Clear Sky Science · fr
Un couplage de modélisation de la dégradation guidé par VLM pour la fusion d'images infrarouges et visibles sensible à la dégradation
Une vision nocturne plus nette pour un monde bruyant
Les caméras modernes peuvent voir dans l’obscurité, détecter la chaleur et surveiller la route pour nous — mais leurs images sont souvent loin d’être parfaites. Les réverbères provoquent des halos, les ombres effacent des détails et les capteurs ajoutent du bruit ponctuel. Cette étude présente une nouvelle méthode pour fusionner la vidéo couleur ordinaire avec des images infrarouges thermiques afin que le rendu final soit plus net et plus fiable, même lorsque les deux sources sont fortement dégradées. Cette approche pourrait rendre les voitures autonomes, les systèmes de surveillance et autres caméras intelligentes plus robustes dans les conditions où elles sont le plus nécessaires : la nuit, par mauvais temps et dans des scènes réelles encombrées.
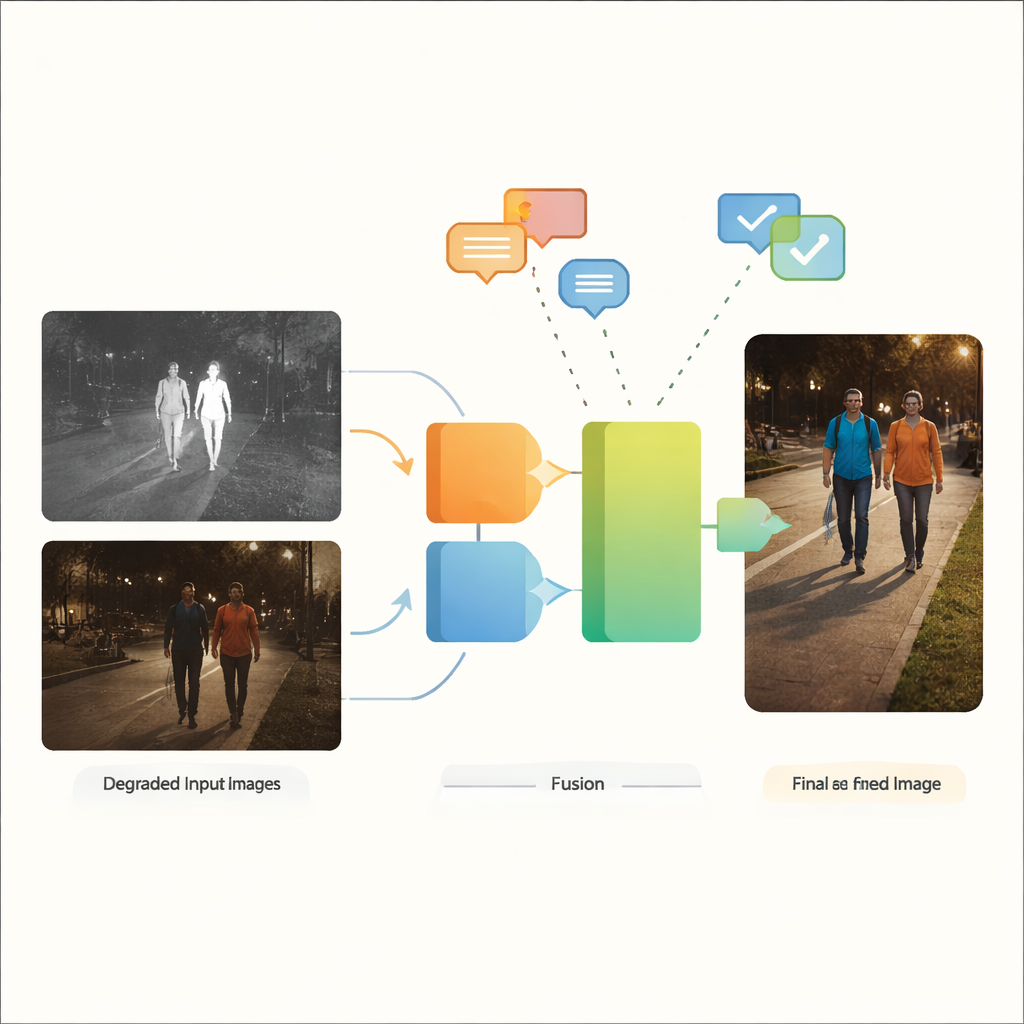
Pourquoi deux yeux valent mieux qu’un
Les caméras en lumière visible captent les couleurs et les textures riches auxquelles les humains sont habitués, mais elles peinent en faible luminosité, face aux éblouissements et aux ombres profondes. Les caméras infrarouges, en revanche, détectent la chaleur et repèrent facilement des objets chauds comme des personnes ou des véhicules dans l’obscurité, bien que leurs images paraissent souvent plates et manquent de détails fins. La fusion d’images infrarouge et visible vise à combiner le meilleur des deux : les contours nets des cibles chaudes fournis par l’infrarouge et les détails contextuels et la couleur de la lumière visible. Traditionnellement, toutefois, la plupart des méthodes de fusion supposent que les images d’entrée sont déjà propres et de haute qualité — une hypothèse mal adaptée aux rues, villes et sites industriels réels où flou, bruit, faible éclairage et surexposition sont la norme plutôt que l’exception.
Quand le prétraitement n’est pas suffisant
Les systèmes existants traitent généralement les images dégradées en deux étapes déconnectées. D’abord, des outils d’amélioration séparés éclaircissent les scènes sombres, réduisent le bruit ou corrigent le contraste. Ce n’est qu’ensuite qu’un réseau de fusion mélange les images améliorées. Cette approche en deux étapes présente plusieurs défauts. Elle oblige les ingénieurs à sélectionner et ajuster différents outils d’amélioration pour chaque type de défaut et chaque capteur, rendant les flux de travail fragiles et complexes. Plus important encore, toute information perdue ou déformée lors du nettoyage indépendant ne peut pas être récupérée ultérieurement par l’étape de fusion. Des travaux récents ont introduit des réseaux spécialisés pour un type précis de dégradation ou ont utilisé des modèles guidés par le langage pour gérer une seule modalité altérée à la fois. Pourtant, quand les images infrarouges et visibles sont toutes deux dégradées — et souvent de manières différentes — ces stratégies restent fortement dépendantes du prétraitement manuel et peinent face à des conditions mixtes et réelles.
Un réseau de fusion qui comprend la dégradation
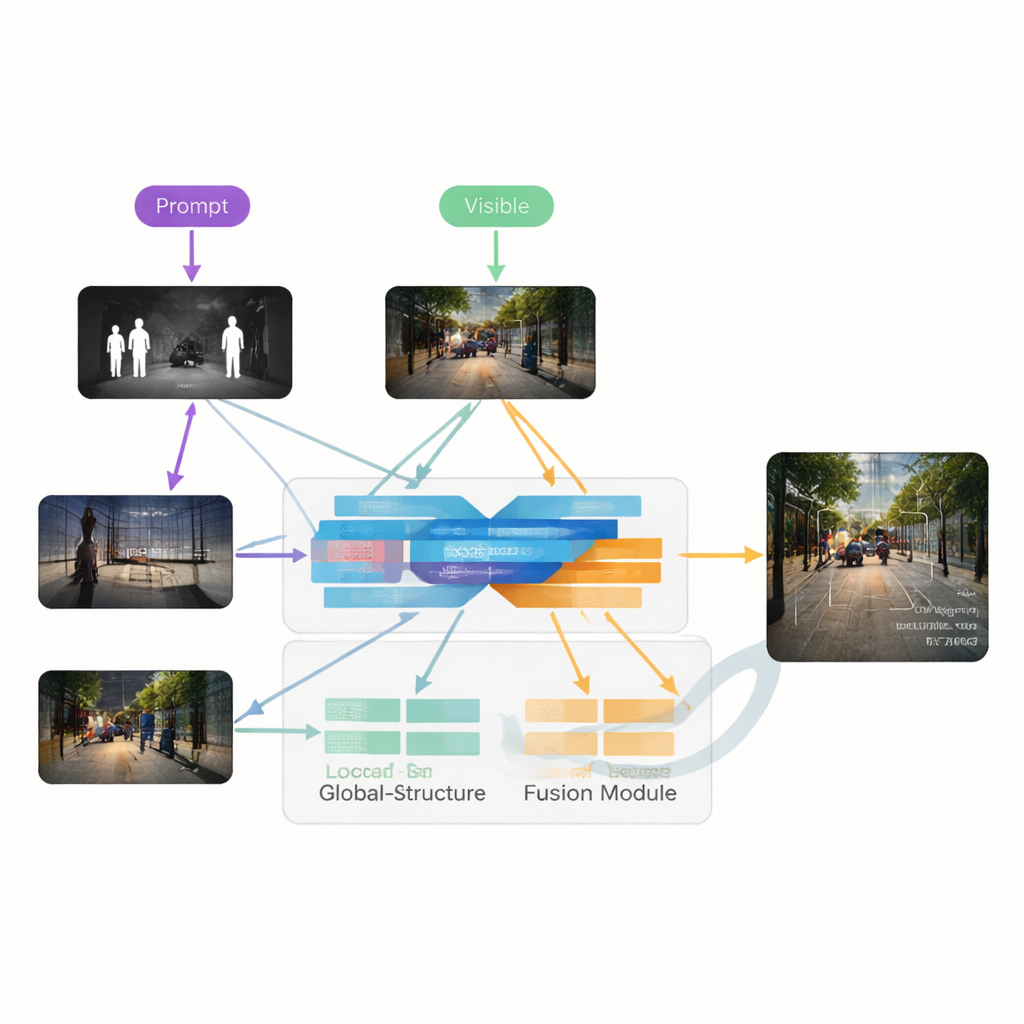
Les auteurs proposent VGDCFusion, un nouveau cadre d’apprentissage profond qui intègre la gestion de la dégradation directement dans le processus de fusion. L’idée clé est d’informer le réseau, en mots, des problèmes qu’il doit anticiper, puis d’utiliser ces connaissances à chaque étape d’extraction et de fusion des caractéristiques. De courts prompts textuels décrivent la tâche (fusion infrarouge–visible) et les problèmes spécifiques présents, tels que faible luminosité, surexposition, faible contraste ou bruit. Un puissant modèle vision–langage — proche dans l’esprit de systèmes comme CLIP — transforme ces prompts en des descripteurs numériques compacts. Ces descripteurs guident deux blocs principaux : le Specific-Prompt Degradation-Coupled Extractor (SPDCE), qui travaille séparément sur chaque modalité, et le Joint-Prompt Degradation-Coupled Fusion (JPDCF), qui fusionne l’information entre modalités tout en tenant compte des types de dégradation résiduels.
Comment fonctionne le processus de fusion guidée
Dans chaque module SPDCE, l’orientation fournie par les prompts oriente le réseau vers les caractéristiques importantes et éloigne les artefacts. Des couches convolutionnelles multi-échelles examinent les voisinages locaux pour préserver les arêtes et textures, tandis que des couches Transformer capturent la structure et le contexte à plus grande échelle. Ensemble, elles apprennent à mettre en évidence, par exemple, des signatures thermiques importantes dans une trame infrarouge bruyante ou des marquages routiers faibles dans une image visible sous-exposée, tout en supprimant le bruit du capteur et les défauts d’éclairage. En parallèle, les modules JPDCF prennent les caractéristiques « nettoyées » provenant des deux branches et les combinent, là encore sous la conduite des prompts. Ils utilisent une attention spatiale et par canal pour mettre en avant les régions informatives, filtrer les dégradations restantes et rassembler des indices complémentaires — par exemple en alignant un contour infrarouge lumineux d’un piéton avec la couleur et la structure d’arrière-plan de la caméra visible — avant de reconstruire une image fusionnée à trois canaux.
Mettre la méthode à l’épreuve
Pour démontrer son intérêt, l’équipe a évalué VGDCFusion sur plusieurs jeux de données publics incluant des images visibles en faible luminosité et surexposées ainsi que des images infrarouges bruyantes ou à faible contraste. Ils ont comparé leur méthode à un ensemble de techniques de fusion à la pointe, couvrant autoencodeurs, réseaux convolutionnels, réseaux antagonistes génératifs et Transformers. En utilisant des mesures standards de qualité d’image, VGDCFusion a systématiquement produit des images fusionnées avec des contours plus nets, un meilleur contraste et des couleurs plus naturelles, même lorsque les méthodes concurrentes bénéficiaient d’un prétraitement soigneusement ajusté. La nouvelle approche a amélioré les métriques clés d’environ 15 % en moyenne dans les scénarios fortement dégradés. Lorsque les images fusionnées ont été fournies à un système de détection d’objets populaire, cela a également entraîné une précision de détection supérieure à l’utilisation des images infrarouges ou visibles seules, ou à l’emploi d’autres réseaux de fusion.
Une vision plus claire pour des systèmes plus sûrs
En termes simples, ce travail montre que dire à un réseau de fusion d’images quels types de problèmes visuels attendre — et lui permettre de corriger et fusionner en une seule étape étroitement couplée — peut produire des images plus propres et plus informatives que de traiter l’amélioration et la fusion séparément. En couplant la modélisation de la dégradation au processus de fusion et en utilisant des indices guidés par le langage à chaque couche, VGDCFusion peut s’adapter à des formes variées et mixtes de dégradation d’image sans réglages humains constants. Ce type de fusion intelligente et consciente de la dégradation pourrait aider les futurs systèmes de vision, des voitures autonomes aux caméras de sécurité, à voir de façon plus fiable dans les conditions désordonnées et imparfaites du monde réel.
Citation: Zhao, J., Zhang, T. & Cui, G. A VLM guided network coupling degradation modeling for degradation aware infrared and visible image fusion. Sci Rep 16, 8249 (2026). https://doi.org/10.1038/s41598-026-38181-8
Mots-clés: fusion infrarouge et visible, imagerie en faible lumière, modèles vision-langage, dégradation d'image, perception pour conduite autonome