Clear Sky Science · fr
ResNet18-ThunderSVM : Intelligence hybride pour la reconnaissance de chiffres manuscrits en fusionnant des caractéristiques spatiales profondes et une classification haute performance
Pourquoi apprendre aux ordinateurs à lire l'écriture manuscrite est important
Chaque fois qu'une banque traite un chèque, qu'un enseignant corrige un test scanné ou que votre téléphone transforme des gribouillis en texte numérique, un système invisible doit correctement lire l'écriture humaine désordonnée. Parvenir à confier cette tâche aux machines rapidement et avec précision fait gagner du temps, réduit les coûts et diminue les erreurs humaines. Cet article présente une nouvelle manière de reconnaître les chiffres manuscrits qui vise à être à la fois très précise et suffisamment rapide pour une utilisation réelle, y compris sur des appareils à puissance de calcul limitée.
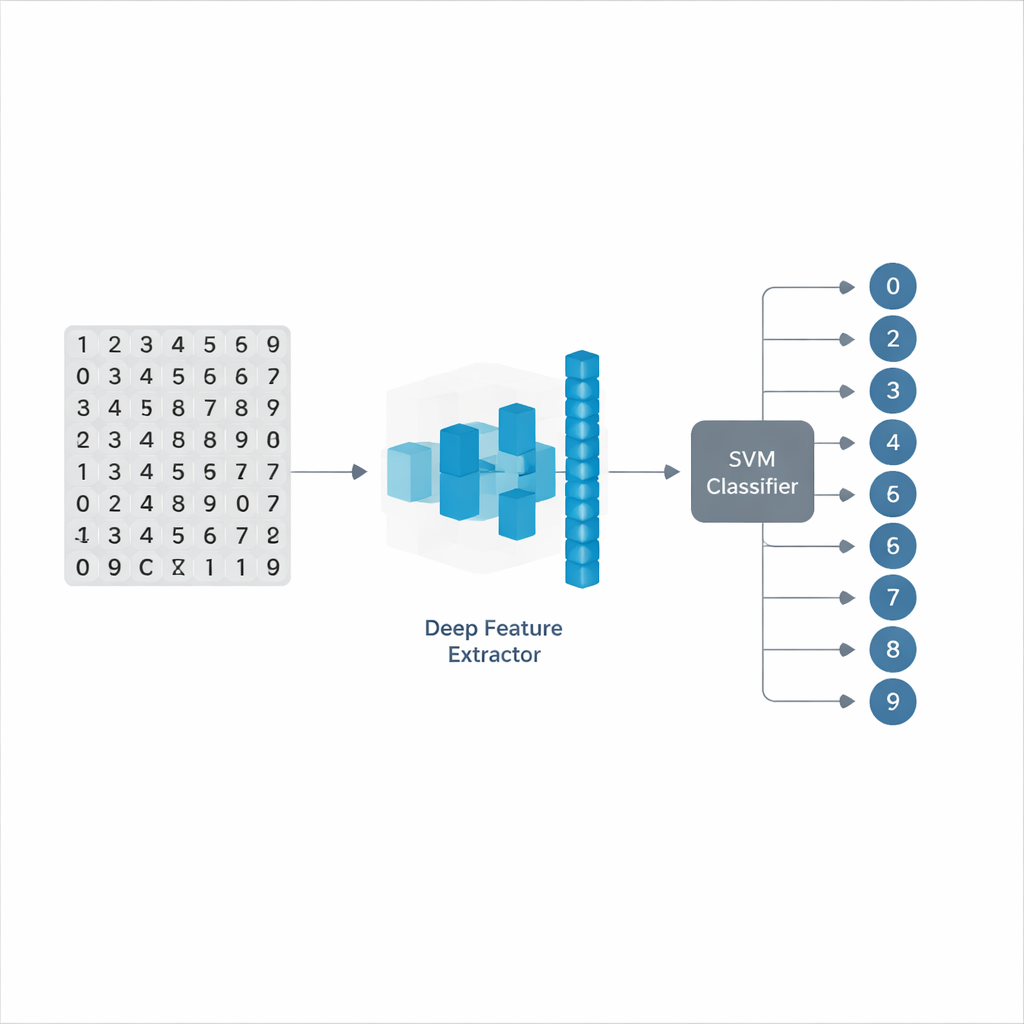
Fusionner deux forces en un système plus intelligent
Les chercheurs combinent deux types d'intelligence artificielle différents dans un modèle « hybride » qu'ils nomment ResNet18-ThunderSVM. La première partie, ResNet18, est un réseau neuronal profond très performant pour découvrir automatiquement des motifs dans les images, comme les traits, les courbes et les formes des chiffres manuscrits. La seconde partie, ThunderSVM, est une version rapide et accélérée par GPU d'une méthode classique d'apprentissage automatique, réputée pour ses décisions solides et stables une fois que de bonnes caractéristiques sont disponibles. En laissant ResNet18 s'occuper de la lourde tâche de découverte de caractéristiques puis en transmettant son information distillée à ThunderSVM pour la décision finale, le système cherche à tirer le meilleur des deux mondes : une compréhension riche des images et une classification efficace et fiable.
Des pixels bruts aux décisions confiantes
Les chiffres manuscrits de cette étude proviennent de quatre collections d'images populaires : MNIST, EMNIST, USPS et Fashion-MNIST. Ces jeux de données comprennent des chiffres simples, des lettres, des écritures de style postal et de petites images d'articles d'habillement, offrant une gamme de difficultés. Toutes les images sont redimensionnées et normalisées afin que leur luminosité reste dans une plage stable, ce qui aide le réseau neuronal à apprendre plus sereinement. ResNet18, ajusté par fine-tuning plutôt que laissé figé, transforme progressivement chaque image 2D en une empreinte compacte de 512 nombres qui capture les détails visuels les plus importants. Cette empreinte est ensuite légèrement mise à l'échelle pour conserver des valeurs bien commodes et alimentée dans ThunderSVM, qui apprend à séparer les différents chiffres en utilisant des règles mathématiques efficaces appelées noyaux.
Comment la nouvelle approche se compare
Les auteurs comparent leur modèle hybride à la fois aux méthodes traditionnelles et à de nombreux systèmes d'apprentissage profond sur le célèbre jeu de données de chiffres MNIST. Les approches plus anciennes comme les arbres de décision, les forêts aléatoires et les SVM basiques fonctionnent raisonnablement bien sur des problèmes réduits mais montrent leurs limites lorsque les chiffres varient en style ou lorsque l'échelle des données augmente. Les réseaux profonds purs tels que les modèles convolutionnels standards, VGG16 et MobileNet obtiennent de meilleurs résultats mais peuvent exiger plus de temps d'entraînement ou beaucoup plus de paramètres internes. ResNet18-ThunderSVM atteint environ 99,3 % de précision — proche du sommet — tout en utilisant un nombre modéré de paramètres et en maintenant une vitesse de traitement élevée. Il converge plus rapidement qu'un classifieur ResNet18 autonome et surpasse clairement un ThunderSVM reposant uniquement sur des caractéristiques conçues manuellement.
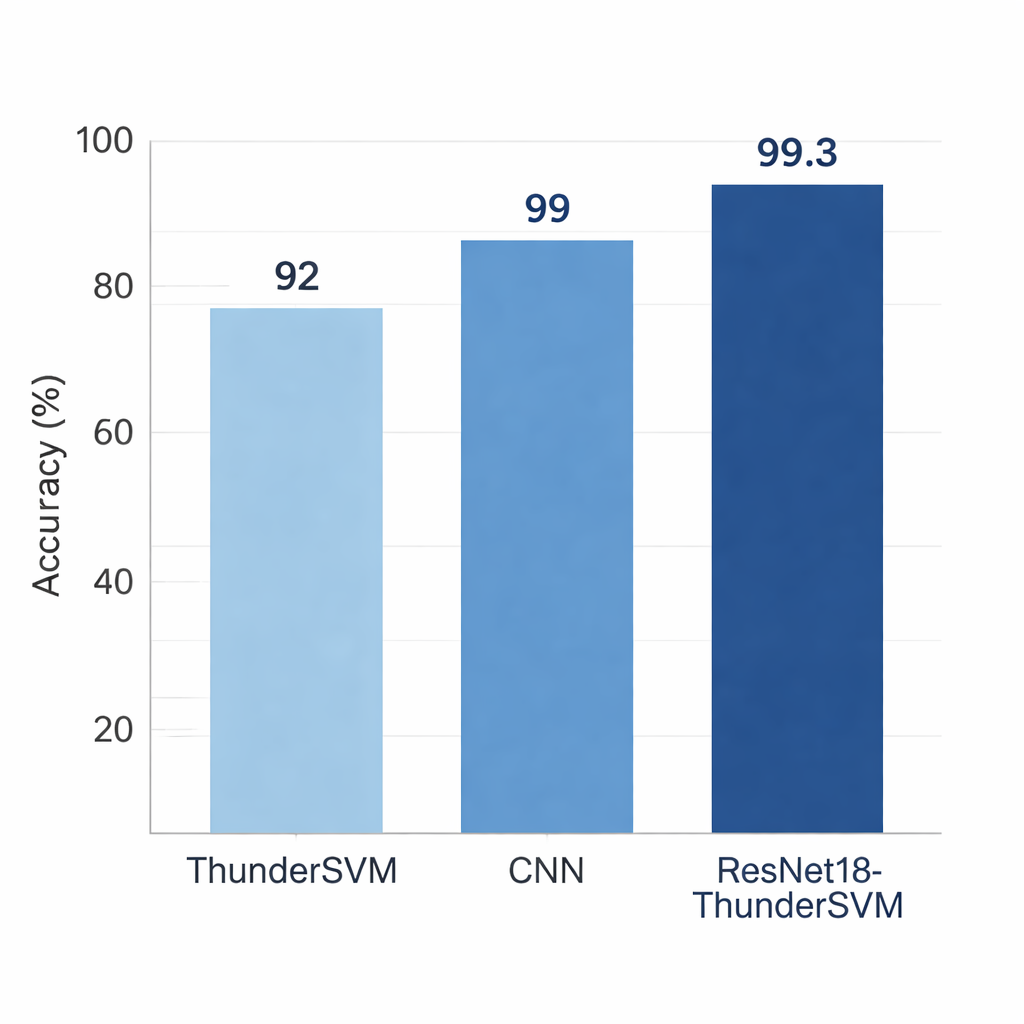
Résistance au bruit et aux nouvelles conditions
L'écriture manuscrite du monde réel est souvent bavée, inclinée ou rédigée dans des styles inhabituels. Pour simuler ces défis, l'équipe teste son modèle sur des jeux de données présentant des habitudes d'écriture différentes et ajoute du « bruit » artificiel à certaines images. Sur EMNIST lettres, USPS chiffres postaux et Fashion-MNIST articles vestimentaires, le modèle hybride dépasse systématiquement à la fois le ThunderSVM simple et un hybride CNN performant. Sa précision diminue moins lorsque du bruit est introduit, montrant une robustesse supérieure. Les chercheurs mesurent également le temps d'exécution de chaque composant et la mémoire utilisée. ResNet18-ThunderSVM est plus lent et plus lourd que les réseaux les plus légers mais beaucoup plus efficace que les modèles très profonds, trouvant un équilibre pratique entre rapidité, taille et précision.
Ce que cela signifie pour la technologie de tous les jours
Pour un non-spécialiste, le message clé est que l'association réfléchie de l'apprentissage profond moderne et de l'apprentissage automatique classique peut rendre les ordinateurs meilleurs et plus efficaces pour lire des images de type manuscrit. Plutôt que de concevoir manuellement des caractéristiques ou de s'appuyer sur d'énormes réseaux bout en bout, ce pipeline hybride permet à une interface visuelle intelligente d'alimenter un moteur de décision épuré mais puissant. Le résultat est un système qui lit les chiffres de manière extrêmement performante, s'adapte mieux aux données nouvelles ou bruitées et reste adapté aux appareils qui ne peuvent pas se permettre des modèles massifs. Cette approche pourrait être étendue au-delà des chiffres aux images médicales, aux scènes de circulation et à d'autres tâches visuelles où précision, vitesse et ressources informatiques limitées doivent être équilibrées.
Citation: Zhang, C., Tu, C., Wang, Z. et al. ResNet18-ThunderSVM: Hybrid intelligence for handwritten digit recognition by fusing deep spatial features and high-performance classification. Sci Rep 16, 7701 (2026). https://doi.org/10.1038/s41598-026-38258-4
Mots-clés: reconnaissance de chiffres manuscrits, apprentissage profond, machines à vecteurs de support, modèles hybrides, classification d'images