Clear Sky Science · fr
Allocation de ressources aidée par jumeau numérique via l’imitation générative adversariale dans des scénarios complexes cloud-edge-end
Des autoroutes de données plus intelligentes pour l’Internet des objets
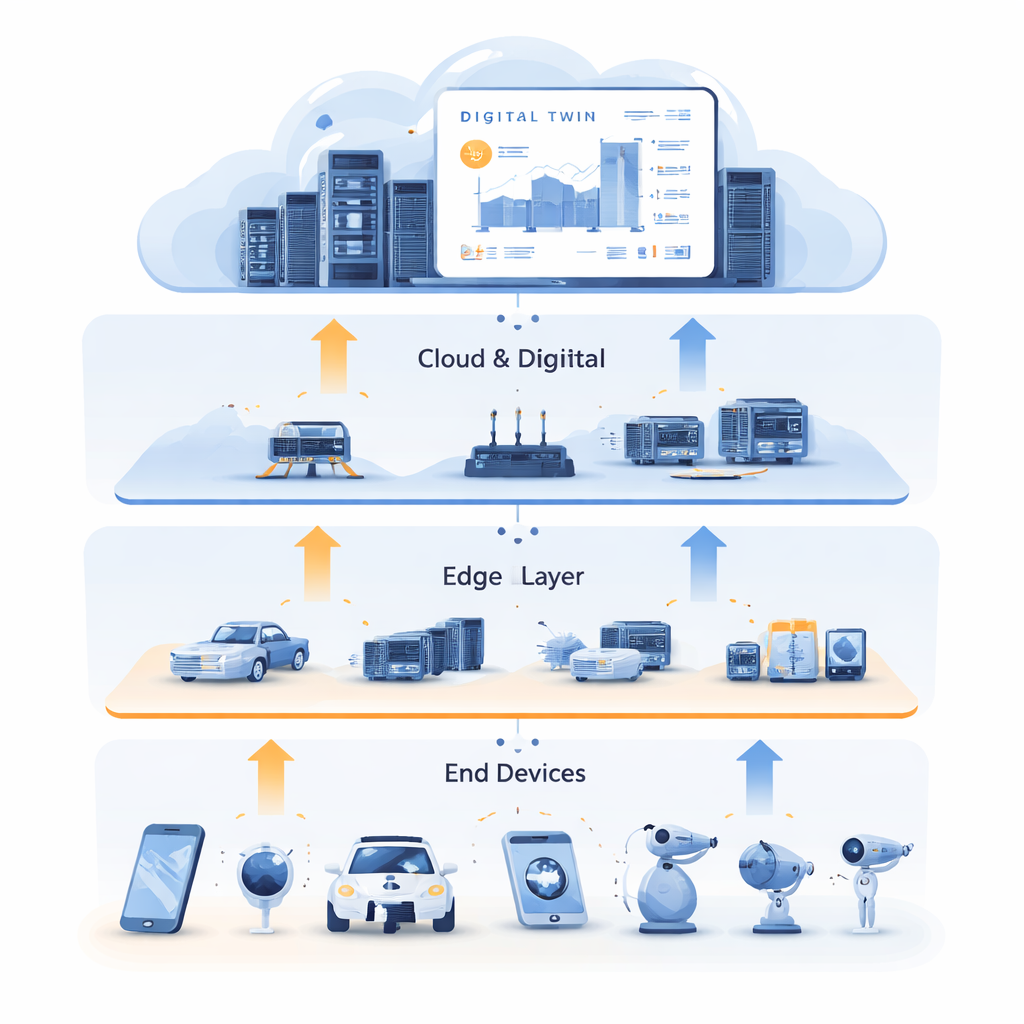
À mesure que villes, usines et domiciles se remplissent de capteurs et d’appareils connectés, ils génèrent des torrents de données qui doivent être traités rapidement et de manière fiable. Tout envoyer vers des serveurs cloud éloignés peut être trop lent, tandis que les petits appareils en périphérie manquent souvent de puissance de calcul. Cet article explore une nouvelle façon de router automatiquement et d’allouer calcul, stockage et ressources réseau entre les appareils, les serveurs edge proches et le cloud — afin que les applications intelligentes restent rapides et robustes même lorsque les conditions réelles sont désordonnées et imprévisibles.
Pourquoi les méthodes actuelles peinent
Les systèmes modernes s’appuient souvent sur l’apprentissage par renforcement profond, où un algorithme apprend par essai-erreur en s’appuyant sur des signaux de récompense provenant de l’environnement. Dans des réseaux complexes et bruités, ces récompenses sont cependant difficiles à définir et à mesurer. Si la fonction de récompense est incorrecte ou déformée par des interférences, le système peut apprendre des comportements dangereux ou inefficaces. Beaucoup de méthodes existantes supposent aussi une connaissance préalable riche des profils de trafic et du comportement des appareils, ce qui est rarement disponible dans des réseaux industriels en production. De plus, la plupart des solutions optimisent un seul type de ressource à la fois — par exemple la puissance de calcul — en négligeant le stockage ou la bande passante, alors que les trois déterminent conjointement les performances réelles.
Apprendre à partir d’un double numérique
Pour déverrouiller cette impasse, les auteurs combinent l’allocation de ressources avec la technologie du Jumeau Numérique. Un jumeau numérique est une réplique virtuelle détaillée du réseau physique, hébergée dans le cloud. Il reflète l’état des serveurs edge, des liens et des tâches au fil du temps, en s’appuyant sur des données historiques riches issues de capteurs et de journaux. Dans ce travail, le jumeau numérique n’est pas qu’un tableau de bord ; il devient un terrain d’entraînement. Le système utilise des données passées pour générer des exemples « experts » de bonnes décisions, capturant comment les tâches doivent être réparties entre calcul et mise en cache, et où elles doivent être traitées pour minimiser la latence. Cet entraînement se fait hors ligne, sans perturber les services en direct, et exploite l’abondante puissance de calcul du cloud pour explorer de nombreuses situations possibles.
Imiter plutôt qu’apprendre par essais-erreurs
Plutôt que d’apprendre directement à partir de récompenses, le modèle proposé E‑GAIL adopte l’apprentissage par imitation : l’agent s’efforce de se comporter comme un expert. D’abord, les auteurs construisent plusieurs politiques expertes en utilisant un cadre Actor–Critic renforcé par une couche NoisyNet. L’injection d’un bruit soigneusement contrôlé dans le réseau de décision permet à ces experts d’expérimenter une grande variété de conditions — y compris des perturbations mimant les interférences radio réelles et des charges de travail fluctuantes — rendant leurs trajectoires plus réalistes. Ensuite, le système fusionne plusieurs trajectoires mono-expertes en une référence « multi-experte » unique en utilisant des outils de théorie des jeux. En recherchant un équilibre de Nash entre les experts, il évite les conflits entre eux et produit une stratégie consensuelle couvrant un plus large éventail de scénarios possibles.
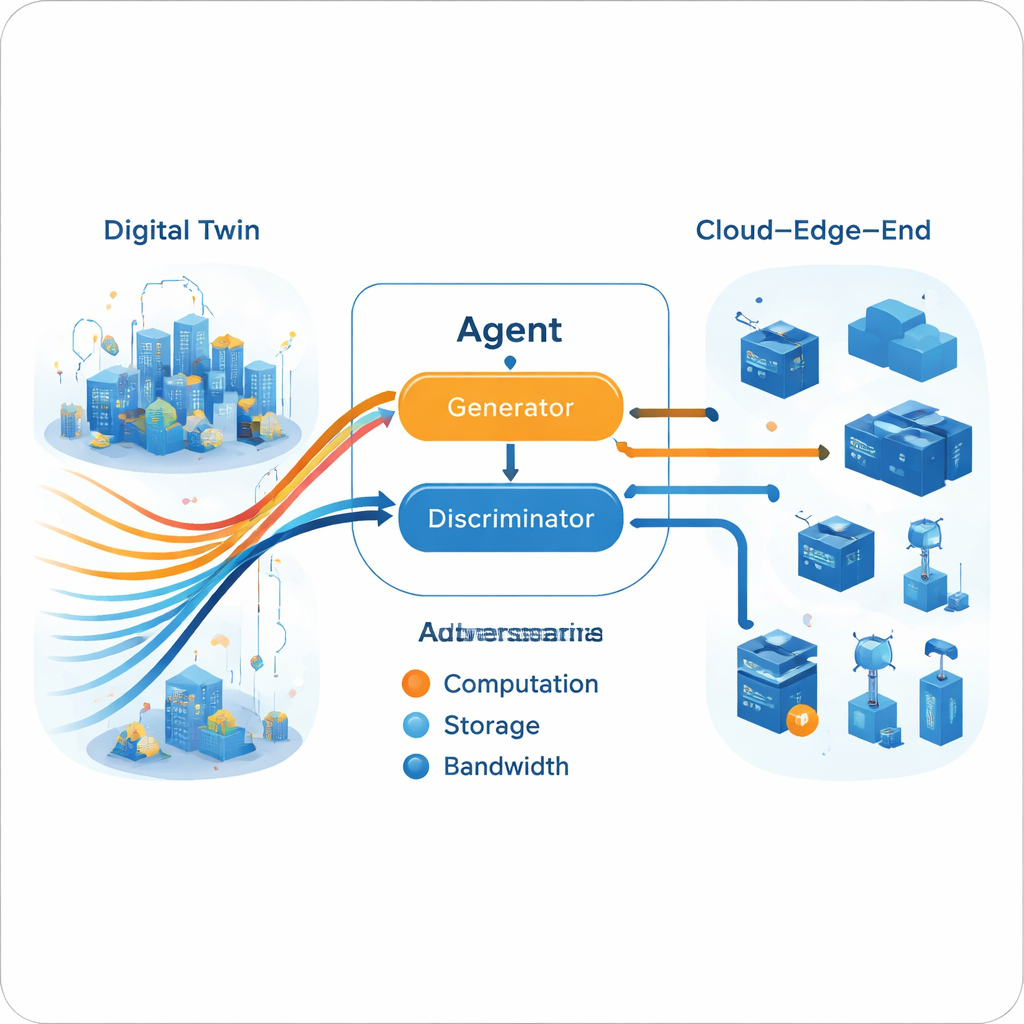
Un moteur génératif adversarial pour les décisions
Une fois la trajectoire multi-experte construite dans le jumeau numérique, l’agent en production apprend à l’imiter via une configuration générative adversariale, analogue aux réseaux neuronaux générateurs d’images. Un générateur propose des actions d’allocation de ressources en fonction de l’état actuel du réseau, tandis qu’un discriminateur tente de déterminer si une séquence d’actions provient de l’agent ou des trajectoires expertes. Au fil du temps, ce jeu adversarial pousse le générateur à produire des décisions que le discriminateur ne peut plus distinguer du comportement expert. Fondamentalement, ce processus n’exige pas de fonction de récompense explicite fournie par l’environnement réel. L’entraînement est scindé : un apprentissage intensif hors ligne (dans le cloud) affine les experts et le générateur, tandis que des mises à jour plus légères en ligne (à la périphérie) maintiennent le modèle aligné sur les conditions actuelles, respectant les limites pratiques du matériel edge.
Quel est le niveau de performance ?
Les auteurs testent E‑GAIL face à plusieurs références populaires, incluant le deep Q‑learning, le déchargement basé sur la théorie des jeux, des heuristiques gourmandes, un traitement cloud-only et une allocation aléatoire. Sur de nombreuses expériences — en variant le nombre de terminaux, les canaux, les mélanges de tâches, les charges, les tailles de données, les distances et les profils de bruit — E‑GAIL obtient systématiquement des délais de bout en bout très proches de ceux de la politique experte et sensiblement meilleurs que les autres méthodes automatisées. Il s’adapte bien lorsque les tâches passent d’un profil intensif en calcul à un profil intensif en stockage, lorsque le réseau s’agrandit ou lorsque les interférences s’intensifient. Le jumeau numérique accélère la génération des trajectoires expertes et améliore leur qualité, tandis que la fusion multi-experte élargit les scénarios que l’agent peut gérer sans nécessiter un réentraînement complet.
Ce que cela signifie pour les systèmes quotidiens
Pour un non-spécialiste, le message essentiel est que cette approche permet aux réseaux de se gérer de façon plus intelligente face à l’incertitude. Au lieu de concevoir des règles à la main ou de s’en remettre à un apprentissage par essais-erreurs fragile, E‑GAIL apprend à partir d’expériences simulées riches fournies par un jumeau numérique et à partir de plusieurs « experts » aguerris dont les conseils sont réconciliés mathématiquement. Le résultat est un répartiteur de ressources capable de décider rapidement où exécuter les tâches et où stocker les données, en maintenant des temps de réponse faibles même quand les conditions changent. Dans les futurs systèmes industriels et de villes intelligentes, de tels coordinateurs auto‑enseignés pourraient discrètement jongler avec calcul, stockage et bande passante en arrière-plan, rendant notre monde connecté plus rapide, plus fiable et plus économe en énergie.
Citation: Zhang, X., Xin, M., Li, Y. et al. DT-aided resource allocation via generative adversarial imitation learning in complex cloud-edge-end scenarios. Sci Rep 16, 7657 (2026). https://doi.org/10.1038/s41598-026-38367-0
Mots-clés: jumeau numérique, informatique en périphérie, apprentissage par imitation, allocation de ressources, Internet industriel des objets