Clear Sky Science · fr
Méthode de classification automatique des matières premières des produits e‑commerce par l’introduction de concepts auto‑supervisés et la construction d’une ontologie de domaine
Pourquoi trier les produits en ligne par ingrédients importe
Lorsque vous achetez de la farine ou des snacks en ligne, vous recherchez généralement ce que le produit permet de faire — préparation pour gâteau, farine à pain, ingrédients de pâtisserie. Mais les entreprises, les régulateurs et même les consommateurs soucieux de leur santé se préoccupent souvent davantage de la composition des produits. Les sites e‑commerce actuels organisent rarement les articles par matières premières, et corriger cela manuellement impliquerait de vérifier des millions de pages produit une par une. Cette étude propose une méthode automatique pour regrouper les produits en ligne selon leurs ingrédients sous‑jacents, en combinant connaissances d’experts et apprentissage automatique.
Le problème des rayons produits mélangés
Les grandes plateformes e‑commerce listent des millions d’articles et les organisent en général par fonction : « préparation pour pâtisserie » ou « snack », plutôt que par blé, sarrasin ou maïs. Par conséquent, deux farines issues du même grain peuvent se retrouver dans des catégories différentes, tandis que des produits aux ingrédients différents peuvent être réunis parce qu’ils servent à des usages similaires. C’est pratique pour les acheteurs mais problématique pour les commerçants et les analystes qui veulent suivre les ventes ou la qualité par matière première. Les méthodes automatiques existantes reproduisent souvent les étiquettes de la plateforme et exigent de nombreux exemples annotés manuellement, ce qui coûte cher et ne résout pas la vision centrée sur les ingrédients dont ont besoin les entreprises.
Construire une carte intelligente des ingrédients
Les chercheurs ont commencé par demander à des experts du domaine de concevoir une « carte » structurée du monde des farines, appelée ontologie de domaine. Concrètement, il s’agit d’un inventaire soigné des types de farines — par exemple blé, blé complet, maïs, sarrasin, riz et riz gluant — et des traits clés qui les distinguent, incluant le grain d’origine, la teneur en gluten, la catégorie de qualité, la marque et le lieu d’origine. À partir de pages produit réelles sur plusieurs plateformes chinoises, l’équipe a ensuite récolté des milliers de expressions concrètes correspondant à ces traits, comme des noms de marques ou des formulations courantes pour l’origine. Ils ont utilisé des règles de correspondance de motifs et une mesure de distance entre chaînes pour capturer les fautes d’orthographe proches et les synonymes, par exemple des appellations légèrement différentes pour un même type de farine, et les ont intégrés dans une liste de mots spécifique au domaine.
Laisser les données s’auto‑étiqueter
Puis les auteurs ont adapté l’idée d’apprentissage auto‑supervisé : au lieu de demander aux humains d’annoter chaque échantillon, ils laissent les données générer nombre de leurs propres étiquettes. En s’appuyant sur leur ontologie et la liste de mots, ils ont rédigé des règles indiquant comment les attributs d’ingrédient doivent correspondre à une catégorie. Si les détails d’un produit mentionnent clairement le maïs comme grain principal et que les autres caractéristiques correspondent au profil de la farine de maïs, le système considère cette fiche comme un exemple « standard » de farine de maïs et accepte automatiquement son étiquetage de catégorie. Les fiches dont les attributs sont en contradiction avec les règles d’experts, ou trop vagues, sont traitées comme « non‑standard » et mises de côté comme cas non étiquetés. De cette façon, le modèle récolte des milliers d’exemples d’apprentissage propres directement à partir de catalogues désordonnés sans inspection humaine.
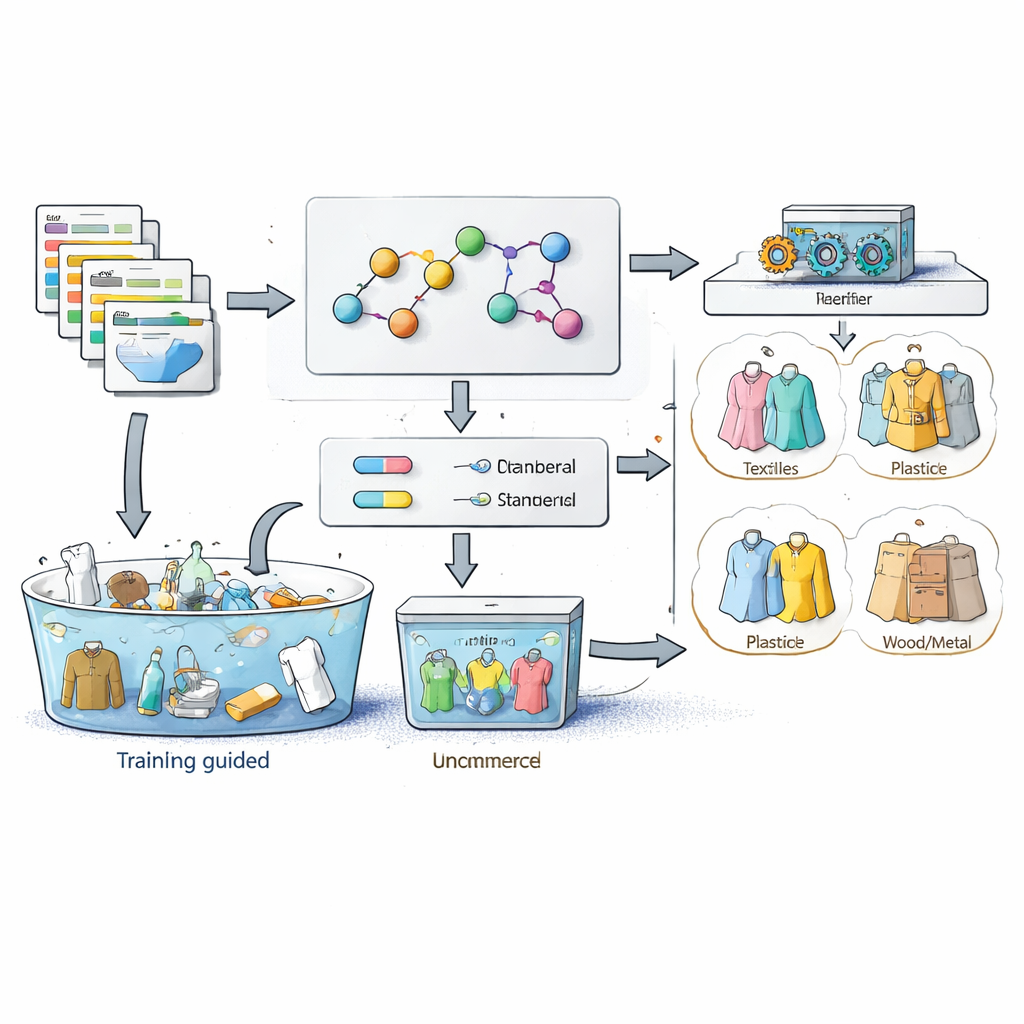
Apprendre au classificateur à reconnaître les matières premières
Avec les exemples standards en main, le système transforme le texte de chaque produit en caractéristiques exploitables par machine. Il utilise un modèle de langage puissant, développé initialement pour le chinois, pour extraire des entités importantes telles que marques, noms d’ingrédients et lieux d’origine, et les ajoute à la liste de mots du domaine. Un tokenizer découpe ensuite les titres et descriptions des produits en segments significatifs, élimine les mots de remplissage fréquents et construit un profil numérique mesurant la spécificité de chaque terme à travers l’ensemble de données. Des classificateurs d’apprentissage automatique classiques sont entraînés sur ces profils et sur les catégories d’ingrédients attribuées automatiquement. Les auteurs ont testé plusieurs algorithmes sur plus de 18 000 fiches de farine et ont constaté qu’un modèle de régression logistique, méthode relativement simple, offrait le meilleur compromis entre rapidité et précision.
Performance du système — et pourquoi il surpasse l’IA générale
Sur des données de farine collectées auprès de grandes plateformes chinoises, le classificateur centré sur les ingrédients a atteint environ 91 % de précision globale. Il s’est montré particulièrement robuste pour reconnaître les farines courantes, comme la farine de blé standard et la farine de riz gluant, et a conservé des performances raisonnables sur des catégories plus délicates comme le sarrasin et le maïs, où les produits sont souvent des mélanges de grains. L’ajout de la liste de mots spécifique au domaine a clairement amélioré les résultats comparé à l’utilisation seule de caractéristiques textuelles génériques. L’équipe a aussi comparé leur méthode à un grand modèle de langage généraliste sollicité pour accomplir la même tâche sans entraînement préalable sur le jeu de données. Ce modèle zero‑shot est resté à la traîne, surtout pour les types de farine rares, ce qui souligne l’avantage de combiner connaissance d’experts et apprentissage ciblé plutôt que de s’appuyer uniquement sur une compréhension linguistique large mais peu approfondie.
Ce que cela implique pour le commerce en ligne et au‑delà
En termes simples, l’étude montre que les plateformes e‑commerce peuvent regrouper automatiquement les articles selon leur composition, et pas seulement selon leur usage. En encodant la connaissance d’experts sur les ingrédients dans une carte réutilisable et en laissant les pages produit s’auto‑étiqueter, l’approche réduit fortement le besoin d’annotation manuelle tout en maintenant une haute précision. Pour les commerçants et les analystes, cela ouvre la voie à des statistiques de vente plus propres, un meilleur contrôle qualité et des réponses plus précises à des enjeux comme le suivi des allergènes ou les tendances nutritionnelles. Bien que démontrée sur la farine, la recette — ontologies construites par des experts, règles d’auto‑étiquetage et classificateurs légers — pourrait être adaptée à de nombreuses autres catégories de produits partout où les matières premières ont une importance réelle.
Citation: Lei, B., Wang, J. & Shen, C. Automatic classification method of e-commerce commodity raw materials through the introduction of self-supervised concepts and the construction of domain ontology. Sci Rep 16, 8058 (2026). https://doi.org/10.1038/s41598-026-38214-2
Mots-clés: classification e‑commerce, ingrédients des produits, apprentissage auto‑supervisé, ontologie de domaine, fouille de texte