Clear Sky Science · fr
Un modèle hybride explicable CNN–transformer pour la reconnaissance de la langue des signes sur appareils edge utilisant la fusion adaptative et la distillation de connaissances
Pourquoi les outils compacts pour la langue des signes sont importants
Des milliards de conversations quotidiennes reposent davantage sur les mouvements des mains, les expressions faciales et le langage corporel que sur des mots prononcés. Pourtant, la plupart des téléphones, tablettes et appareils publics ne comprennent toujours pas les langues des signes, en particulier en dehors des pays anglophones. Cet article présente TinyMSLR, un système compact et explicable de reconnaissance de la langue des signes conçu pour fonctionner en temps réel sur de petits appareils à faible consommation. Il vise à transformer du matériel ordinaire en aides à la communication abordables et dignes de confiance pour les personnes sourdes et malentendantes dans le monde entier.
Faire entrer plus de langues dans la conversation
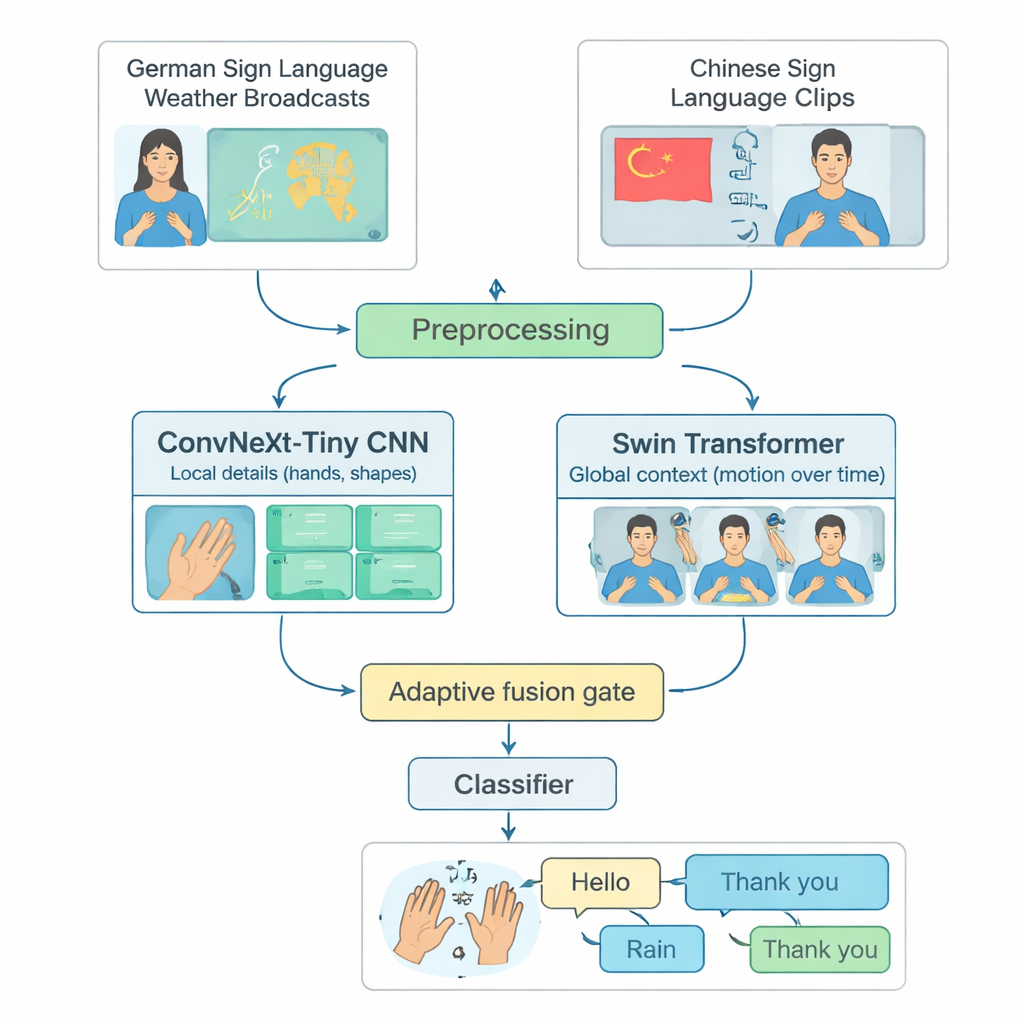
Beaucoup de systèmes avancés de reconnaissance de la langue des signes se concentrent sur une seule langue, le plus souvent la langue des signes américaine, et ne fonctionnent que sur des ordinateurs puissants. Cela exclut les personnes qui utilisent d’autres langues des signes ou vivent dans des régions aux ressources informatiques limitées. Les auteurs comblent cette lacune en construisant un banc d’essai partagé à partir de deux langues différentes : des bulletins météo en langue des signes allemande et une grande collection de langue des signes chinoise. Ils sélectionnent soigneusement 20 signes quotidiens courants—comme Bonjour, Météo, Pluie, Heureux, Oui et Merci—présents dans les deux langues. En découpant les longues vidéos en courts extraits contenant un seul signe, et en équilibrant le nombre d’exemples par classe et par locuteur, ils créent une manière équitable et reproductible d’évaluer la capacité d’un modèle à reconnaître des signes isolés à travers les langues.
Comment le modèle hybride perçoit les mains et le mouvement
TinyMSLR combine deux façons complémentaires d’analyser la vidéo. Une branche utilise un réseau convolutionnel moderne (ConvNeXt‑Tiny) qui excelle pour repérer les détails fins, comme la forme des doigts et les textures subtiles. La seconde branche utilise un Swin Transformer, une famille de modèles récente performante pour suivre des motifs dans l’espace et le temps—comment les mains, le visage et le haut du corps bougent sur plusieurs images. Chaque court extrait vidéo est standardisé à 32 images de 224×224 pixels, légèrement augmenté (par exemple de petites rotations ou variations de luminosité), puis envoyé aux deux branches en parallèle. Chaque branche produit un résumé de 768 nombres de ce qu’elle observe ; ensemble, ces deux résumés capturent à la fois des détails locaux nets et un mouvement et un contexte plus larges.
Laisser le modèle décider de ce qui compte le plus
Parce que certains signes se distinguent principalement par la configuration des mains tandis que d’autres reposent sur des mouvements de bras plus larges ou des indices faciaux, TinyMSLR ne fixe pas une recette unique pour combiner ses deux vues. Il utilise plutôt une petite « porte de fusion » qui apprend, pour chaque extrait d’entrée, combien faire confiance à la branche axée sur le détail par rapport à la branche axée sur le contexte. La porte examine les deux résumés de caractéristiques et produit deux poids qui s’additionnent toujours à un. La représentation finale est un mélange pondéré des deux. Pendant l’entraînement, chaque branche reçoit aussi son propre petit classifieur afin qu’elle apprenne à être utile de façon autonome, et une paire de réseaux « enseignants » plus volumineux (un CNN et un Transformer) guide en douceur le petit modèle en montrant non seulement l’étiquette correcte mais aussi quelles étiquettes alternatives semblent similaires. Cette technique, appelée distillation de connaissances, aide le système compact à approcher la précision des modèles plus lourds tout en conservant une taille et une vitesse adaptées aux appareils edge.
Comprendre pourquoi le système prend chaque décision
Au‑delà de la simple précision, les auteurs insistent sur le fait que les utilisateurs et les développeurs doivent pouvoir inspecter ce à quoi le modèle prête attention. Ils adoptent SHAP, une famille d’outils qui attribue une valeur d’importance à chaque partie de l’entrée. En pratique, ils calculent ces explications sur des caractéristiques intermédiaires et les cartographient ensuite sur les images sous forme de cartes de chaleur et de graphiques temporels. Cela révèle, par exemple, quelles images et quelles régions motivent la décision entre des signes visuellement proches comme Pluie et Neige ou Froid et Mauvais. L’agrégation de nombreuses explications met en évidence des motifs plus larges : des indices non manuels tels que l’expression faciale et les mouvements de tête, ainsi que l’orientation du poignet et la configuration de la main, apparaissent comme particulièrement influents. Ces observations aident à vérifier que le système s’appuie sur des aspects signifiants de la signature plutôt que sur des artéfacts de l’arrière‑plan.

Vitesse, frugalité et marge de progression
Sur le banc d’essai bilingue de 20 signes, TinyMSLR atteint environ 99 % de précision en entraînement et validation et un score F1 proche de 99 %, tout en utilisant moins de 2,7 millions de paramètres et environ 1,9 milliard d’opérations par extrait. Sur un GPU moderne il traite un signe en environ 13,5 millisecondes et consomme moins de 30 millijoules d’énergie ; le modèle stocké ne pèse qu’environ 7,2 mégaoctets. Ces chiffres suggèrent que la reconnaissance de signes en temps réel, directement sur l’appareil, est réalisable sur des cartes et systèmes embarqués à faible coût. Les auteurs précisent que leur travail couvre uniquement des signes courts et isolés et deux langues, et traite les expressions faciales implicitement plutôt qu’en signal séparé. L’extension de l’approche à des vocabulaires plus riches, des phrases continues, plus de langues et une modélisation explicite des mouvements du visage et de la tête est laissée aux travaux futurs. Néanmoins, TinyMSLR propose une preuve de concept convaincante : des outils précis, efficaces et interprétables pour comprendre les langues des signes n’ont pas besoin d’être confinés au cloud—ils peuvent fonctionner directement sur les appareils du quotidien.
Citation: Lamaakal, I., Yahyati, C., Maleh, Y. et al. An explainable hybrid CNN–transformer model for sign language recognition on edge devices using adaptive fusion and knowledge distillation. Sci Rep 16, 7143 (2026). https://doi.org/10.1038/s41598-026-38478-8
Mots-clés: reconnaissance de la langue des signes, tiny machine learning, edge AI, IA explicable, modèles multilingues