Clear Sky Science · fr
SAT : Shift Alignment Transformer pour la réduction de bruit vidéo sans estimation de flux
Des vidéos plus nettes à partir de scènes bruitées
Quiconque a essayé de filmer à l’intérieur la nuit ou avec un téléphone en faible luminosité connaît le résultat : des vidéos granuleuses et scintillantes où les détails semblent vaciller et les couleurs paraissent faussées. Cet article présente une nouvelle méthode pour nettoyer ce type de séquences, les transformant en vidéos plus claires et plus stables sans s’appuyer sur les coûteux logiciels de suivi de mouvement habituellement nécessaires. La méthode, appelée Shift Alignment Transformer, est conçue pour préserver les détails fins tout en restant suffisamment efficace pour être pratique.
Pourquoi nettoyer une vidéo est si difficile
Enlever le bruit d’une seule photographie est déjà un défi ; faire de même pour une vidéo est encore plus compliqué. D’une part, chaque image est corrompue par des points aléatoires et des décalages de couleur. D’autre part, les images sont liées dans le temps : les objets bougent, la caméra tremble et des détails apparaissent et disparaissent. Les méthodes traditionnelles de débruitage vidéo s’appuient souvent sur l’estimation du mouvement entre les images, généralement via un outil appelé flux optique, qui tente de suivre où chaque pixel se déplace d’une image à l’autre. Bien que puissant, cet estimé de mouvement peut facilement se dégrader lorsque la vidéo est très bruitée ou que le mouvement est rapide et complexe, et il ajoute aussi une lourde charge de calcul qui peut ralentir considérablement les systèmes.
Une nouvelle façon d’aligner sans suivre
Plutôt que d’essayer explicitement de suivre chaque pixel, le Shift Alignment Transformer (SAT) prend une voie différente : il laisse le réseau découvrir implicitement comment les images sont liées en décalant et en comparant soigneusement des caractéristiques. Le modèle repose sur une architecture moderne connue sous le nom de Transformer, qui excelle à trouver des connexions à longue portée dans les données. Dans ce cadre, les auteurs introduisent un Spatial-Temporal Shift Module qui mélange en douceur l’information à la fois dans le temps et dans l’espace. Dans le temps, le modèle décale cycliquement les caractéristiques des images de sorte que, couche après couche, chaque image puisse « voir » plus loin dans le passé et le futur. Dans l’espace, il divise les caractéristiques en nombreux petits groupes et pousse chaque groupe dans différentes directions. Cette combinaison mime efficacement la façon dont les objets peuvent se déplacer à travers la vidéo, permettant au réseau d’aligner l’information entre images sans jamais calculer un champ de mouvement explicite.
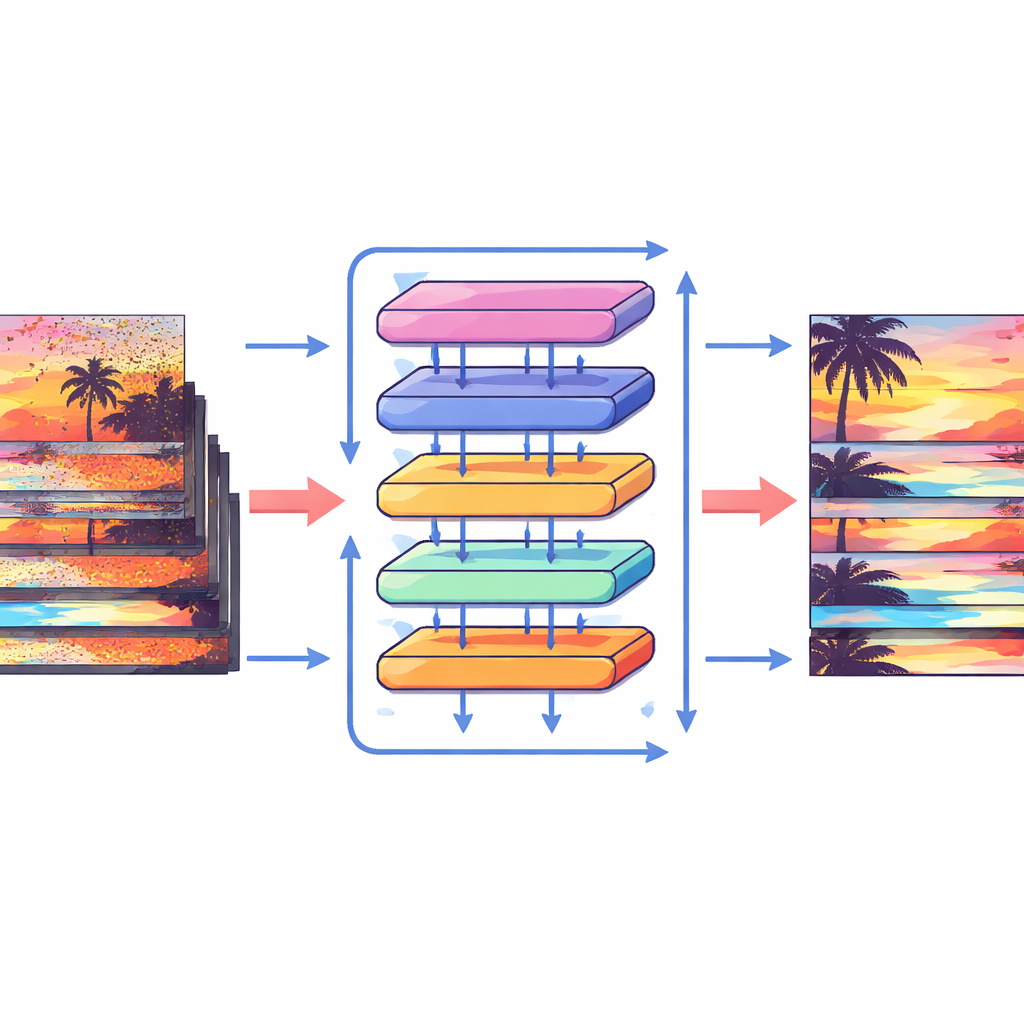
Comment fonctionnent ces nouveaux blocs
Pour tirer parti de ces décalages, les auteurs conçoivent un bloc d’attention spécial qui mélange l’information au sein des images et entre elles. D’abord, les caractéristiques décalées des images voisines sont rapprochées et comparées via une opération de cross-attention : le modèle apprend quelles régions des autres images soutiennent le mieux l’image courante à chaque emplacement. En parallèle, une opération d’attention distincte se concentre sur les relations à l’intérieur de chaque image unique, renforçant la structure et la texture locales. Ces deux flux sont ensuite fusionnés et passés par des couches de traitement simples dans un réseau en U multi-échelle, qui va du résolu grossier au résolu fin et revient en arrière. Cette organisation permet au système de gérer à la fois de grands mouvements de caméra et des détails minuscules tels que de fines arêtes ou de petits motifs, reconstruisant progressivement une version propre de chaque image.
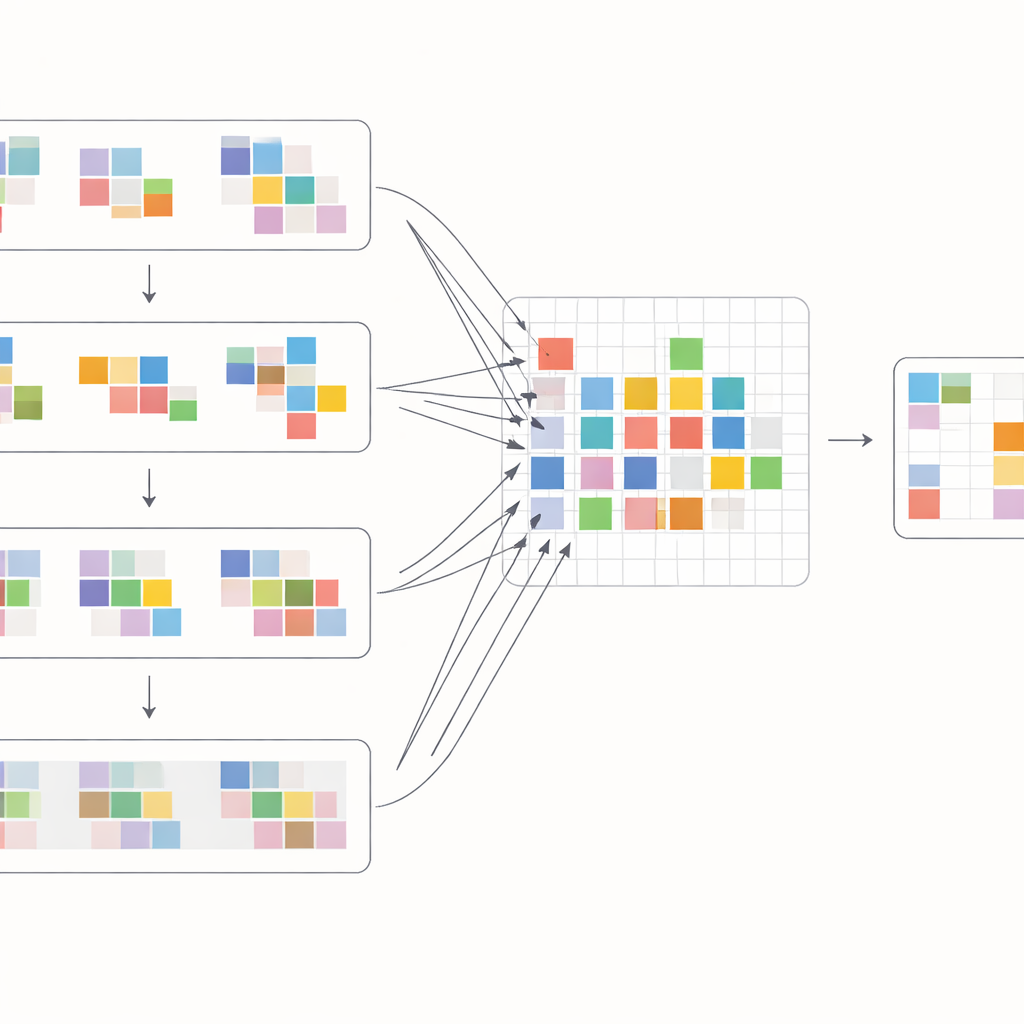
Quelle efficacité en pratique
Les chercheurs testent leur approche sur deux benchmarks exigeants. Le premier utilise des vidéos propres artificiellement corrompues avec différents niveaux de bruit aléatoire, ce qui leur permet de mesurer précisément à quel point les images restaurées se rapprochent des originales. Sur ce test, la nouvelle méthode égalise ou dépasse systématiquement la qualité des réseaux convolutionnels et récurrents antérieurs, et se rapproche des meilleurs modèles basés sur Transformer existants tout en consommant moins de calcul. Le second benchmark utilise des séquences réelles capturées par des capteurs d’image en faible luminosité, où le bruit est inégal, coloré et beaucoup moins prévisible. Sur ce test plus réaliste, le Shift Alignment Transformer surpasse de manière décisive les méthodes précédentes à l’état de l’art, produisant des vidéos qui paraissent plus propres, plus nettes et plus stables dans le temps, avec moins de dérive des couleurs et moins d’artefacts résiduels.
Ce que cela implique pour les outils vidéo futurs
En termes simples, les auteurs montrent qu’il est possible de débruiter efficacement des vidéos sans suivre explicitement le mouvement, en combinant des décalages astucieux dans le temps et l’espace avec un appariement de caractéristiques basé sur l’attention. Leur Shift Alignment Transformer offre un bon compromis entre précision et efficacité, en particulier pour des séquences réelles en faible luminosité, où l’estimation de mouvement traditionnelle est fragile. À mesure que les modèles basés sur l’attention deviennent plus efficaces, des méthodes comme celle-ci pourraient se retrouver dans les appareils photo et les services de streaming du quotidien, aidant à transformer des clips bruyants et difficiles à regarder en vidéos fluides et nettes avec un minimum de tracas pour l’utilisateur.
Citation: Zhang, X., Fan, S., Zhang, H. et al. SAT: shift alignment transformer for video denoising without flow estimation. Sci Rep 16, 8207 (2026). https://doi.org/10.1038/s41598-026-38431-9
Mots-clés: réduction de bruit vidéo, transformer, bruit d'image, vidéo en faible luminosité, vision par ordinateur