Clear Sky Science · fr
Méthode robuste basée sur l’imputation pour prédire la couleur des yeux, des cheveux et de la peau à partir d’ADN ancien à faible couverture
Voir les visages derrière l’ADN ancien
Lorsque les archéologues exhument des ossements anciens, ils savent rarement à quoi ressemblaient ces personnes de leur vivant — quelle était la couleur de leurs yeux, la teinte de leur peau ou si leurs cheveux étaient noirs, blonds ou roux. Cette étude présente une nouvelle façon de lire ces traits visibles à partir d’ADN extrêmement dégradé, permettant aux scientifiques de dresser un portrait plus humain d’individus du passé lointain et d’appliquer les mêmes idées à des échantillons médico-légaux dégradés aujourd’hui.
Pourquoi l’ADN ancien est si difficile à lire
L’ADN provenant de restes enfouis depuis longtemps est un chantier biologique. Le temps le fragmente en minuscules fragments et y introduit des altérations chimiques qui transforment une lettre génétique en une autre. La plupart des génomes anciens sont séquencés à « faible couverture », ce qui signifie que de nombreuses positions sont lues une seule fois — ou pas du tout. Les outils médico-légaux existants, comme HIrisPlex-S, qui prédit la couleur des yeux, des cheveux et de la peau à partir de 41 marqueurs clés de l’ADN, ont été conçus pour de l’ADN moderne et de haute qualité et s’attendent à des informations fiables sur les deux copies de chaque marqueur. Avec du matériel ancien, ces informations sont souvent manquantes ou incertaines, si bien que les méthodes traditionnelles échouent complètement ou fournissent des prédictions très fragiles.
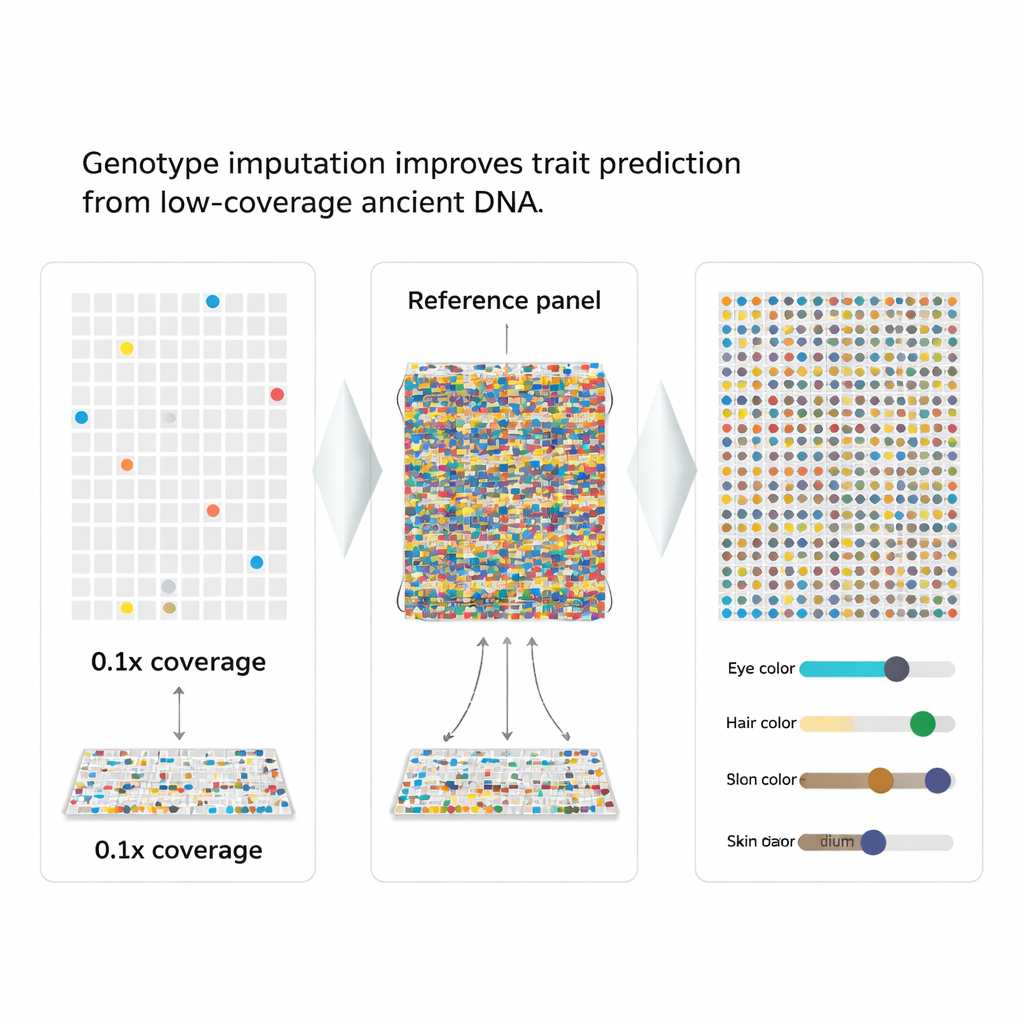
Combler les lacunes par une estimation intelligente
Les auteurs ont recours à une stratégie appelée imputation de génotype, qui utilise les motifs présents dans un grand panel de référence de génomes modernes pour « combler » les pièces manquantes d’un génome abîmé. Parce que des marqueurs génétiques voisins sont hérités ensemble en blocs, un motif partiellement observé peut fortement indiquer les lettres manquantes les plus probables. L’équipe a intégré cette idée dans un nouveau flux de travail, aHISplex, qui part des lectures d’ADN alignées, exécute un logiciel d’imputation de pointe, convertit les résultats au format exact requis par HIrisPlex-S, puis transforme automatiquement les probabilités prédites en catégories claires pour la couleur des yeux, des cheveux et de la peau.
Tester la précision sur des individus modernes et anciens
Pour évaluer les performances de la méthode, les chercheurs ont pris 93 génomes modernes avec des traits connus et les ont « sous-échantillonnés » artificiellement pour simuler une très faible couverture, aussi faible qu’un dixième d’une lecture complète. Ils ont ensuite imputé les marqueurs manquants et comparé les résultats aux données véritables. Même à seulement 0,5× de couverture, le taux d’erreur global pour les 41 marqueurs restait inférieur à environ 2 %, et les erreurs les plus graves — inverser complètement un marqueur d’un état homozygote à l’autre — étaient extrêmement rares. La plupart des prédictions de couleur des yeux et des cheveux correspondaient aux traits connus, et les prédictions de couleur de peau ne basculaient que légèrement entre des catégories de teintes voisines.
Défis liés aux traits rares et à la diversité ancienne
Tous les traits ne sont pas également faciles à retrouver. Les cheveux roux, largement déterminés par des variants rares du gène MC1R, se sont avérés plus difficiles : la méthode n’inventait presque jamais des cheveux roux là où ils n’existaient pas, mais manquait parfois de vrais individus roux, les classant plutôt comme blonds ou châtain clair. L’équipe a également appliqué son flux de travail à 31 individus véritablement anciens équipés de génomes de haute qualité, puis a simulé une faible couverture et les a réimputés. Là encore, la précision globale était élevée, avec environ 95 % des marqueurs clés correctement imputés à 0,5× de couverture. Cependant, un petit ensemble de combinaisons marqueur–échantillon, notamment chez des individus dont l’origine génétique est peu représentée dans les panels de référence modernes, présentait systématiquement un taux d’erreur plus élevé. Ce « biais de référence » pouvait, par exemple, transformer un génotype associé à des yeux bleus en une prédiction d’yeux bruns dans une fraction des simulations.
Faire ressortir les personnes anciennes
Malgré ces réserves, l’étude montre qu’il est désormais pratique de prédire la couleur des yeux, des cheveux et de la peau pour de nombreux individus anciens même lorsque leur ADN est extrêmement parcellaire, à seulement 0,1–0,5× de couverture. Le nouveau pipeline aHISplex automatise les étapes complexes entre les fichiers de séquençage bruts et des classifications de traits accessibles, le rendant utilisable par des laboratoires d’archéogénétique et potentiellement par des équipes médico-légales traitant des échantillons dégradés. À mesure que les panels de référence s’enrichiront en génomes plus divers et anciens, et que les scientifiques découvriront d’autres marqueurs liés aux traits, cette approche devrait gagner en précision — nous aidant à passer d’ossements et de séquences d’ADN anonymes à des portraits vivants et éthiquement réfléchis de personnes ayant vécu il y a longtemps.
Citation: Maróti, Z., Nyerki, E., Török, T. et al. Robust imputation-based method for eye, hair, and skin colour prediction from low-coverage ancient DNA. Sci Rep 16, 7371 (2026). https://doi.org/10.1038/s41598-026-38372-3
Mots-clés: ADN ancien, phénotypage médico-légal, couleur des yeux cheveux peau, imputation de génotype, archéogénétique