Clear Sky Science · fr
Une méthode de fusion d’amélioration d’images visibles et infrarouges de bout en bout multi-échelle
Vision nocturne plus nette pour les humains et les machines
Quiconque a essayé de prendre une photo la nuit sait à quelle vitesse l’obscurité efface les détails : les scènes paraissent granuleuses, floues et aux couleurs étranges. Pourtant, de nombreuses technologies critiques — des caméras routières et de sécurité domestique aux véhicules autonomes et aux drones de secours — doivent voir clairement précisément dans ces conditions. Cet article présente une nouvelle façon de combiner des caméras couleur ordinaires et des caméras « chaleur » infrarouges pour que les ordinateurs, et in fine les personnes, obtiennent des vues lumineuses et détaillées du monde même en quasi-obscurité.
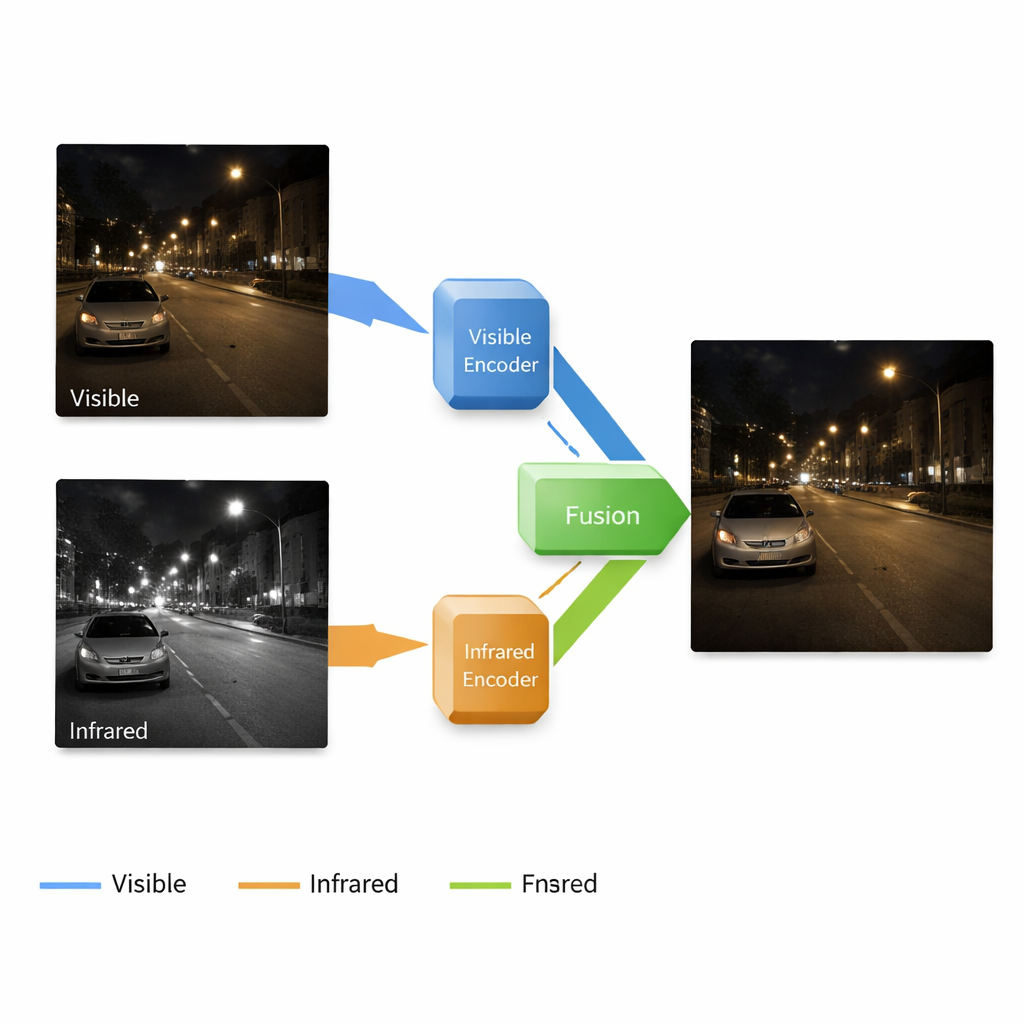
Pourquoi deux types de caméras valent mieux qu’une
Les caméras classiques captent le même type de lumière que nos yeux, ce qui rend leurs images faciles à interpréter pour les humains, mais elles échouent quand la lumière manque : les ombres engloutissent les détails, le bruit apparaît et les couleurs se décalent. Les caméras infrarouges font l’inverse : elles perçoivent les motifs de chaleur, révélant personnes, animaux et véhicules dans l’obscurité ou à travers une légère brume, mais leurs images manquent de textures fines et d’apparence naturelle. Les chercheurs ont depuis longtemps cherché à fusionner ces deux visions en une seule image qui ressemble à une photo couleur claire tout en révélant les objets chauds cachés. Les méthodes existantes traitent souvent chaque étape — éclaircissement des images sombres, réduction du bruit et intégration des informations infrarouges — comme des tâches séparées. Cette approche fragmentée peut provoquer des incohérences et des résultats de fusion décevants.
Une seule chaîne qui éclaire et fusionne
Les auteurs proposent un système de bout en bout qui améliore et fusionne les images dans un pipeline continu. Il s’appuie sur un réseau neuronal à quatre composantes principales : une branche apprend à nettoyer et éclaircir les images couleur en faible luminosité, une autre apprend à représenter la scène depuis la caméra infrarouge, un bloc de fusion combine ce que chaque branche a appris, et un décodeur reconstruit une image finale à partir de ces signaux mêlés. Fait important, le système fonctionne à plusieurs échelles, des formes grossières jusqu’aux textures fines. Les couches peu profondes préservent les arêtes et les détails de surface comme les briques ou les marquages routiers, tandis que les couches profondes captent des structures plus larges — bâtiments, voitures ou arbres — ainsi que la localisation des cibles chaudes dans l’image infrarouge.
Trois phases d’apprentissage plutôt qu’un seul saut
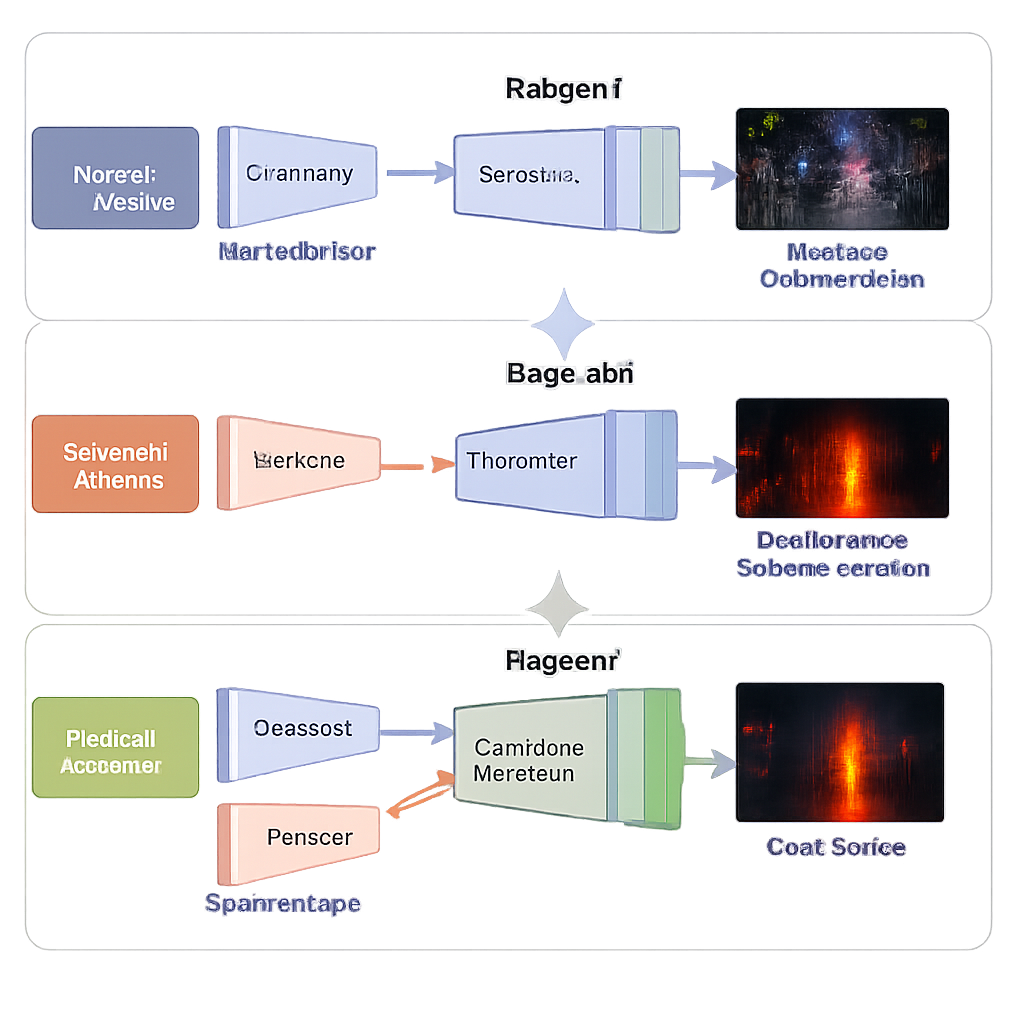
Plutôt que d’entraîner l’ensemble du système d’un seul coup, l’équipe utilise une stratégie d’apprentissage en trois étapes conçue pour la stabilité et la précision. Dans la première étape, le réseau ne voit que des photos en faible luminosité et apprend à les éclaircir sans référence « parfaite » fournie par l’humain. Des termes de perte soigneusement choisis poussent la sortie à présenter une luminosité naturelle, des couleurs stables, des régions lisses sans taches de bruit et une texture préservée. Dans la deuxième étape, le même décodeur est réutilisé pendant qu’une nouvelle branche infrarouge apprend à reconstruire fidèlement les images infrarouges, enseignant au réseau l’apparence attendue des motifs de chaleur. Dans la troisième étape, ces éléments appris sont gelés, et seul le bloc de fusion est entraîné pour mélanger les deux représentations en une image unique de haute qualité, à la fois lumineuse et riche en informations.
Mise à l’épreuve de la méthode
Les chercheurs ont évalué leur approche sur des jeux de données publics contenant des paires d’images visibles et infrarouges prises dans des conditions d’éclairage difficiles, comme des rues la nuit. Ils ont comparé leur méthode à plusieurs techniques de fusion de pointe, y compris celles basées sur des transformées d’images classiques, des réseaux convolutifs standards et des modèles génératifs plus complexes. Leur approche a généralement fourni des détails plus nets, une luminosité plus homogène et des cibles thermiques plus claires, tout en obtenant de meilleurs scores sur des mesures quantitatives de contenu informatif, de netteté des contours, de similarité structurelle et de contraste. Des expériences supplémentaires, où ils ont retiré sélectivement des composants clés du système, ont montré que chaque partie — le bloc de fusion multi-échelle, l’entraînement en étapes et le poids adaptatif des caractéristiques visibles versus infrarouges — contribue de manière mesurable à la qualité finale.
Qu’est-ce que cela signifie pour les systèmes de vision réels
Pour le grand public, la conclusion est simple : ce travail montre qu’un seul réseau soigneusement entraîné peut à la fois éclaircir des scènes sombres et fusionner intelligemment vues de chaleur et vues couleur en une image cohérente. Les images fusionnées conservent les textures fines tout en mettant en évidence les objets chauds, les rendant bien plus utiles pour des tâches telles que la surveillance nocturne, l’assistance à la conduite et la réalité augmentée ou virtuelle en environnements peu éclairés. Bien que les auteurs signalent des problèmes restants — comme une réduction du contraste dans les régions très lumineuses et le besoin de modèles plus rapides et plus légers — leur approche constitue une avancée significative vers des systèmes de caméras qui voient de manière fiable dans l’obscurité, d’une façon naturelle et interprétable pour les utilisateurs humains.
Citation: Xin, Y., Huang, J., Sun, C. et al. A multi-scale end-to-end visible and infrared image enhancement fusion method. Sci Rep 16, 7135 (2026). https://doi.org/10.1038/s41598-026-38323-y
Mots-clés: amélioration d’images en faible luminosité, fusion d’images infrarouges, vision nocturne, imagerie multisenseur, vision par apprentissage profond