Clear Sky Science · fr
MDI-YOLO : un modèle léger de fusion de caractéristiques multidimensionnelles basé sur transformer-CNN pour la détection d’objets de petite taille
Des yeux plus aiguisés dans le ciel
De la surveillance du trafic à la gestion des catastrophes, les drones et les satellites surveillent de plus en plus notre monde. Pourtant, ce qui nous intéresse le plus dans ces images — petites voitures, personnes, bateaux et aéronefs — apparaît souvent comme un simple ensemble de pixels. L’article sur MDI‑YOLO aborde une question simple mais cruciale : comment faire en sorte que des ordinateurs repèrent de manière fiable ces tout petits objets en temps réel, même sur des dispositifs peu puissants embarqués sur les drones ?
Pourquoi les petits objets sont difficiles à détecter
Dans les vues aériennes et satellitaires, les objets d’intérêt sont généralement très petits, souvent serrés les uns contre les autres et partiellement masqués par des bâtiments, des arbres ou des ombres. Les systèmes de détection classiques font face à un compromis : les modèles légers s’exécutent rapidement sur des dispositifs en périphérie comme les ordinateurs embarqués de drones mais manquent de nombreux petits objectifs ; les modèles plus lourds et plus précis sont trop lents et gourmands en ressources pour être pratiques sur le terrain. Les petits objets ont aussi tendance à se fondre dans des arrière‑plans complexes — pensez à des voitures grises sur des routes grises — si bien que leurs caractéristiques distinctives peuvent facilement disparaître lors de la compression des images et du traitement par des réseaux profonds.
Un nouvel équilibre entre vision globale et locale
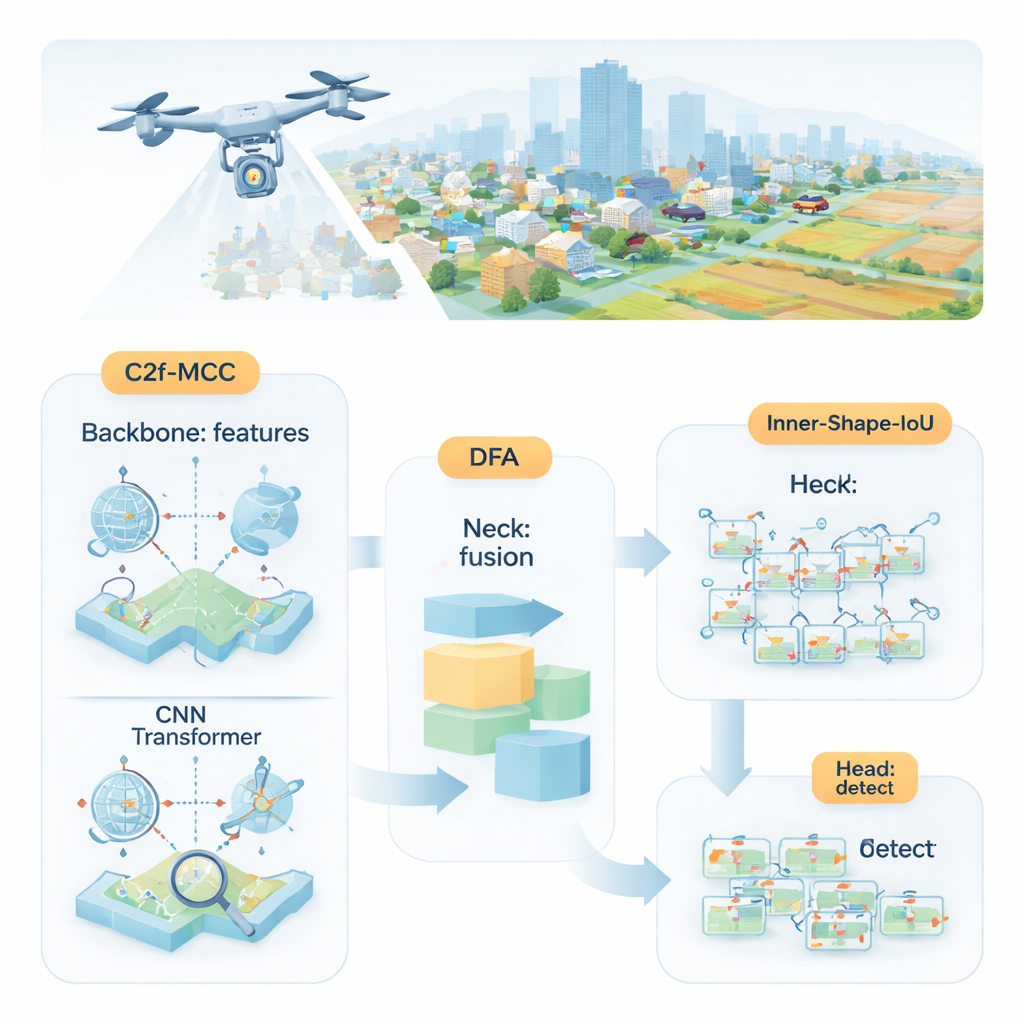
Les chercheurs proposent MDI‑YOLO, une version repensée du détecteur populaire YOLOv8 qui conserve la compacité du modèle tout en affinant sa capacité à repérer les cibles minuscules. Au cœur se trouve un nouveau bloc appelé C2f‑MCC, qui divise l’information visuelle circulant dans le réseau en deux voies. Une voie utilise un traitement de type Transformer, efficace pour capter des relations à longue portée à travers l’image entière — par exemple la façon dont un groupe de pixels s’inscrit dans une route ou une piste plus vaste. L’autre voie conserve des filtres convolutionnels classiques, excellents pour extraire des détails locaux comme des contours et des textures. En regroupant les canaux et en envoyant seulement une partie des données par la voie Transformer plus lourde, le modèle gagne en conscience globale sans gonfler en taille ni ralentir.
Aider le réseau à se concentrer sur l’essentiel
Même avec de meilleurs blocs de construction, le réseau doit encore décider où porter son attention. Pour guider cela, les auteurs introduisent un mécanisme appelé Directional Fusion Attention (DFA). Ce module analyse les motifs le long de la largeur et de la hauteur de l’image, ainsi qu’un résumé global de la scène, et apprend à pondérer différentes régions et canaux de caractéristiques. En pratique, DFA encourage le modèle à se concentrer sur les zones susceptibles de contenir des objets — comme des formes évoquant des véhicules sur les routes — et à atténuer les textures d’arrière‑plan répétitives ou déroutantes. Cette combinaison d’attention spatiale et par canal facilite la séparation des petites cibles d’un environnement encombré ou de régions de fond à apparence similaire.
Des boîtes plus précises autour des minuscules cibles
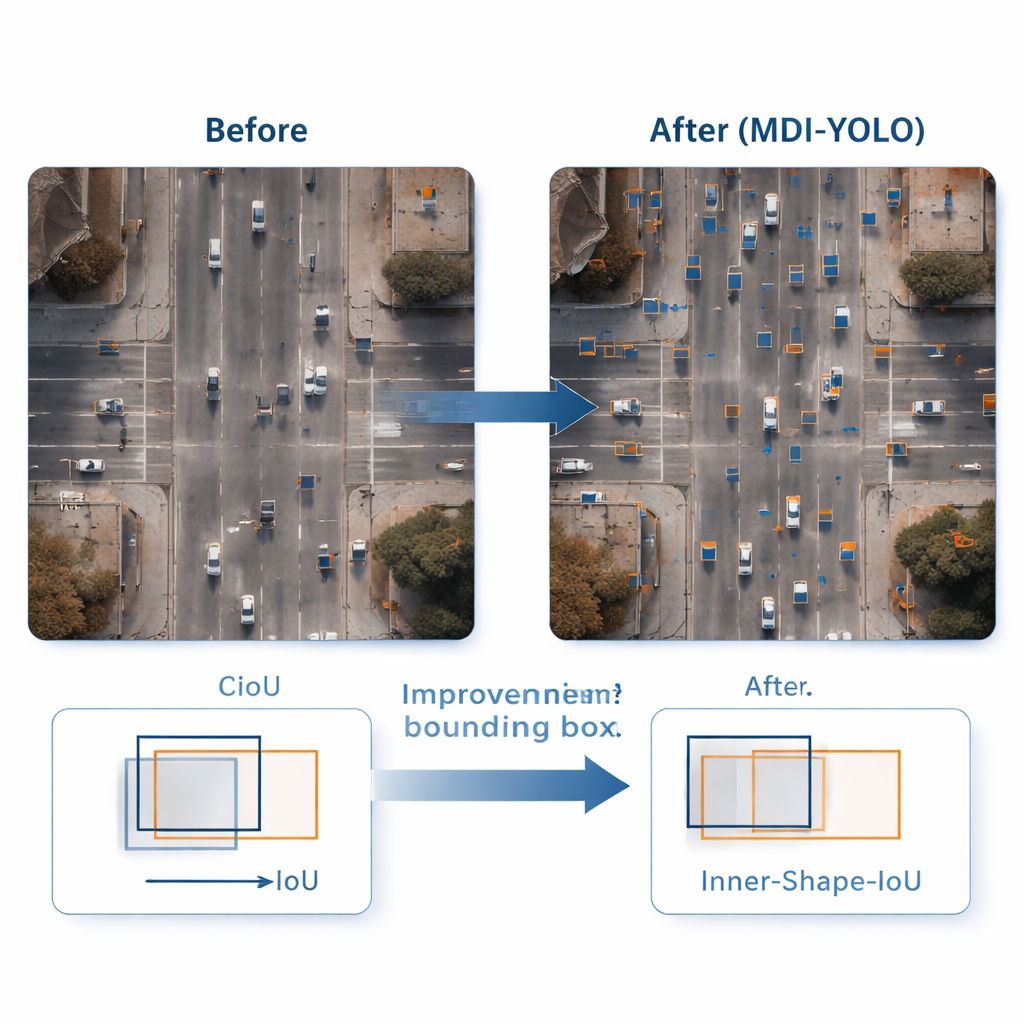
Repérer un objet ne suffit pas ; le détecteur doit aussi l’encadrer avec précision. Les méthodes d’entraînement standard comparent les rectangles prédits aux rectangles vrais via un score de « recouvrement », mais cela peut manquer de sensibilité quand les objets sont petits ou de forme étrange. Les auteurs conçoivent une nouvelle fonction de perte, Inner‑Shape‑IoU, qui évalue les boîtes non seulement par leur recouvrement, mais aussi par la concordance de leur forme, taille et région centrale avec l’objet réel. En combinant deux mesures complémentaires, elle pénalise les boîtes qui ne correspondent qu’aux bords tout en manquant le cœur de la cible, ce qui conduit à des contours plus précis — en particulier pour les objets petits, denses ou allongés.
Des gains démontrés sans surcharge
Pour évaluer MDI‑YOLO, l’équipe a réalisé des expériences sur deux bancs d’essai publics exigeants : VisDrone2019, qui contient des séquences de drones en milieu urbain et de trafic, et DOTAv1.0, une large collection de scènes aériennes avec de nombreux petits objets fortement groupés. Sans recourir à des modèles pré‑entraînés, MDI‑YOLO a amélioré les scores d’exactitude standard de plusieurs points de pourcentage par rapport à la base YOLOv8 tout en conservant un nombre de paramètres quasiment inchangé et en maintenant des temps d’inférence rapides. Comparé à une gamme de détecteurs populaires — des variantes légères de YOLO aux systèmes basés sur Transformer plus lourds — il propose une combinaison rare de haute précision, de faible coût computationnel et de robustesse à travers différentes scènes.
Ce que cela signifie pour l’usage réel
Pour un public non spécialiste, la conclusion est que MDI‑YOLO offre aux drones et aux systèmes de télédétection des « yeux » plus nets et plus fiables sans exiger d’ordinateurs volumineux et énergivores. En mêlant intelligemment contexte global, détails locaux, attention ciblée et une méthode d’entraînement plus exigeante pour les boîtes englobantes, la méthode facilite la détection des petits objets importants pour la sécurité, la surveillance et la cartographie. Ce type de vision efficace et haute précision est une étape clé vers des plateformes aériennes plus intelligentes, capables d’opérer de façon autonome, de réagir rapidement et d’être largement déployées sur le terrain.
Citation: Shi, H., Wu, Y., Xu, Y. et al. MDI-YOLO a lightweight transformer-CNN-based multidimensional feature fusion model for small object detection. Sci Rep 16, 7233 (2026). https://doi.org/10.1038/s41598-026-38378-x
Mots-clés: imagerie par drone, détection d’objets de petite taille, télédétection, YOLO, vision par ordinateur