Clear Sky Science · fr
Apprentissage fédéré pour des systèmes de dossiers de santé électroniques hétérogènes avec sélection rentable des participants
Pourquoi il est si difficile de partager les données hospitalières
Les hôpitaux modernes recueillent d’énormes quantités d’informations numériques sur leurs patients, des analyses de laboratoire et signes vitaux aux médicaments et interventions. En théorie, combiner ces dossiers entre plusieurs établissements devrait permettre de construire des modèles informatiques plus performants pour prédire les risques et identifier les traitements les plus efficaces. En pratique toutefois, les hôpitaux utilisent des logiciels différents, stockent les données dans des formats incompatibles et doivent protéger strictement la confidentialité des patients et leurs budgets. Cette étude explore comment permettre aux hôpitaux d’apprendre les uns des autres sans copier les données ni dépasser les coûts.
S’entraîner ensemble sans partager les dossiers bruts
Les auteurs s’appuient sur une approche appelée apprentissage fédéré, où chaque hôpital entraîne un modèle local sur ses propres dossiers patients puis ne partage que des mises à jour de modèle, pas les données brutes. Un hôpital central « hôte » coordonne ce processus et cherche à améliorer un modèle de prédiction pour ses propres besoins, par exemple prévoir des complications en soins intensifs. D’autres hôpitaux, appelés sujets, participent en échange d’une compensation. Ce dispositif évite de transférer des dossiers sensibles entre établissements, mais pose deux défis : comment travailler avec des systèmes de dossiers très différents, et comment éviter de payer des partenaires qui n’aident pas réellement le modèle.
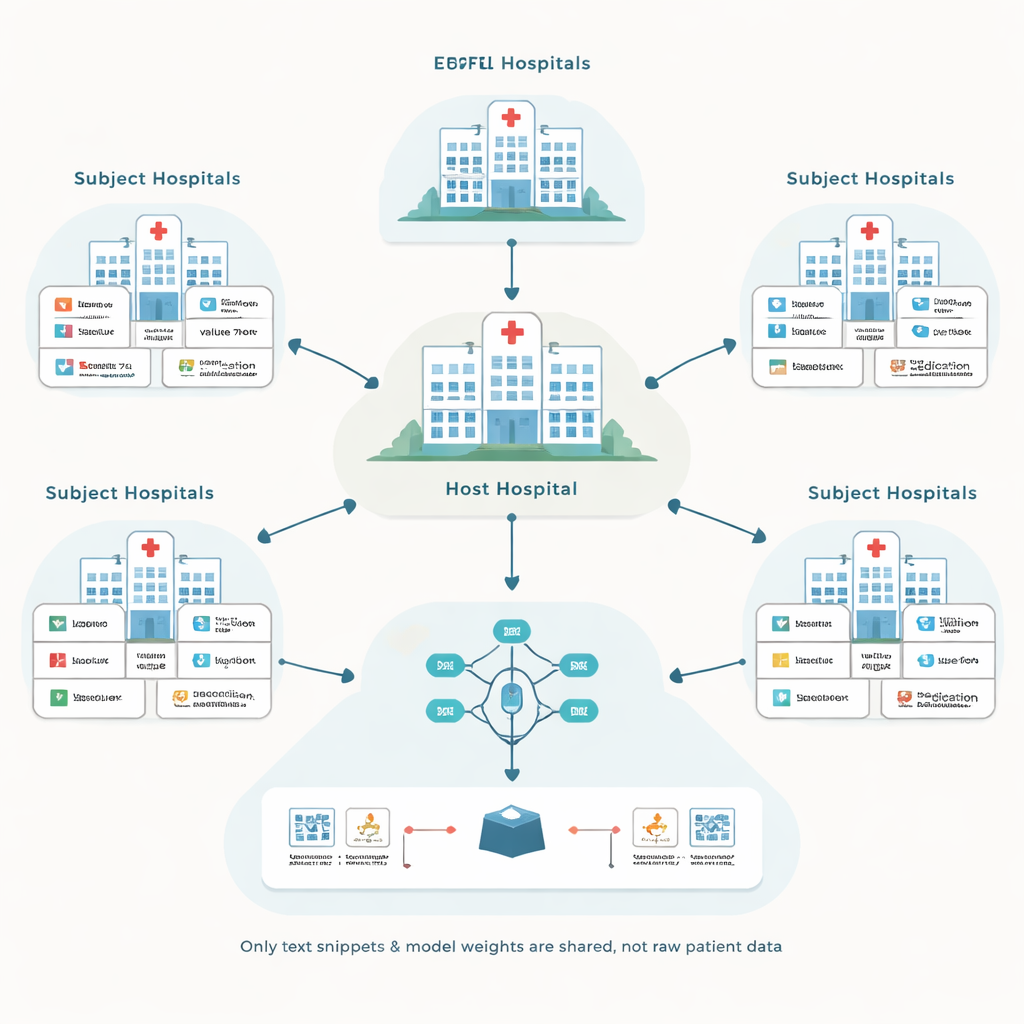
Transformer des dossiers disparates en langage commun
Les systèmes de dossiers de santé électroniques varient largement dans la façon dont ils libellisent et codent l’information. Un hôpital peut enregistrer un test de glycémie sous un code numérique tandis qu’un autre utilise un code différent pour le même test. Les solutions traditionnelles tentent de tout convertir dans une base de données standard soigneusement conçue, ce qui est coûteux et demande de nombreuses heures d’experts. À la place, le cadre proposé, appelé EHRFL, convertit chaque événement médical en un court morceau de texte. Par exemple, une entrée de laboratoire comme une glycémie devient une phrase telle que « événement laboratoire glycémie valeur 70 mg/dL ». Parce que chaque hôpital dispose déjà de dictionnaires qui associent les codes locaux à des noms lisibles, cette conversion peut être automatisée sans réglages manuels spécifiques.
Construire des profils patients à partir de texte
Une fois les événements rédigés en texte, EHRFL utilise des modèles modernes de traitement du langage pour transformer chaque événement en vecteur numérique, puis combine de nombreux événements en un unique « embedding patient » — un résumé compact de l’historique médical d’une personne sur une fenêtre temporelle. Ces embeddings alimentent une couche de prédiction qui s’attaque à plusieurs tâches cliniques simultanément, comme prédire le décès à l’hôpital ou une insuffisance rénale après une admission en soins intensifs. Les auteurs réalisent un entraînement fédéré sur cinq grands ensembles de données réelles de soins critiques couvrant différents hôpitaux, périodes et systèmes de dossiers. Sur une gamme d’algorithmes, y compris des méthodes fédérées courantes, les modèles entraînés avec cette approche basée sur le texte surpassent systématiquement les modèles entraînés sur un seul hôpital, malgré la diversité des formats de données.
Choisir les bons partenaires tout en protégeant la vie privée
Plus de partenaires hospitaliers n’équivalent pas toujours à de meilleurs résultats. Certains établissements ont des populations ou des schémas d’enregistrement si différents de l’hôte que leur inclusion peut ralentir l’entraînement ou dégrader légèrement les performances, tout en générant des coûts. Pour y remédier, les auteurs proposent une étape de sélection basée sur la similarité entre les embeddings patients moyens des hôpitaux. L’hôte entraîne d’abord un modèle sur ses propres données, partage les poids du modèle, et chaque hôpital candidat les utilise pour calculer des embeddings patients. Pour protéger la confidentialité, chaque sujet tronque les valeurs extrêmes de ses embeddings, les moyenne en un vecteur unique, puis ajoute un bruit aléatoire calibré avant d’envoyer uniquement cette moyenne bruitée à l’hôte. L’hôte compare sa propre moyenne avec celle de chaque sujet à l’aide de mesures simples de similarité et choisit uniquement les hôpitaux les plus proches pour rejoindre l’exécution fédérée complète.
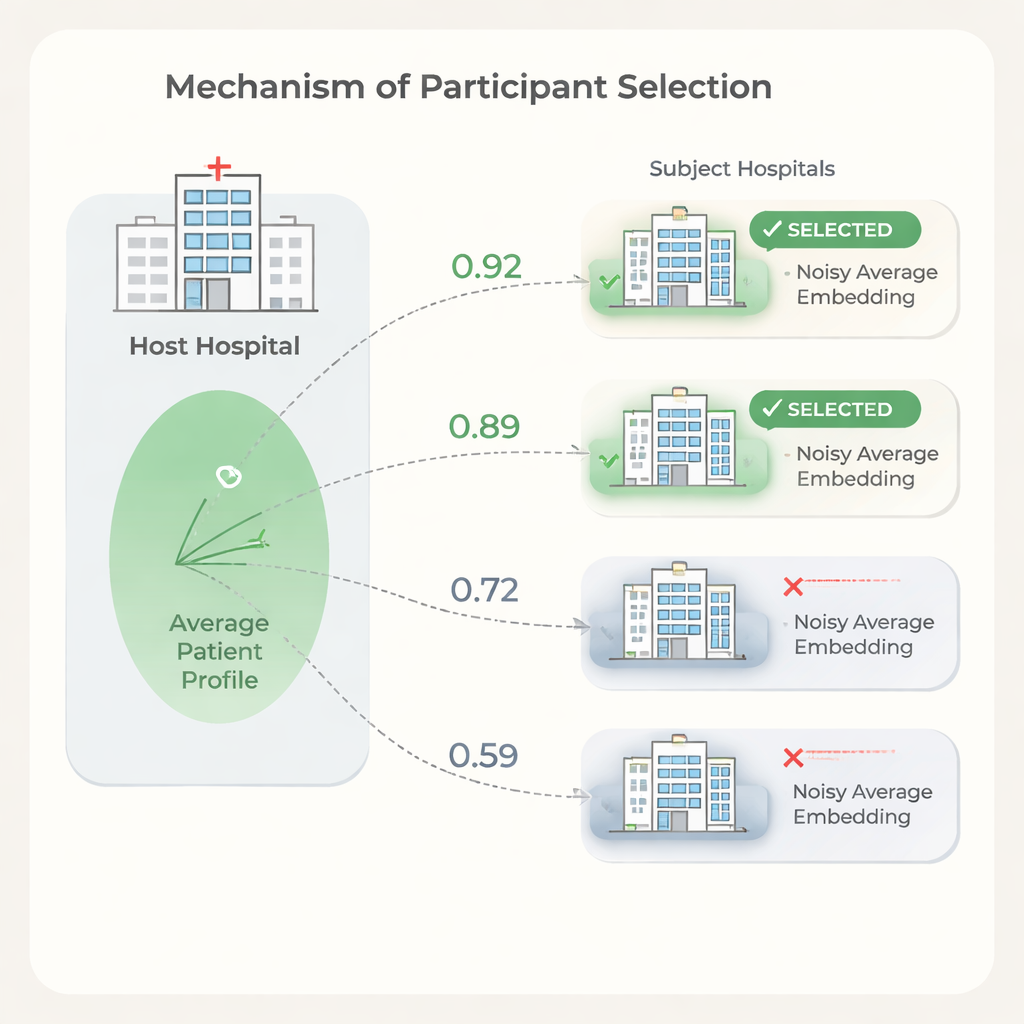
Économiser sans perdre en précision
Les expériences montrent que la similarité entre les embeddings patients moyens des hôpitaux s’aligne avec l’aide apportée par chacun à la performance de prédiction de l’hôte. En utilisant ce signal pour sélectionner des partenaires, l’hôte peut exclure les hôpitaux de faible similarité tout en conservant ou même en améliorant la qualité des prédictions par rapport à l’utilisation de tous les sites disponibles. Les auteurs présentent également un modèle de coûts montrant que, puisque les frais d’utilisation des données et le temps d’entraînement augmentent avec le nombre d’hôpitaux participants, même une réduction modérée du nombre de partenaires peut conduire à des économies substantielles. Parallèlement, l’étape de sélection est légère : le modèle est entraîné une seule fois et chaque hôpital effectue seulement de simples calculs sur un vecteur moyenné.
Ce que cela signifie pour l’avenir de l’IA en santé
Pour les lecteurs extérieurs au domaine, le message clé est qu’il peut être possible pour les hôpitaux « d’apprendre ensemble » sans regrouper les dossiers patients bruts, et de le faire d’une manière qui respecte à la fois la confidentialité et les contraintes financières. En traduisant des dossiers divers en une forme textuelle partagée puis en utilisant des résumés préservant la vie privée des populations de patients pour choisir des partenaires compatibles, EHRFL propose une recette pragmatique pour construire des outils de prédiction spécifiques aux hôpitaux. Bien que l’étude se concentre sur des données de soins intensifs, les mêmes idées pourraient s’étendre aux consultations ambulatoires, aux services d’urgence et même à des domaines non médicaux où des organisations souhaitent collaborer sur de meilleurs modèles sans céder le contrôle de leurs données.
Citation: Kim, J., Kim, J., Hur, K. et al. Federated learning for heterogeneous electronic health record systems with cost effective participant selection. Sci Rep 16, 6876 (2026). https://doi.org/10.1038/s41598-026-38299-9
Mots-clés: apprentissage fédéré, dossiers de santé électroniques, confidentialité des patients, prédiction clinique, IA en santé