Clear Sky Science · fr
Décomposition de tenseurs sans rang via l'apprentissage métrique
Trouver des motifs dans une mer de données
La science moderne est submergée par des données complexes : piles de scanners médicaux, cartes d’activité cérébrale, images astronomiques et simulations de matériaux. Comprendre ces données revient souvent à les comprimer en formes plus simples sans perdre ce qui compte vraiment. Cet article présente une nouvelle manière d’y parvenir. Plutôt que d’essayer de reconstruire fidèlement chaque pixel, il se concentre sur la capture des véritables relations entre les échantillons — quel cerveau ressemble davantage à quel autre, quelle forme de galaxie ressemble à telle autre — de sorte que la carte résultante des données reflète le sens plutôt que le détail brut.
Du rekonstruktion d’images à la mesure de similarité
Les outils traditionnels de simplification des données multidimensionnelles, connus sous le nom de décompositions de tenseurs, fonctionnent un peu comme décomposer un accord en notes. Ils factorisent un « bloc » de données en un petit nombre de motifs de base et des poids. Pour ce faire, il faut indiquer à l’avance combien de motifs — le « rang » — on est autorisé à utiliser, et le succès se mesure à la qualité de reconstruction des données d’origine. C’est idéal pour la compression ou la réduction de bruit, mais pas forcément pour des tâches comme « ces deux visages sont-ils la même personne ? » ou « ce scan cérébral appartient-il à une personne autiste ou typique ? », où un classement correct importe plus qu’une reconstruction parfaite.
Parallèlement, l’apprentissage profond a popularisé une autre idée : au lieu de décomposer un tenseur algébriquement, apprendre un code numérique compact, ou embedding, via un réseau de neurones. Les autoencodeurs classiques restent focalisés sur la reconstruction. Ce travail inverse l’objectif. Il propose un cadre « sans rang » qui ne fixe pas un rang à l’avance et ne cherche pas une récupération pixel par pixel. Il apprend plutôt une mesure de distance de sorte que des points qui doivent être proches (même personne, même diagnostic, même classe physique) se retrouvent voisins dans l’espace d’embedding, et que les points différents soient repoussés les uns des autres.
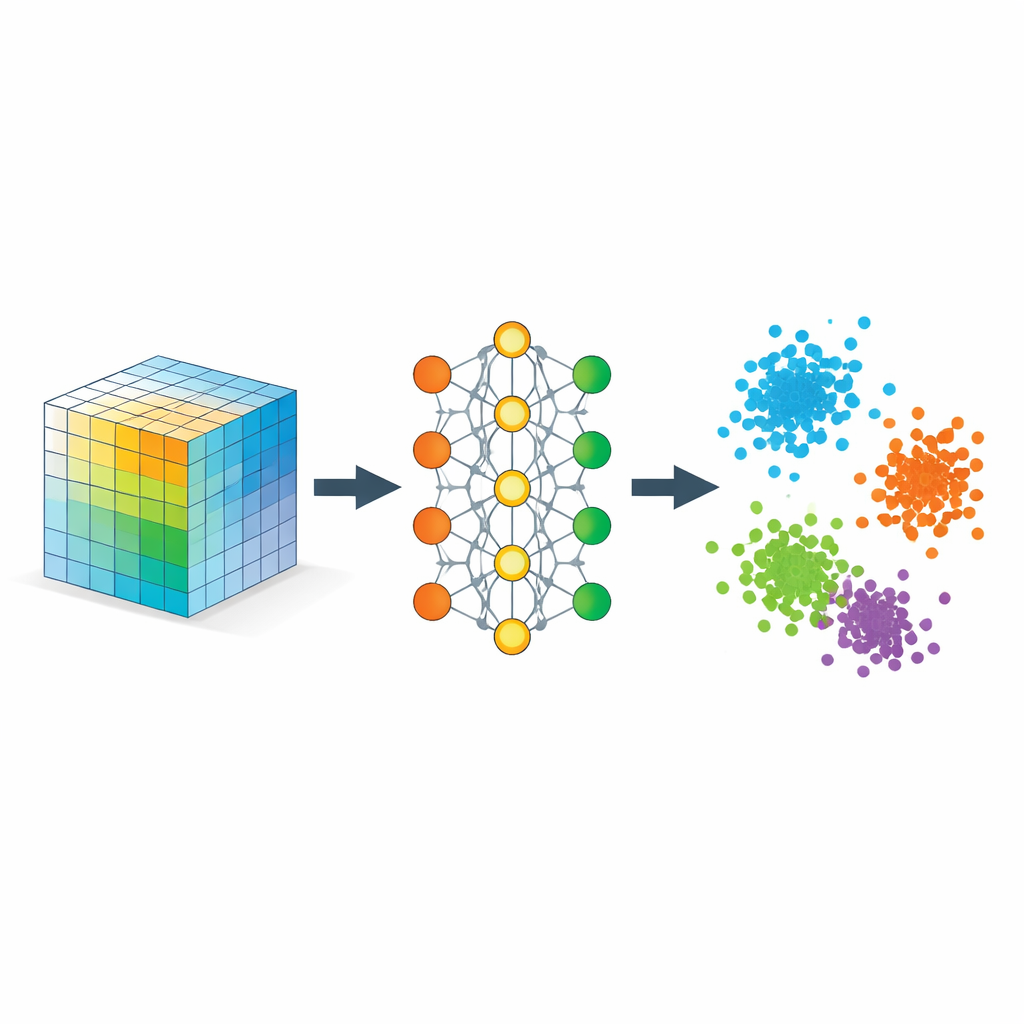
Apprendre au réseau ce que « proche » doit signifier
L’ingrédient clé est une stratégie appelée apprentissage métrique, mise en œuvre ici via des triplets d’exemples : un échantillon ancre, un échantillon positif du même type et un échantillon négatif d’un type différent. Pendant l’entraînement, le réseau est récompensé lorsque l’ancre est plus proche du positif que du négatif par une marge de sécurité. Sur de nombreux triplets de ce type, cette règle simple façonne l’espace d’embedding pour que les distances reflètent la similarité sémantique plutôt que la similarité brute des pixels. Des régularisateurs additionnels encouragent le réseau à répartir l’information de façon uniforme entre les dimensions, à éviter l’effondrement sur une ligne et à préserver approximativement les voisinages locaux, de sorte que des points proches dans les données originales restent proches une fois embarqués.
Mathématiquement, les auteurs montrent que cet embedding se comporte comme une décomposition de tenseur flexible, mais sans un rang prédéfini. Les coordonnées apprises peuvent être interprétées comme des facteurs dans une décomposition classique d’un tenseur de similarité dont les entrées mesurent à quel point différentes parties des données s’alignent. Parce que le modèle pénalise les directions redondantes, il tend à utiliser efficacement toutes les dimensions de l’embedding, laissant aux données elles-mêmes le soin de déterminer combien de composantes significatives sont nécessaires. En parallèle, ils fournissent des garanties théoriques que les procédures d’entraînement standard convergent et que la géométrie résultante sépare fidèlement les classes sans déformer de manière excessive les relations locales significatives.
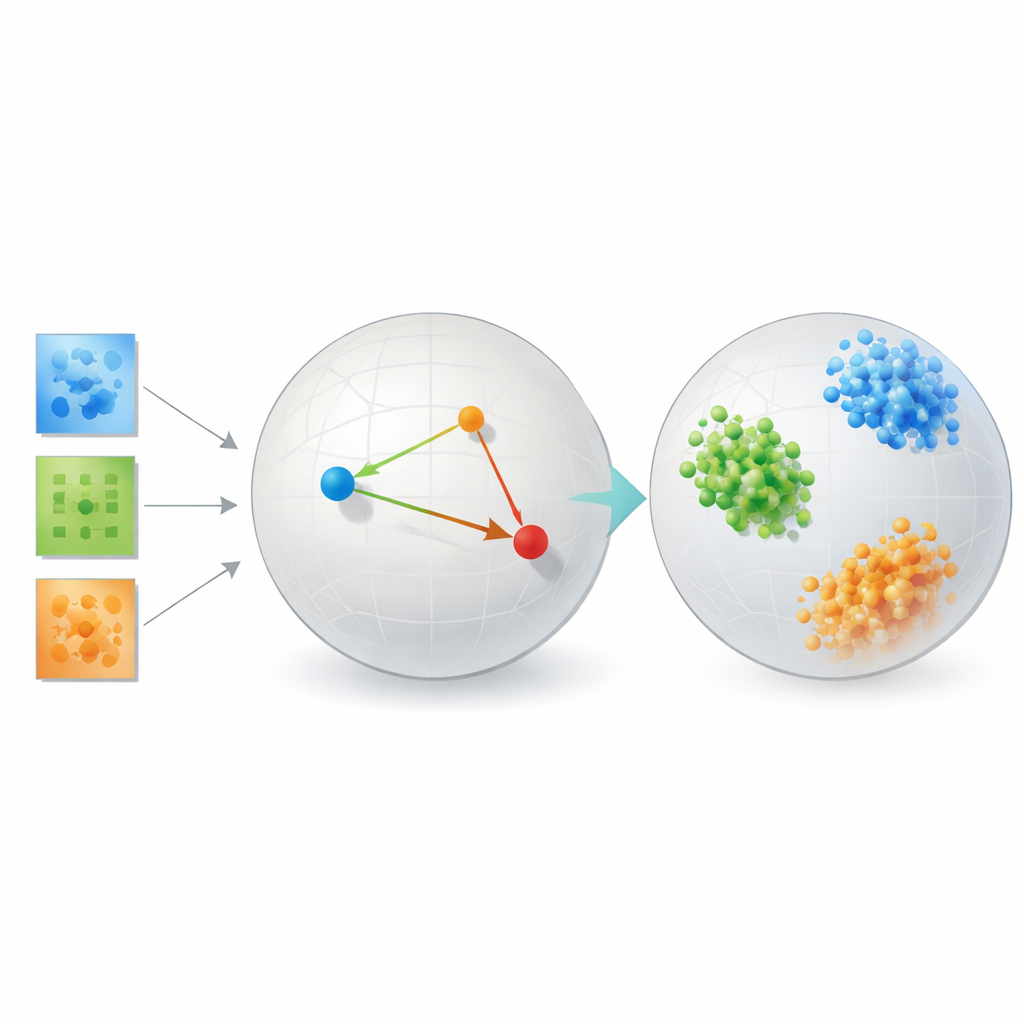
Mettre la méthode à l’épreuve
Pour montrer que leur approche n’est pas que théorie élégante, l’auteur la teste sur plusieurs problèmes très différents. Dans les benchmarks de reconnaissance faciale, les embeddings appris regroupent les images d’une même personne en amas serrés et bien séparés, surpassant de façon significative des méthodes classiques comme les composantes principales, des outils de visualisation populaires tels que t-SNE et UMAP, et des décompositions de tenseurs traditionnelles dépendant de rangs fixes. Sur des données de connectivité cérébrale de personnes avec et sans autisme, la méthode découvre un espace où les deux groupes sont séparés plus nettement que par des outils de tenseur axés sur la reconstruction ou des réseaux autoencodeurs, suggérant qu’elle cible des motifs cliniquement pertinents dans l’interaction entre régions cérébrales.
L’étude inclut également des simulations contrôlées de formes de galaxies et de structures cristallines, où les catégories « vraies » sont connues exactement. Là, le cadre d’apprentissage métrique regroupe presque parfaitement les galaxies et cristaux synthétiques selon leurs types physiques sous-jacents. Dans tous ces contextes, la méthode échange systématiquement un certain degré de fidélité à la disposition pixel par pixel pour une représentation où similarité et différence correspondent au sens scientifique. Fait important, elle le fait sans exiger les vastes jeux de données et ressources de calcul souvent nécessaires pour entraîner des modèles profonds de type transformer, qui ont eu du mal sur ces jeux de données scientifiques relativement petits.
Pourquoi cela compte pour les données scientifiques à venir
Pour les scientifiques qui cherchent des motifs dans des données limitées et de haute dimension, ce travail offre un changement de perspective séduisant. Plutôt que de deviner un rang et d’optimiser la reconstruction, les chercheurs peuvent demander directement un embedding qui reflète les relations qui les intéressent : même diagnostic, même phase de matériau, même classe astrophysique. Le cadre no-rank d’apprentissage métrique proposé montre que de tels embeddings peuvent être à la fois interprétables et puissants, surtout lorsque les données sont rares. Comme le note l’auteur, des défis subsistent — notamment la gestion du déséquilibre des classes et l’extension à de nombreuses catégories — mais le message est clair : dans de nombreux problèmes scientifiques, apprendre une bonne notion de similarité peut valoir davantage que reconstruire chaque détail du signal d’origine.
Citation: Bagherian, M. No-rank tensor decomposition via metric learning. Sci Rep 16, 8326 (2026). https://doi.org/10.1038/s41598-026-38221-3
Mots-clés: apprentissage métrique, décomposition de tenseurs, apprentissage de représentation, réduction de dimensionnalité, analyse de données scientifiques