Clear Sky Science · fr
Application des réseaux neuronaux profonds inspirés des essaims et des modèles d’ensemble pour la reconstruction des données de conductivité spécifique
Pourquoi combler les lacunes de données est important
Les eaux côtières sont la ligne de front où l’activité humaine rencontre l’océan. Les scientifiques surveillent la salinité de ces eaux à l’aide d’une mesure appelée conductivité spécifique, qui aide à détecter des fuites de pollution, des variations d’apports d’eau douce et des évolutions environnementales à long terme. Mais les capteurs tombent en panne, les tempêtes coupent l’électricité et les appareils ont des limites. Le résultat est des lacunes frustrantes dans des séries chronologiques essentielles — précisément au moment où les gestionnaires et les chercheurs ont le plus besoin de données continues. Cette étude pose une question pratique : l’intelligence artificielle moderne peut‑elle « réparer » de manière fiable ces enregistrements cassés pour que les décisions côtières se fondent sur des informations complètes et fiables ?
Observer la respiration du Golfe
Les chercheurs se sont concentrés sur le golfe du Mexique, l’un des plus grands écosystèmes marins au monde et une région soumise à de fortes pressions industrielles et agricoles. Ils ont utilisé des mesures provenant de cinq stations de l’US Geological Survey situées près de la rivière Pascagoula et de Mullet Lake, chacune enregistrant la salinité de l’eau (via la conductivité spécifique), la température et le niveau d’eau toutes les 15 minutes. Une station, appelée E, présentait environ 5 % de données de conductivité spécifique manquantes — exactement le type de problème qui confronte les réseaux de surveillance en situation réelle. Les données des quatre stations voisines formaient une sorte de filet de sécurité environnemental : lorsque la station E était aveugle, les autres continuaient d’observer. L’idée centrale consistait à apprendre aux modèles informatiques comment les cinq stations « respirent » ensemble afin que les lacunes d’un site puissent être déduites à partir des séries complètes des autres.
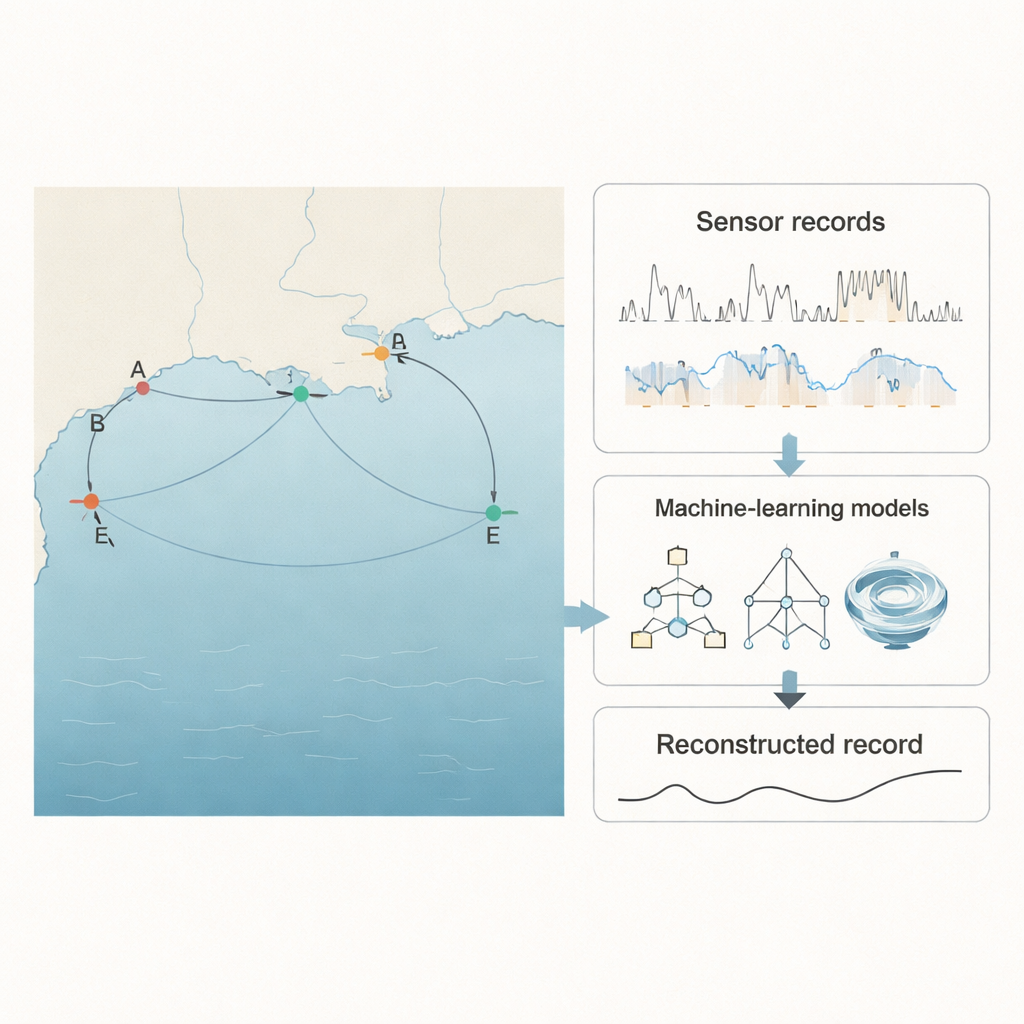
Mettre les algorithmes intelligents à l’épreuve
Pour cela, l’équipe a assemblé une série de dix approches de modélisation différentes. D’un côté se trouvaient des outils familiers comme la régression linéaire multiple, qui tentent d’établir des relations en ligne droite entre entrées et sorties. Au milieu se trouvaient des modèles plus souples comme les réseaux neuronaux classiques, les systèmes à logique floue et un réseau à mémoire longue et courte (LSTM) souvent utilisé pour les séries temporelles. Ils ont également utilisé une méthode auto‑organisatrice appelée group method of data handling (GMDH) et une variante non linéaire (NGMDH) capable de construire elle‑même des formules à plusieurs couches. Enfin, ils ont intégré des méthodes basées sur des arbres : un modèle d’arbre de décision unique (CART) et deux approches « d’ensemble » — Random Forest et XGBoost — qui combinent de nombreux arbres pour produire une décision finale, un peu comme un panel d’experts votant pour une réponse.
Apprentissage profond propulsé par essaim
Former des réseaux neuronaux profonds est notoirement délicat : leurs nombreux réglages peuvent facilement rester bloqués dans de mauvaises configurations. Pour les améliorer, les auteurs ont associé LSTM et NGMDH à une méthode d’optimisation récente inspirée de l’eau tourbillonnante, appelée turbulent flow of water‑based optimization (TFWO). Dans ce schéma, chaque ensemble possible de paramètres du modèle est imaginé comme une « particule » se déplaçant selon un motif en tourbillon à travers l’espace des solutions. Au fil de nombreux cycles, les particules sont poussées vers des régions qui donnent des erreurs de prédiction plus faibles. Cette recherche de style essaim a rendu les deux types de réseaux neuronaux sensiblement plus précis que leurs versions standard, réduisant leurs erreurs moyennes d’environ 6–11 %. Pourtant, même ces modèles profonds améliorés ont finalement été dépassés par les approches basées sur les arbres.
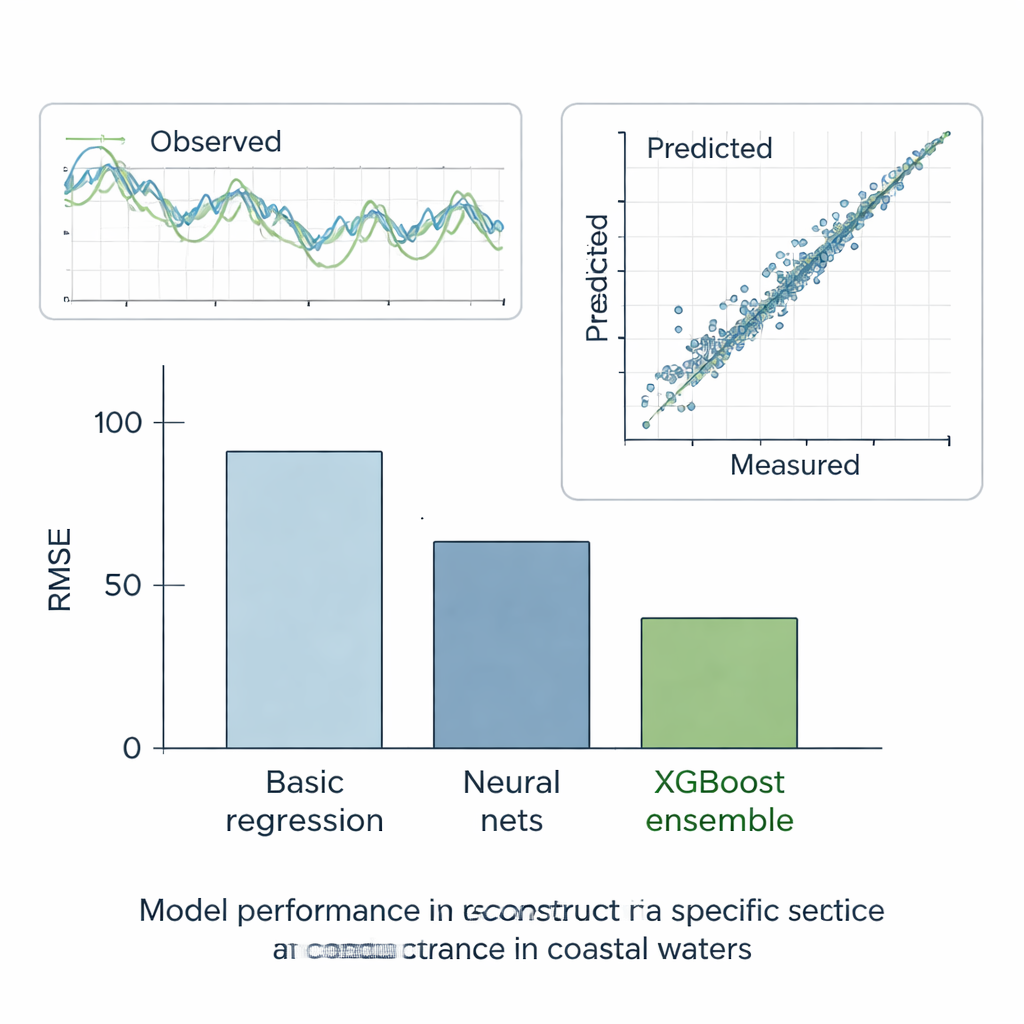
Les ensembles prennent l’avantage
Les auteurs ont testé rigoureusement toutes les méthodes dans six scénarios. Dans cinq cas « et si », ils ont masqué des portions de séries autrement complètes et vérifié la capacité de chaque modèle à reconstruire les valeurs manquantes. Dans le dernier cas, en situation réelle, ils ont demandé aux modèles de combler les lacunes réelles de la station E en utilisant les données de ses voisines. Au travers de ces tests, la méthode la plus simple en ligne droite a obtenu les pires résultats, tandis que les modèles d’apprentissage automatique standard ont fait beaucoup mieux, réduisant l’erreur d’environ moitié. Les arbres de décision, qui segmentent automatiquement les données en groupes plus homogènes, ont encore amélioré les résultats. Mais le gagnant clair a été l’ensemble XGBoost : en construisant des centaines d’arbres qui corrigent chacun les erreurs des précédents, il a atteint des erreurs extrêmement faibles et une correspondance quasi parfaite entre conductivité spécifique prédite et mesurée. Ses reconstructions suivaient étroitement les séries observées et restituèrent le comportement statistique global des enregistrements de qualité de l’eau.
Ce que cela signifie pour les côtes et au‑delà
Pour les non‑spécialistes, le message est simple : une IA soigneusement conçue peut remplir de manière fiable les morceaux manquants des séries de qualité de l’eau côtière, surtout lorsqu’il existe des stations voisines fournissant du contexte. Bien que les réseaux neuronaux avancés soient puissants, cette étude montre que les méthodes d’ensemble basées sur les arbres comme XGBoost sont encore plus précises et, en pratique, peuvent constituer le meilleur choix pour réparer des jeux de données environnementaux. Avec des outils robustes de comblement de lacunes, les scientifiques peuvent mieux suivre des variations subtiles de la salinité côtière, identifier des épisodes de pollution et soutenir les décisions de gestion sans être entravés par les pannes inévitables des capteurs. Les mêmes stratégies peuvent être adaptées à de nombreux autres problèmes d’ingénierie et environnementaux où les flux de données sont riches, bruyants et parfois incomplets.
Citation: Mahdavi-Meymand, A., Sulisz, W. & Nandan Bora, S. Application of swarm-based deep neural networks and ensemble models for reconstruction of specific conductance data. Sci Rep 16, 7292 (2026). https://doi.org/10.1038/s41598-026-38136-z
Mots-clés: qualité de l'eau côtière, conductivité spécifique, apprentissage automatique, reconstruction des données manquantes, XGBoost