Clear Sky Science · fr
Calcul efficace et conception d’une architecture de multiplicateur védique double précision à grande vitesse
Pourquoi des calculs plus rapides comptent
Chaque fois que vous diffusez une vidéo, utilisez la navigation sur votre téléphone ou laissez un système d’IA analyser des images médicales, du matériel informatique spécialisé effectue discrètement des milliards de petits calculs par seconde. Une grande partie de ces opérations sont des multiplications sur des nombres en virgule flottante, la manière standard pour les ordinateurs de représenter des valeurs réelles comme 3,14159. Cet article explore une façon plus intelligente de construire l’un de ces composants essentiels : un multiplicateur à haute vitesse et à faible consommation qui puise dans des idées de la mathématique védique ancienne pour améliorer le matériel numérique moderne.
Des astuces mathématiques anciennes aux puces modernes
L’arithmétique en virgule flottante sous-tend le traitement numérique du signal, le traitement d’image, les communications et les accélérateurs d’apprentissage profond. Les multiplicateurs standards doivent traiter des mots binaires larges — 64 bits pour la double précision — et le faire rapidement sans gaspiller de surface de puce ni d’énergie. Les approches traditionnelles, comme Booth, Karatsuba et les multiplicateurs en réseau, jonglent avec des compromis entre vitesse, taille matérielle et complexité de conception. La mathématique védique, un système de 16 règles arithmétiques classiques développé en Inde, comprend une méthode de multiplication appelée Urdhva Tiryakbhyam, ou « vertical et croisé ». Elle forme des produits partiels de manière fortement parallèle, ce qui peut réduire le nombre d’étapes intermédiaires et le matériel nécessaire. Des chercheurs ont récemment adapté ces idées aux circuits numériques, mais les conceptions existantes comportent encore des surcoûts lorsqu’elles sont utilisées pour des opérations en virgule flottante double précision.
Ce qui distingue ce nouveau multiplicateur
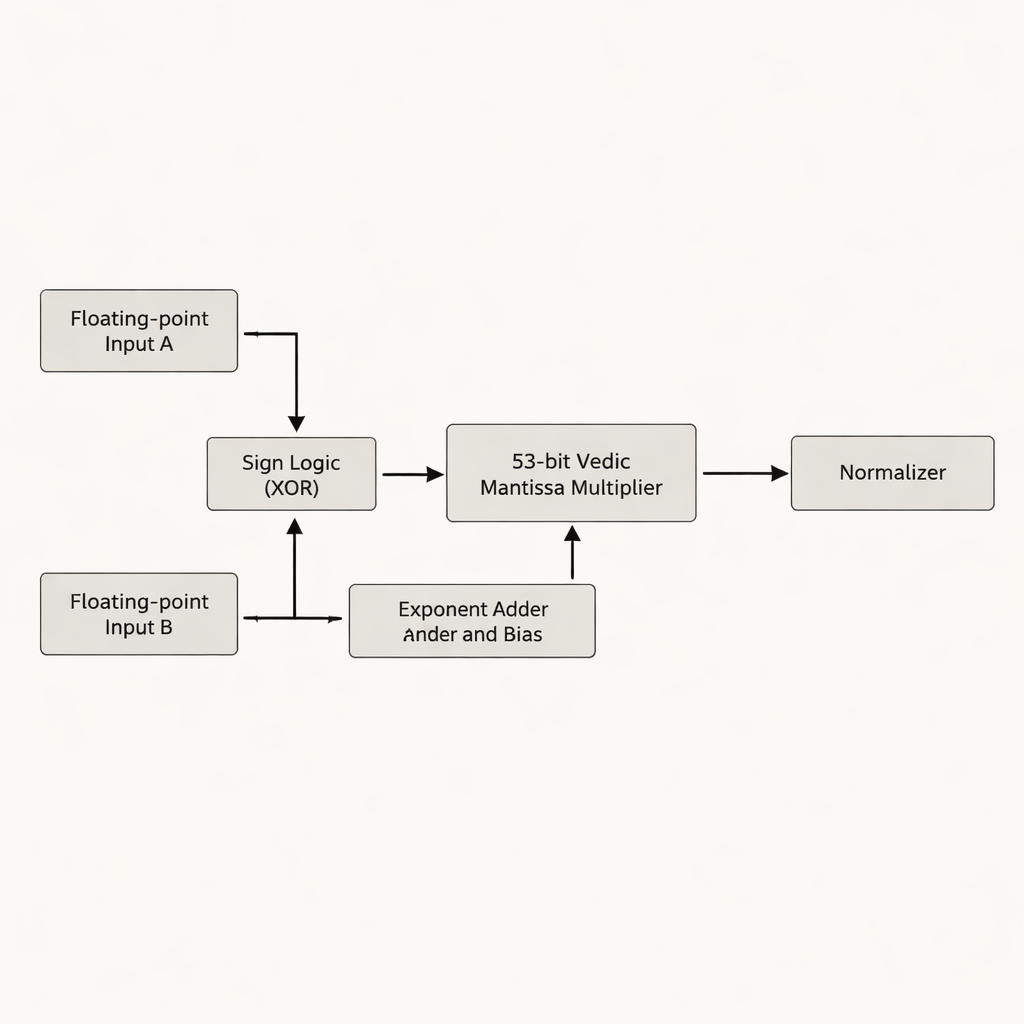
Les auteurs proposent un multiplicateur en virgule flottante double précision qui se concentre sur la mantisse — la partie du nombre en virgule flottante qui contient la plupart des chiffres significatifs. Plutôt que de compléter la mantisse de 52 bits à 54 bits, comme le font de nombreuses conceptions antérieures, ils travaillent avec la véritable mantisse effective de 53 bits, évitant des bits « vides » gaspillés qui consomment du stockage et du câblage supplémentaires sur une puce. Le cœur de la conception est un multiplicateur védique 53 bits basé sur Urdhva Tiryakbhyam, organisé en une hiérarchie de blocs constitutifs plus petits : des unités de 3 bits forment des unités de 6 bits, qui construisent des unités de 12 bits, 13 bits, 26 bits et 52 bits, toutes combinées dans l’étage final de 53 bits. L’architecture sépare le travail en trois phases principales — calcul du signe, addition et biaisage de l’exposant, et multiplication de la mantisse suivie de la normalisation — en respectant la norme IEEE-754 tout en réduisant les circuits redondants.
Blocs de taille première pour un matériel plus propre
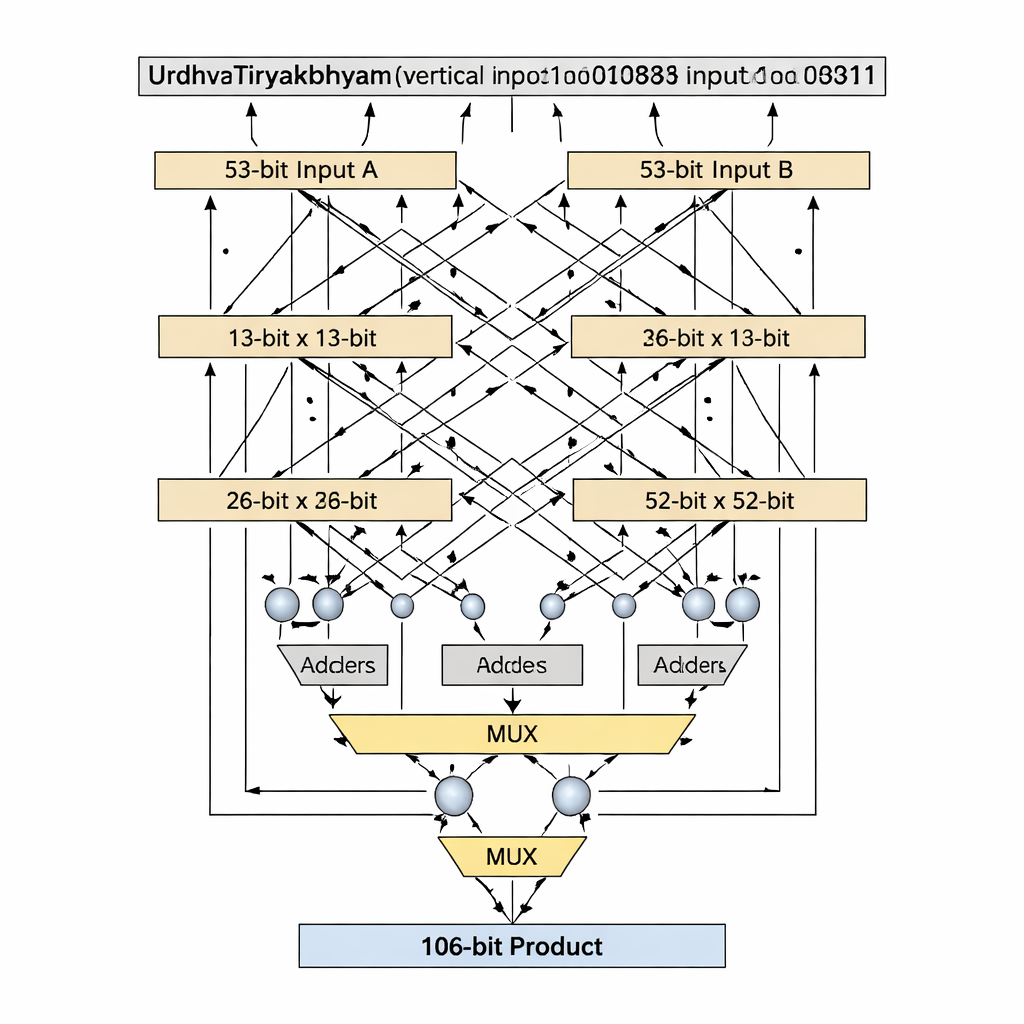
Une innovation clé réside dans la manière dont la conception gère des largeurs de bits qui sont des nombres premiers, comme 13 et 53, qui ne se divisent pas proprement en blocs de taille égale. Les décompositions védiques standard supposent des entrées divisées uniformément, mais cela devient gênant ou coûteux en cas de longueurs premières. Les auteurs introduisent un algorithme « prime-bit » qui réutilise astucieusement un multiplicateur védique plus petit (n−1 bits), accompagné d’additionneurs, de multiplexeurs et d’une seule porte logique supplémentaire, pour émuler un multiplicateur n bits sans remplissage. Pour l’étage de 13 bits, les entrées sont divisées en sections de 1 bit et 12 bits ; des produits partiels sont créés à l’aide d’un multiplicateur védique 12 bits, d’une sélection conditionnelle (via des multiplexeurs) basée sur les bits de poids fort, et d’un petit nombre d’additionneurs. Le même schéma s’étend à 53 bits avec un cœur de 52 bits. Cette décomposition sur mesure raccourcit le chemin critique — la plus longue chaîne logique que doit traverser un signal — tout en maintenant un faible nombre d’éléments logiques.
Gains mesurés en vitesse, taille et consommation
La conception a été décrite en langage de description matérielle Verilog et implémentée sur un FPGA Xilinx Zynq en utilisant les outils Vivado. Sur des multiplicateurs védiques de 13, 26, 52, 53 et 64 bits, l’unité proposée de 53 bits montre un équilibre favorable entre retard, utilisation logique (tables de correspondance et broches E/S) et puissance estimée. Comparée à des multiplicateurs double précision antérieurs basés sur Booth, Karatsuba et d’autres arrangements védiques, la nouvelle architecture réduit significativement le retard dans le pire des cas et la quantité de ressources FPGA nécessaires, sans ajouter de complexité au circuit flottant environnant. Parce que la multiplication de la mantisse est plus rapide et que la profondeur logique est réduite, l’activité de commutation diminue, ce qui indique un meilleur produit puissance–retard même si les comparaisons directes de puissance entre technologies restent difficiles à établir.
Impacts sur l’IA et le traitement du signal
Pour tester la conception dans une charge de travail réelle, les auteurs ont intégré leur multiplicateur védique double précision dans le moteur de convolution d’un réseau de neurones convolutionnel, où les opérations de multiplication et d’accumulation dominent le temps d’exécution. Le remplacement des multiplicateurs IEEE-754 conventionnels et des multiplicateurs védiques antérieurs par la nouvelle conception a réduit le délai de convolution, diminué la consommation d’énergie et abaissé le temps d’inférence, tout en maintenant la même précision de classification. Des avantages similaires sont attendus pour d’autres tâches intensives en calcul, telles que le filtrage numérique, la détection de contours et les chaînes de traitement d’images médicales, où des multiplicateurs plus rapides augmentent directement le débit et peuvent permettre aux appareils de fonctionner plus frais ou sur des batteries plus petites.
Ce que cela signifie pour la technologie de tous les jours
En termes simples, l’article montre que reprendre une idée astucieuse de multiplication issue des mathématiques védiques et l’adapter soigneusement aux formats binaires modernes peut produire un multiplicateur plus petit, plus rapide et plus économe en énergie que les conceptions standard. Ce bloc amélioré peut s’intégrer dans des processeurs, des puces de traitement du signal et des accélérateurs IA, conduisant à des analyses de données plus rapides, des appareils plus réactifs et potentiellement une consommation énergétique réduite dans des systèmes allant des smartphones aux scanners médicaux. Les auteurs décrivent aussi des pistes futures, notamment la logique réversible pour une consommation encore plus faible et l’intégration dans des unités de traitement plus vastes, suggérant que ce mariage entre arithmétique ancienne et matériel moderne ne fait que commencer.
Citation: Kumar, A.S., Sahitya, G., Kusuma, R. et al. Efficient computation and design of high speed double precision Vedic multiplier architecture. Sci Rep 16, 7364 (2026). https://doi.org/10.1038/s41598-026-38147-w
Mots-clés: Multiplicateur védique, arithmétique en virgule flottante, conception FPGA, traitement numérique du signal, réseaux neuronaux convolutionnels