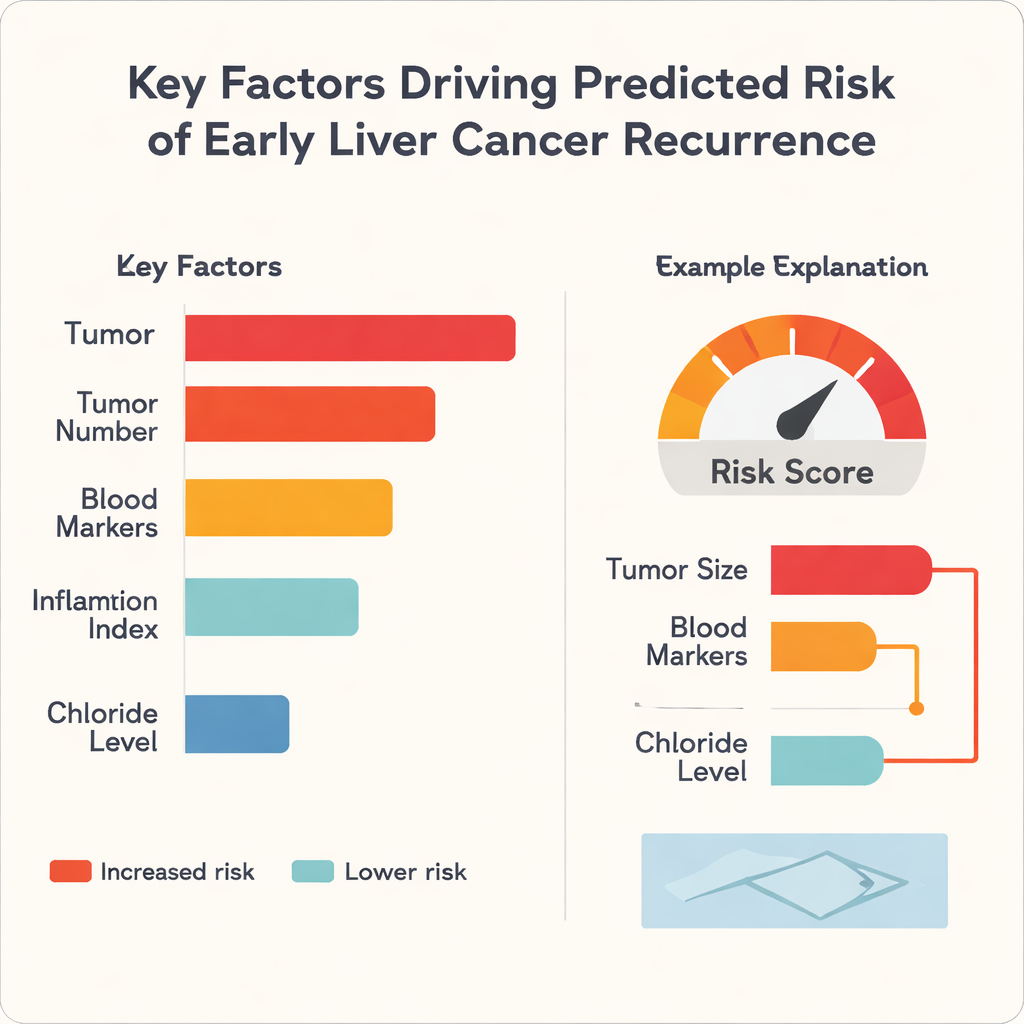
Implications potentielles en clinique
Parce que le modèle fonctionne à partir de données déjà collectées par les hôpitaux et ne nécessite ni examens spécialisés ni tests génétiques coûteux, il pourrait être déployé dans de nombreux contextes de soins, y compris ceux à ressources limitées. Avant la chirurgie, les médecins pourraient l’utiliser pour repérer les personnes nécessitant un suivi plus intensif ou susceptibles de bénéficier de traitements complémentaires après l’intervention, tout en épargnant aux patients réellement à faible risque des examens et de l’anxiété inutiles. Les auteurs soulignent que leur étude est rétrospective et issue d’une population de patients spécifique, de sorte que des essais prospectifs dans des contextes plus diversifiés restent nécessaires. Néanmoins, leur travail illustre comment une IA transparente et explicable peut transformer des chiffres de laboratoire et des résultats d’imagerie familiers en prévisions individualisées significatives, soutenant la prise de décision partagée entre patients et équipes soignantes.
Citation: Guo, DF., Wen, Q., Zhang, X. et al. An interpretable machine learning model using routine clinical data for early recurrence prediction in hepatocellular carcinoma. Sci Rep 16, 7520 (2026). https://doi.org/10.1038/s41598-026-38484-w
Mots-clés: récurrence du cancer du foie, modèle d’apprentissage automatique, prévision du risque clinique, IA interprétable, carcinome hépatocellulaire