Clear Sky Science · fr
NeuroAction : une approche neuroévolutionnaire de l’apprentissage par renforcement pour véhicules autonomes
Pourquoi des styles de conduite plus intelligents comptent
La plupart d’entre nous imaginent les voitures autonomes comme des conducteurs calmes et parfaitement rationnels. Mais les systèmes actuels ont tendance à poursuivre un seul mélange d’objectifs — par exemple ne pas provoquer d’accident tout en vous y conduisant rapidement — et ce compromis est défini par les ingénieurs. NeuroAction, l’approche décrite dans cet article, vise à offrir aux voitures autonomes quelque chose de plus proche de la flexibilité humaine : la capacité de choisir parmi de nombreux styles de conduite sûrs, du comportement prudent « bébé à bord » à une conduite rapide sur autoroute, sans avoir à réentraîner la voiture à chaque fois.
D’un modèle unique à de nombreuses options sûres
Les systèmes actuels d’apprentissage profond par renforcement pour la conduite apprennent par essais et erreurs : ils observent la route, effectuent des actions comme diriger et accélérer, et reçoivent une récompense numérique unique qui combine différents objectifs tels que vitesse, sécurité et position sur la voie. Pour ajuster le système, les ingénieurs doivent concevoir cette récompense unique très soigneusement. Si l’on accorde trop d’importance à la vitesse, la voiture peut conduire de façon agressive ; si l’on surpondère la sécurité, elle peut avancer au pas. Changer les préférences ultérieurement signifie généralement revenir et réentraîner un grand réseau de neurones depuis le départ, ce qui est lent, gourmand en mémoire et sensible aux paramètres techniques.
Décomposer la conduite en objectifs simples
NeuroAction s’attaque à ce problème en divisant la tâche de conduite en plusieurs objectifs clairs au lieu d’un seul. Dans l’étude, le conducteur virtuel de la voiture est évalué indépendamment selon trois critères : la rapidité de déplacement dans une plage sûre, la fidélité à rester sur la voie la plus à droite (généralement la plus sûre) et la capacité à éviter les collisions. Plutôt que de combiner ces critères en un score unique, la méthode les traite comme des étalons séparés. En coulisses, chaque politique de conduite possible — le réseau neuronal qui transforme les données des capteurs en décisions de direction et de vitesse — est évaluée simultanément selon ces trois axes.
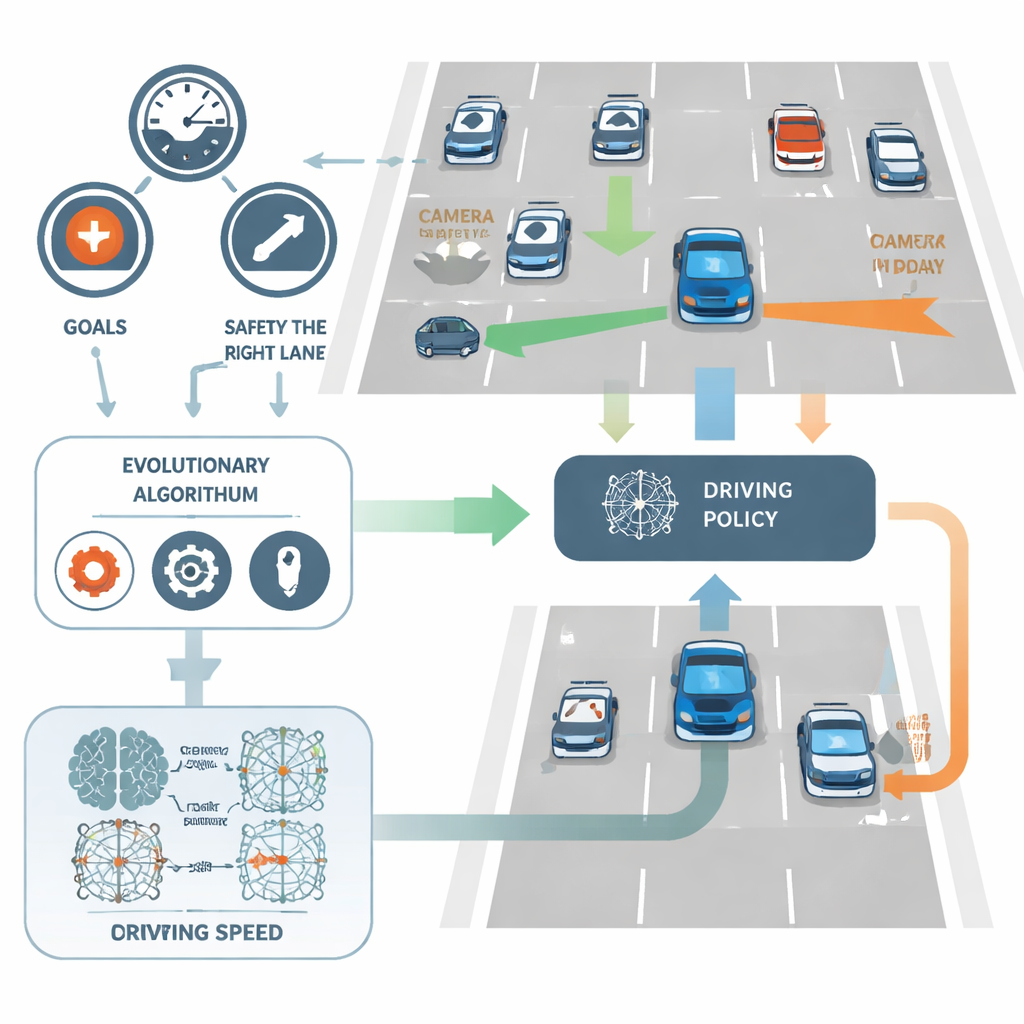
Laisser l’évolution rechercher de meilleurs conducteurs
Plutôt que d’ajuster les poids du réseau par la technique standard de rétropropagation, NeuroAction emprunte des idées à l’évolution biologique. Une population de politiques de conduite différentes est créée et testée dans un environnement simulé d’autoroute. Les politiques qui offrent de bons compromis entre vitesse, discipline de voie et sécurité sont conservées et recombinées, tandis que les moins performantes sont éliminées. Au fil des générations, ce processus évolutionnaire découvre tout un ensemble de solutions fortes — appelé front de Pareto — où aucune politique ne peut être améliorée sur un objectif sans sacrifier au moins un des autres.
Comparer apprentissage évolutionnaire et basé sur le gradient
Les chercheurs ont appliqué NeuroAction à un simulateur d’autoroute 2D largement utilisé, en employant un agent de conduite standard basé sur un réseau neuronal. Ils ont ensuite optimisé les paramètres de l’agent avec plusieurs algorithmes évolutionnaires multi‑objectifs établis, comparant la capacité de chacun à couvrir la gamme de compromis souhaitables. Une mesure clé de performance, l’« hypervolume » du front découvert, capture à la fois la qualité et la diversité des solutions. Un algorithme, NSGA‑II, a obtenu la meilleure couverture globale, tandis qu’un proche parent, NSGA‑III, a produit des résultats particulièrement cohérents au fil des répétitions.
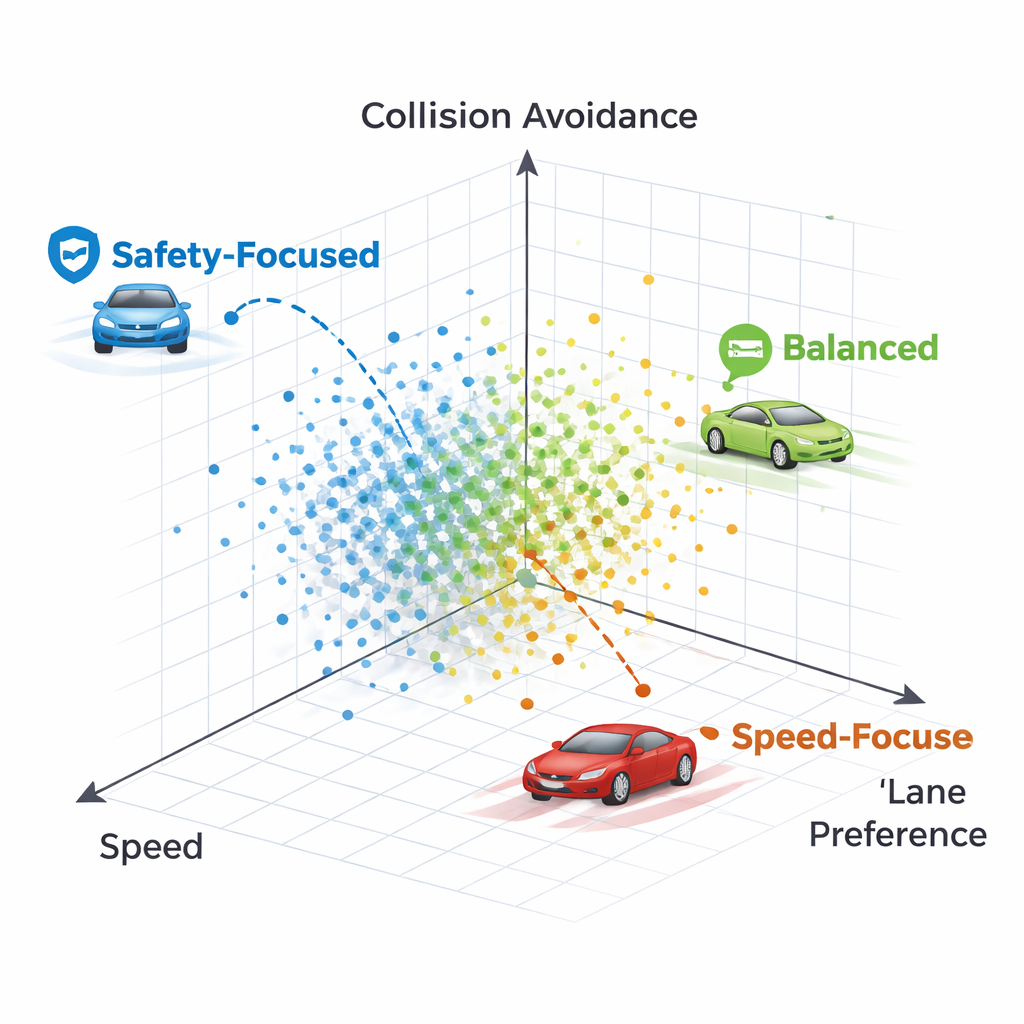
À quoi ressemblent les différents styles de conduite
En inspectant des politiques individuelles sur le front de Pareto, les auteurs montrent que chaque point correspond à un style de conduite reconnaissable. Une politique reste fermement sur la voie de droite à presque tout prix, sacrifiant la vitesse et finissant par entrer en collision avec un véhicule très lent devant — une stratégie trop prudente qui privilégie excessivement la préférence de voie. Une autre politique change de voie au départ puis revient sur une voie droite dégagée, maintenant une vitesse plus élevée tout en évitant les collisions. En général, les méthodes produisent un spectre de stratégies allant de conducteurs conservateurs, tenant leur voie, à des conducteurs plus affirmés mais toujours sûrs, le tout disponible simultanément sans réapprentissage.
Ce que cela signifie pour les voitures autonomes de demain
Pour un non‑spécialiste, le message central est que NeuroAction transforme l’entraînement des voitures autonomes en une recherche de nombreuses bonnes options plutôt qu’un comportement fixe unique. Cela permet de sélectionner une politique de conduite adaptée à la situation — lent et ultra‑sécuritaire en présence d’enfants, plus rapide lorsque vous êtes pressé — tout en respectant les contraintes de sécurité. Bien que les expériences actuelles se déroulent en simulation et utilisent des objectifs simplifiés, le cadre ouvre la voie à des véhicules autonomes plus adaptables et sensibles aux préférences qui peuvent offrir des styles de conduite personnalisés tout en restant fiables, sur une base mathématique solide.
Citation: Aboyeji, E., Ajani, O.S., Fenyom, I. et al. NeuroAction: a neuroevolutionary approach to reinforcement learning for autonomous vehicles. Sci Rep 16, 7403 (2026). https://doi.org/10.1038/s41598-026-38269-1
Mots-clés: conduite autonome, apprentissage par renforcement, algorithmes évolutionnaires, optimisation multi‑objectif, voitures autonomes