Clear Sky Science · fr
Un cadre d’apprentissage ensembliste empilé hybride pour la détection d’émotions multilabel dans les textes
Pourquoi il est important de lire les émotions dans les textes
Chaque jour, des personnes déversent leurs sentiments dans des publications sur les réseaux sociaux, des avis et des messages. Cachés dans ce flot de mots se trouvent des signaux précoces concernant des difficultés de santé mentale, la montée des discours de haine et les réactions publiques face aux crises et aux catastrophes. Mais les ordinateurs voient généralement seulement un sentiment « positif » ou « négatif », manquant la combinaison d’émotions que les gens expriment souvent simultanément. Cet article explore une nouvelle manière d’apprendre aux machines à reconnaître plusieurs émotions dans un même texte, et à le faire non seulement en anglais mais aussi dans des langues qui bénéficient rarement des avancées en intelligence artificielle.
Aller au-delà du simple positif ou négatif
Les outils traditionnels d’analyse de sentiment sont comme des thermomètres grossiers : ils peuvent dire si l’humeur est bonne ou mauvaise, mais pas si quelqu’un ressent de la colère, de la peur, de l’espoir ou du soulagement en même temps. Les auteurs soutiennent que comprendre cette palette émotionnelle plus riche est crucial pour des applications telles que la gestion des catastrophes, le soutien thérapeutique et le service client. Un message mêlant peur et urgence, par exemple, peut exiger une attention immédiate, tandis qu’un message combinant tristesse et optimisme peut nécessiter un autre type de soutien. Capturer plusieurs émotions en parallèle — connu sous le nom de détection d’émotions « multilabel » — est donc une étape clé vers des systèmes plus sensibles et attentifs à l’humain.
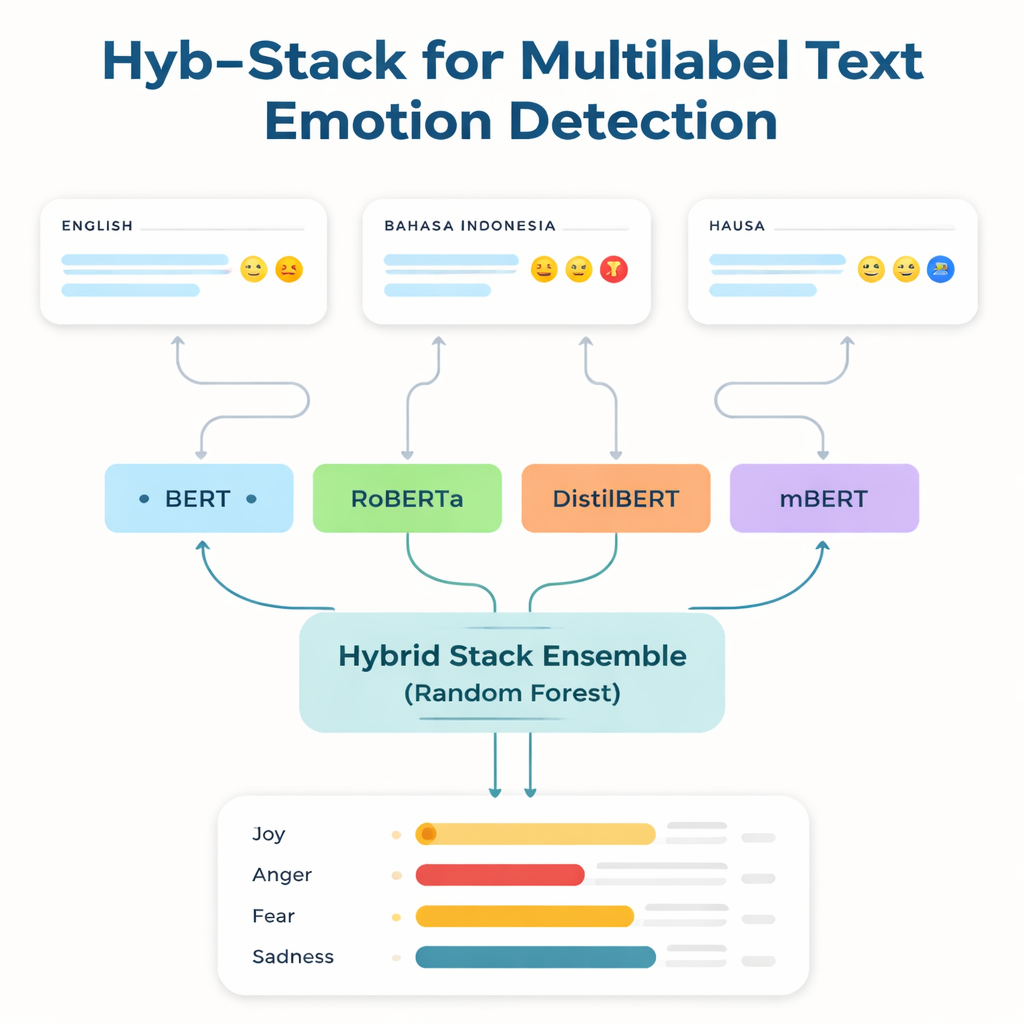
Donner une voix aux langues négligées
La plupart des technologies linguistiques puissantes sont entraînées et optimisées sur l’anglais et quelques autres langues largement utilisées. Les locuteurs de langues à faibles ressources — celles disposant de peu de données annotées et de peu d’outils numériques — sont souvent laissés pour compte. Pour combler cette lacune, les chercheurs se concentrent sur trois jeux de données : une référence anglaise bien connue pour les émotions ; une collection en Bahasa Indonesia centrée sur les propos abusifs et haineux ; et un tout nouveau corpus Twitter en haoussa qu’ils ont créé, nommé HaEmoC_V1. Le jeu de données haoussa comprend plus de douze mille tweets soigneusement nettoyés et annotés, chacun étiqueté avec une ou plusieurs des onze émotions telles que colère, joie, confiance, pessimisme et anticipation. Des examinateurs experts ont vérifié les étiquettes, et les scores d’accord montrent que les annotations sont à la fois cohérentes et fiables.
Combiner plusieurs lecteurs intelligents en un seul
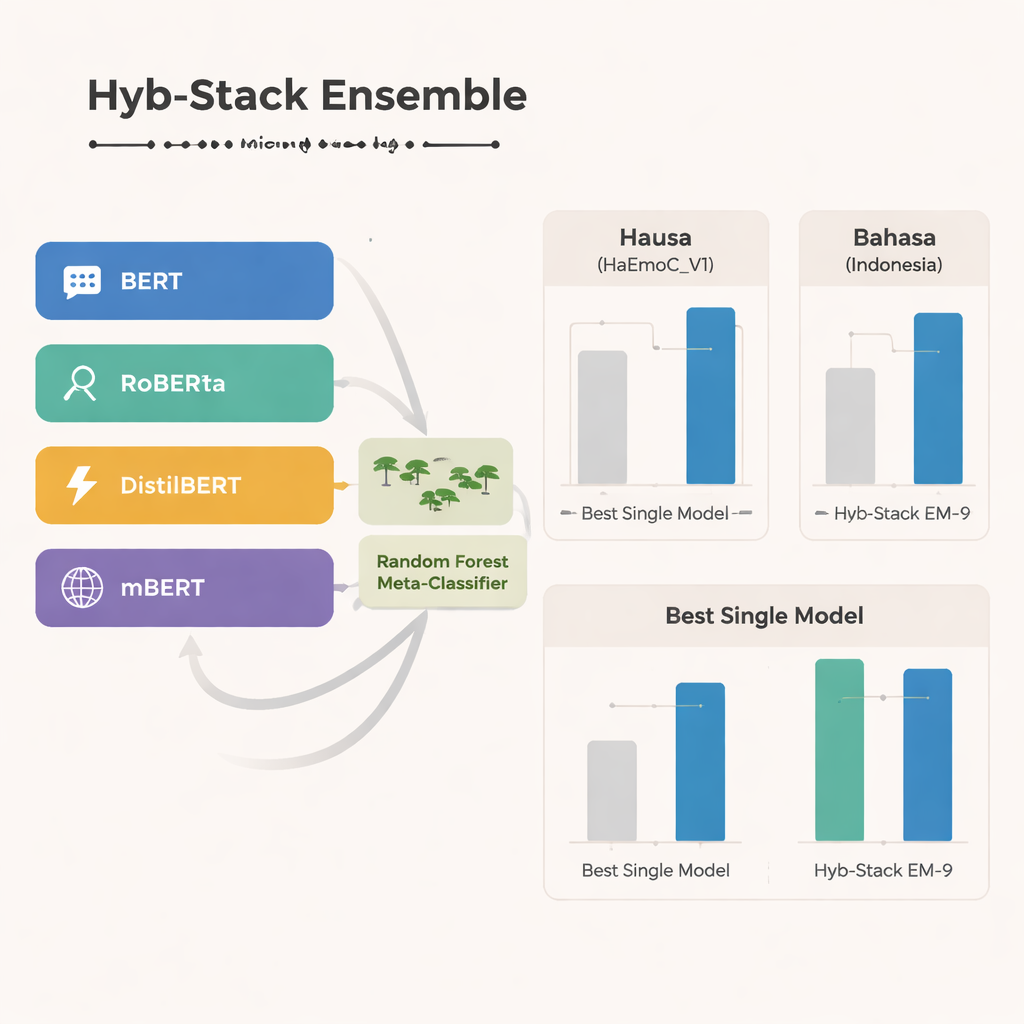
Au cœur de l’étude se trouve Hyb-Stack, un empilement hybride ensembliste — une sorte de « comité d’experts » pour le langage. Quatre modèles avancés basés sur des transformers (BERT, RoBERTa, DistilBERT et le multilingue mBERT) sont chacun fine-tunés pour détecter des signaux émotionnels dans le texte. Plutôt que de faire confiance à un seul modèle, Hyb-Stack permet à tous de faire des prédictions, puis injecte leurs scores internes dans un décideur de deuxième niveau : un classifieur Random Forest. Ce méta-classifieur apprend à pondérer les forces différentes de chaque modèle, capturant des schémas complexes de cooccurrence des émotions. L’équipe teste également des méthodes d’ensemble plus simples qui se contentent de moyenner les prédictions, avec ou sans pondération par la performance antérieure, pour vérifier si l’empilement plus élaboré vaut réellement la peine.
Quelle est la performance de l’approche hybride
Sur les trois langues, le mBERT multilingue se distingue comme le modèle unique le plus performant, particulièrement sur les nouvelles données haoussa et le corpus Bahasa Indonesia sur les discours haineux. Pourtant, l’ensemble hybride va encore plus loin. Une combinaison particulière — appelée EM-9, qui fusionne BERT, DistilBERT et mBERT dans le cadre Hyb-Stack — délivre systématiquement les meilleurs résultats. Elle atteint des scores F1 plus élevés, une mesure courante de précision, que n’importe quel modèle individuel ou approche de moyenne simple, les gains les plus importants apparaissant dans les jeux de données à faibles ressources haoussa et Bahasa Indonesia. Des analyses détaillées des erreurs montrent que les fautes restantes surviennent généralement entre des émotions étroitement liées, comme joie contre surprise ou tristesse contre peur, reflétant la flou naturel des sentiments humains plutôt que des défaillances nettes du système.
Ce que cela signifie pour les systèmes du monde réel
Pour le lecteur général, la principale leçon est que combiner plusieurs modèles d’IA de manière intelligente peut aider les ordinateurs à mieux lire les émotions dans les textes, en particulier dans des langues longtemps négligées par la technologie. En créant un corpus haoussa d’émotions de haute qualité et en montrant que les ensembles hybrides surpassent les modèles uniques et les schémas de vote simples, les auteurs démontrent une voie pratique vers des outils plus inclusifs et sensibles aux émotions. Les travaux futurs étendront l’approche à des nuances émotionnelles plus subtiles, au langage codé-mixte, aux emojis et à d’autres langues sous-représentées, avec l’objectif de créer des systèmes capables de percevoir non seulement si les gens sont heureux ou tristes, mais comment et pourquoi ils ressentent ce qu’ils ressentent — quelle que soit la langue qu’ils parlent.
Citation: Adamu, H., Azmi Murad, M.A. & Nasharuddin, N.A. A hybrid stacked ensemble learning framework for multilabel text emotion detection. Sci Rep 16, 7714 (2026). https://doi.org/10.1038/s41598-026-38172-9
Mots-clés: détection d'émotions, TAL multilingue, apprentissage ensembliste, modèles transformer, langues à faibles ressources