Clear Sky Science · fr
Attaque décisionnelle adversariale économe en requêtes avec un faible budget de requêtes
Pourquoi de minuscules imperfections dans les images peuvent tromper des machines intelligentes
L'intelligence artificielle moderne peut reconnaître des visages, des animaux et des objets du quotidien avec une précision impressionnante. Pourtant, ces mêmes systèmes peuvent être trompés par des modifications d'une image si minimes que les humains les distinguent à peine. Cet article explore une nouvelle façon de créer de telles images « trompeuses » tout en posant au système d'IA le moins de questions possible, révélant à la fois la fragilité des modèles actuels et les moyens par lesquels des attaquants pourraient les exploiter dans le monde réel.
Comment les attaquants sondent les systèmes d'IA depuis l'extérieur
Dans de nombreux services réels — comme l'étiquetage de photos en ligne ou les filtres de contenu — le modèle se comporte comme une boîte noire. Les tiers peuvent téléverser une image et ne voir que l'étiquette finale, telle que « chien » ou « panneau stop », sans jamais accéder aux scores de confiance internes ni à la structure du modèle. Créer une image trompeuse dans ces conditions s'appelle une attaque décisionnelle en boîte noire. Le défi consiste à pousser doucement une image normale jusqu'à ce que le modèle la classe incorrectement, sans pouvoir voir à quel point il est « proche » de changer d'avis et sans envoyer autant d'images de test que le système le remarque ou que cela devienne trop coûteux en requêtes.
Une nouvelle manière de chercher en très peu de questions
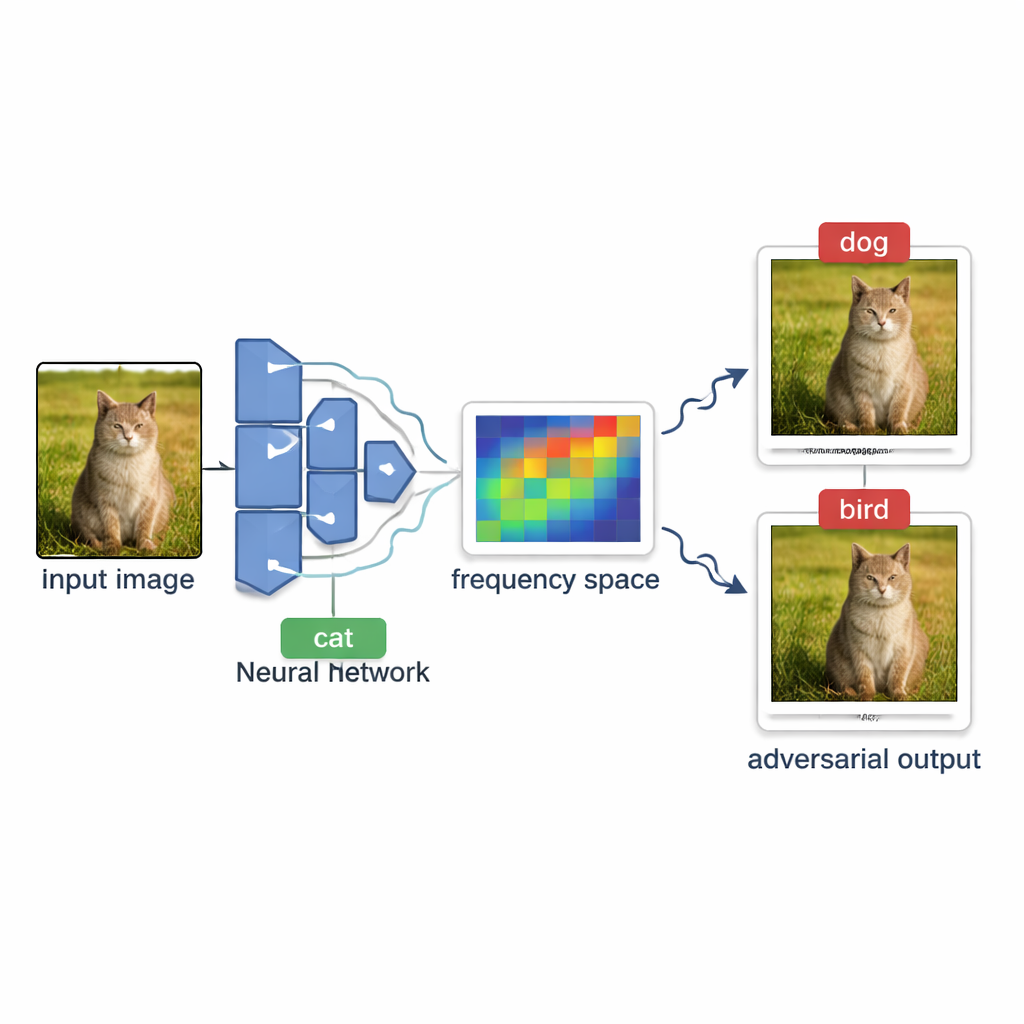
Les auteurs présentent OPOQA (One Plane One Query Attack), une méthode conçue pour être parcimonieuse en requêtes tout en générant des images adversariales de haute qualité. Plutôt que de sonder à plusieurs reprises le long d'une unique direction supposée, OPOQA fonctionne par tours. À chaque tour, elle part d'une image déjà trompeuse et de l'image propre d'origine, puis propose plusieurs nouvelles images candidates situées selon des directions choisies avec soin. Crucialement, chaque direction n'est sondée qu'une seule fois, ce qui libère le budget limité de requêtes pour explorer beaucoup plus d'options au lieu de sur-affiner une unique hypothèse.
Surfer sur les variations lisses d'une image
Pour choisir des directions prometteuses, OPOQA s'appuie sur l'idée que les changements les plus efficaces et difficiles à voir sont souvent des variations lisses et globales plutôt que du bruit de pixels abrupt. La méthode utilise un outil mathématique appelé transformée en cosinus discrète pour passer l'image en vue « fréquence », où les variations lentes et douces occupent une zone compacte. Elle échantillonne aléatoirement quelques-uns de ces composants basse fréquence, les reconvertit en modifications de pixels ordinaires et les utilise comme directions de base pour l'exploration. Chaque direction échantillonnée aide à définir une surface bidimensionnelle plate reliant l'image d'origine, l'image adversariale actuelle et une nouvelle candidate. Sur chacune de ces surfaces, OPOQA choisit un point unique à tester, équilibrant deux objectifs : se rapprocher de l'image originale tout en ayant de bonnes chances de faire basculer la décision du modèle.

Choisir la meilleure candidate et s'adapter en temps réel
Une fois qu'OPOQA a généré un petit ensemble d'images candidates, elle mesure la distance de chacune à l'image originale et les trie de la moins modifiée à la plus modifiée. Elle interroge ensuite le modèle dans cet ordre. Dès qu'elle trouve une candidate que le modèle classe mal, elle s'arrête et traite cette image comme nouveau point de départ pour le tour suivant. Si aucune candidate ne parvient à tromper le modèle, OPOQA conserve la meilleure image adversariale précédente mais ajuste un paramètre interne qui contrôle si les prochains pas seront plus prudents ou plus agressifs. Cette stratégie « gourmande » — accepter toujours la meilleure image mal classée disponible et ajuster dynamiquement la taille des pas — permet à l'attaque de cibler des perturbations subtiles et efficaces sans gaspiller de requêtes sur des directions peu prometteuses.
Ce que les expériences révèlent sur les points faibles de l'IA
Les chercheurs ont testé OPOQA sur 200 images du grand jeu de données ImageNet et six modèles de réseaux neuronaux largement utilisés, dont Inception-v3, ResNet, VGG, DenseNet et des vision transformers. Sous une contrainte stricte de 1 000 requêtes au modèle par image, OPOQA a égalé ou dépassé plusieurs méthodes d'attaque de pointe. Par exemple, sur Inception-v3 elle a réussi à tromper le modèle sur 94 % des images tout en conservant des modifications si faibles qu'elles étaient presque invisibles à l'œil humain, améliorant la meilleure méthode précédente de plusieurs points de pourcentage. Selon les modèles, OPOQA tendait à atteindre des taux de succès élevés plus tôt — en utilisant moins de requêtes — bien que certaines méthodes concurrentes le rattrapent ou le surpassent lorsqu'on leur accorde des budgets de requêtes très élevés et du temps pour un affinage fin.
Ce que cela signifie pour la sécurité de l'IA au quotidien
Cette étude montre que les systèmes visuels actuels peuvent être trompés même lorsque les attaquants ne voient que des décisions finales et disposent de peu d'opportunités pour sonder le modèle. En explorant intelligemment des changements doux et basse fréquence et en rationnant soigneusement chaque requête, OPOQA peut créer des images qui paraissent identiques aux humains mais qui induisent les machines en erreur. Pour le grand public, la leçon est que la « vision » des IA reste assez fragile : elle peut être déviée de façon subtile et difficile à remarquer. Reconnaître et étudier de telles attaques efficaces est une étape clé pour renforcer les systèmes du monde réel — tels que les caméras de sécurité, les outils d'imagerie médicale et les véhicules autonomes — contre des manipulations qui pourraient autrement passer inaperçues.
Citation: Tuo, Y., Yin, M. & Che, S. Query-efficient decision-based adversarial attack with low query budget. Sci Rep 16, 6886 (2026). https://doi.org/10.1038/s41598-026-38428-4
Mots-clés: exemples adversariaux, attaques boîte noire, sécurité de l'apprentissage profond, classification d'images, attaque efficace en requêtes