Clear Sky Science · fr
Élagage d'arbres en forêt et rééchantillonnage pour les problèmes de classes déséquilibrées
Pourquoi les cas rares comptent dans les prédictions intelligentes
Beaucoup de décisions assistées par l’intelligence artificielle reposent sur la détection d’un événement rare : une opération bancaire frauduleuse, un signe précoce de maladie ou une panne dangereuse dans une machine. Dans ces situations, les cas importants sont largement dépassés en nombre par les cas ordinaires, et la plupart des algorithmes d’apprentissage ont tendance à les négliger. Cet article présente une façon de rendre une méthode populaire, les forêts aléatoires, beaucoup plus attentive à ces cas rares mais cruciaux — tout en allégeant et en accélérant le modèle.
Le problème des exemples inégaux
L’apprentissage automatique standard fonctionne mieux lorsque les données sont bien équilibrées — c’est‑à‑dire lorsqu’il y a un nombre à peu près similaire d’exemples pour chaque issue. Dans la réalité, toutefois, les événements rares dominent de nombreuses tâches. Par exemple, une petite fraction seulement des images médicales montre une tumeur, et une part très réduite des transactions est frauduleuse. Ce déséquilibre permet facilement à un algorithme d’avoir l’air performant sur le papier en prédisant la plupart du temps l’issue la plus courante, même s’il rate systématiquement le cas rare. À mesure que l’écart entre cas majoritaires et minoritaires s’accentue, la frontière de décision du modèle se déplace vers la majorité, et la classe rare devient plus difficile à reconnaître.
Rééquilibrer par un échantillonnage réfléchi
Les chercheurs cherchent souvent à rééquilibrer ces données avant d’entraîner les modèles. Une option consiste à réduire la classe majoritaire (sous‑échantillonnage), en supprimant des cas courants pour correspondre au nombre d’exemples rares. Une autre consiste à copier ou générer des exemples rares supplémentaires (sur‑échantillonnage), augmentant leur présence sans perdre de données originales. Une troisième approche hybride combine les deux idées, en coupant certains exemples majoritaires tout en enrichissant la minorité. Chaque tactique présente des compromis : la réduction risque d’éliminer des informations utiles, tandis que la duplication de nombreux exemples peut ralentir l’entraînement et provoquer un surapprentissage. Les auteurs utilisent ces trois stratégies pour créer des jeux d’entraînement plus équilibrés et adaptés aux données.
Apprendre et élaguer une forêt d’arbres de décision
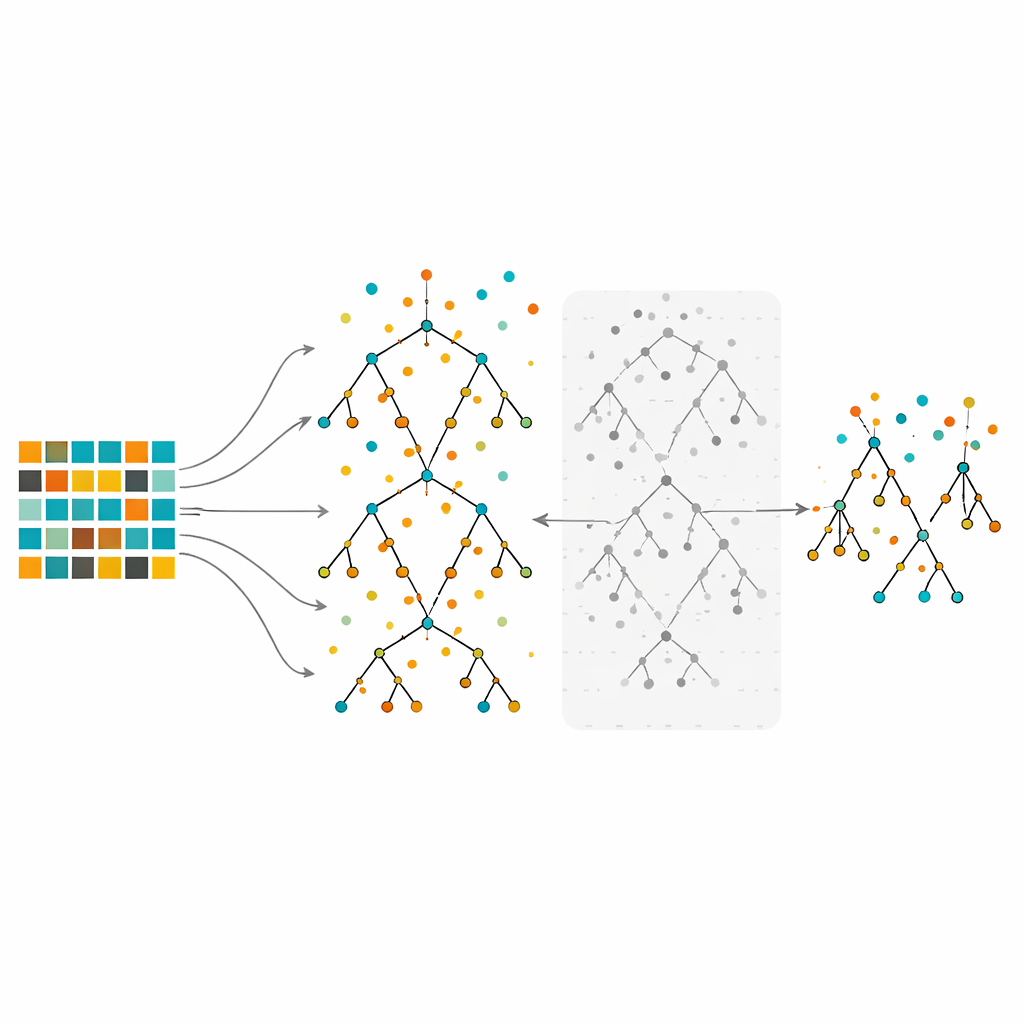
L’étude se concentre sur les forêts aléatoires, une méthode d’ensemble qui construit de nombreux arbres de décision sur des échantillons légèrement différents des données puis combine leurs votes. Les forêts aléatoires sont réputées pour gérer des données complexes et pour mettre en évidence les caractéristiques les plus importantes. Pourtant, entraînées sur des données fortement déséquilibrées, même de grandes forêts peuvent rester biaisées en faveur de la classe majoritaire. Dans la méthode proposée, les auteurs rééquilibrent d’abord les données en utilisant le sous‑échantillonnage, le sur‑échantillonnage ou l’approche hybride. Ils génèrent ensuite de nombreux arbres en suivant la procédure habituelle des forêts aléatoires, mais avec un ingrédient important : au lieu de conserver tous les arbres, ils évaluent chacun d’eux à l’aide des observations out‑of‑bag — les points de données qui n’ont pas servi à construire cet arbre — et éliminent la moitié ayant les pires taux d’erreur. Cette étape d’élagage produit une forêt plus petite et plus sélective, composée des arbres les plus fiables.
Tests sur de nombreux jeux de données réels
Pour mesurer les performances de cette forêt élaguée, les auteurs la testent sur dix jeux de données publics couvrant un large éventail d’applications, des mesures médicales et biologiques au filtrage de courriels indésirables et à la classification de sons. Chaque jeu de données comporte deux classes, l’une clairement plus rare que l’autre, et ils varient en taille, en nombre de caractéristiques et en degré de déséquilibre. La nouvelle méthode est comparée à plusieurs approches largement utilisées : k‑plus proches voisins, un arbre de décision unique, une forêt aléatoire standard, une variante Balanced Random Forest et des machines à vecteurs de support. Selon les différentes stratégies d’échantillonnage, la forêt élaguée obtient systématiquement des taux d’erreur de classification plus faibles que les alternatives sur la plupart des jeux de données. La combinaison d’un échantillonnage hybride et d’un élagage donne les meilleurs résultats globaux, tant en précision qu’en stabilité des performances à travers les dix tâches.
Des modèles plus affûtés qui gaspillent moins de ressources
Au‑delà de la précision, l’approche améliore aussi l’efficacité. En supprimant les arbres moins performants, l’ensemble final est plus petit et nécessite moins de calculs pour l’entraînement et pour effectuer des prédictions, sans sacrifier — et souvent en améliorant — sa capacité à détecter les cas rares. Des tests statistiques confirment que les gains par rapport aux méthodes concurrentes ne sont pas dus au hasard. Pour les praticiens confrontés à des données déséquilibrées, ce travail montre qu’un rééquilibrage soigné du jeu d’entraînement suivi d’un élagage de la forêt aléatoire basé sur la performance out‑of‑bag peut produire des modèles à la fois plus précis et plus efficaces. En termes simples, la méthode aide nos algorithmes à prêter la juste attention aux signaux rares mais importants qui se cachent au milieu d’une mer d’exemples ordinaires.
Citation: Faiz, N., Iftikhar, S., Jan, S. et al. Pruning tree forest and re-sampling for class imbalanced problem. Sci Rep 16, 8087 (2026). https://doi.org/10.1038/s41598-026-38320-1
Mots-clés: déséquilibre des classes, forêt aléatoire, rééchantillonnage, apprentissage automatique, méthodes d’ensemble