Clear Sky Science · fr
Un nouveau modèle d’ensemble par empilement pour prédire le coefficient de débit des vannes radiales multiples submergées
Pourquoi des vannes d’eau plus intelligentes comptent
Dans les terres irriguées, des vannes métalliques dans les canaux décident discrètement qui reçoit de l’eau et quand. Lorsqu’elles sont même légèrement mal réglées, certaines parcelles sont sur‑arrosées tandis que d’autres manquent d’eau, gaspillant une ressource rare et affectant les récoltes. Cette étude s’attaque à ce problème caché en utilisant des techniques avancées d’apprentissage par ordinateur pour rendre l’écoulement à travers ces vannes plus facile et beaucoup plus précis à prévoir, sans exiger d’équations complexes ni d’essais‑erreurs sur le terrain.
Un défi caché à l’intérieur des vannes de canal
Les réseaux d’irrigation modernes s’appuient largement sur les vannes dites radiales, des portes en acier courbées que l’on peut relever ou abaisser pour réguler la quantité d’eau qui passe en aval. Dans de nombreuses conditions réelles, ces vannes fonctionnent en position « submergée » — c’est‑à‑dire que les niveaux d’eau sont élevés à la fois en amont et en aval. Dans cette situation, une grandeur clé appelée coefficient de débit détermine la quantité d’eau qui passe effectivement sous une vanne partiellement ouverte. Les méthodes traditionnelles pour calculer ce coefficient sont compliquées, reposent sur de nombreuses hypothèses et peuvent s’écarter de la réalité de plusieurs dizaines de pourcents lorsque la vanne est submergée. Pour les ingénieurs et les gestionnaires de l’eau, ces imprécisions se traduisent directement par un mauvais contrôle des livraisons aux exploitations agricoles.
Apprendre à un modèle à partir de données fluviales réelles
Les chercheurs se sont tournés vers l’apprentissage automatique, ce qui permet aux ordinateurs d’apprendre des motifs directement à partir des mesures au lieu de se fier uniquement à des formules conçues à la main. Ils ont rassemblé 782 points de données provenant de trois grands régulateurs du delta du Nil en Égypte, chacun équipé de plusieurs vannes courbes desservant plusieurs centaines de milliers d’hectares. Pour chaque condition de fonctionnement, ils ont enregistré les niveaux d’eau en amont et en aval, l’ouverture et la géométrie des vannes, ainsi que le débit mesuré. Ils ont ensuite converti ces mesures en ratios simples — par exemple, quelle est la profondeur en aval par rapport à l’amont — afin que le modèle se concentre sur les aspects les plus influents du comportement des vannes. Des travaux antérieurs avaient montré que le ratio profondeur aval/amont est particulièrement important, et cette nouvelle analyse a confirmé qu’il s’agit du prédicteur le plus puissant du coefficient de débit.
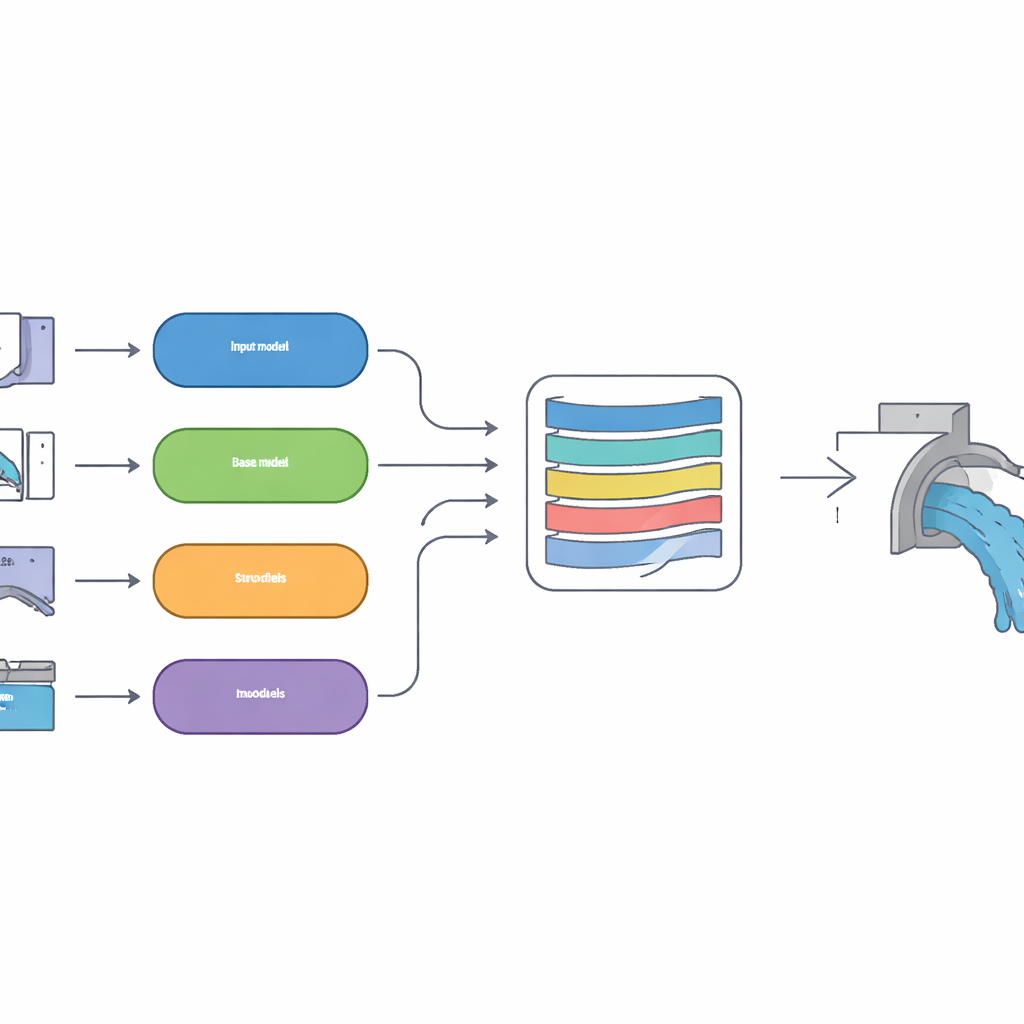
Plusieurs esprits, une réponse finale
Plutôt que de parier sur une seule méthode d’apprentissage, l’équipe a construit une approche par « empilement » qui combine plusieurs outils de prédiction différents. Quatre modèles de base, chacun utilisant un style différent de reconnaissance de motifs, produisent d’abord leurs propres estimations du coefficient de débit. Ceux‑ci comprennent des méthodes capables d’exprimer l’incertitude, des méthodes adaptées aux courbes complexes et des méthodes excellant à détecter des relations subtiles. Leurs sorties sont ensuite alimentées dans un modèle de niveau supérieur, un réseau profond de type long short‑term memory (LSTM) doté d’un mécanisme d’attention. Cette couche supérieure apprend combien de confiance accorder à chaque modèle de base selon les différentes conditions d’écoulement, à la manière d’un ingénieur expérimenté qui pondère plusieurs avis d’experts avant de décider d’une valeur finale.
Quelle est la performance réelle ?
Le système combiné a été entraîné et testé à l’aide d’une validation croisée rigoureuse, où les données sont répétitivement séparées en groupes d’apprentissage et de contrôle pour éviter le sur‑apprentissage. Au fil de ces tests, le modèle d’ensemble a constamment produit des coefficients de débit très proches des mesures de terrain. Son erreur typique n’était que de quelques pourcents, et il a surpassé chacun des modèles de base individuels ainsi que plusieurs techniques de régression traditionnelles largement utilisées. Les comparaisons visuelles ont montré que les prédictions du modèle suivaient presque exactement la ligne idéale un à un avec les valeurs observées, indiquant qu’il restait précis sur l’ensemble des conditions de fonctionnement rencontrées dans les canaux.
Ce que cela signifie pour les canaux réels
Pour les non‑spécialistes, la conclusion pratique est simple : en laissant plusieurs méthodes d’apprentissage « voter » puis en apprenant à un juge final intelligent comment pondérer ces votes, les ingénieurs peuvent prédire de façon fiable la quantité d’eau qui passera par des vannes radiales submergées. Comme les entrées nécessaires ne sont que les niveaux d’eau, les ouvertures des vannes et les dimensions fixes des vannes — des valeurs déjà mesurées dans la plupart des systèmes de canaux automatisés — la méthode peut être intégrée aux logiciels de contrôle existants comme outil d’aide à la décision. Utilisé judicieusement dans la gamme de conditions sur lesquelles il a été entraîné, ce type de modèle d’ensemble intelligent peut aider les agences d’irrigation à distribuer l’eau de manière plus équitable, réduire le gaspillage et répondre plus sereinement aux variations de la demande et aux pressions climatiques sur les rivières.
Citation: Abdelazim, N.M., Hosny, M., Abdelhaleem, F.S. et al. A novel stacking ensemble model for predicting discharge coefficient of submerged multi parallel radial gates. Sci Rep 16, 7953 (2026). https://doi.org/10.1038/s41598-026-38117-2
Mots-clés: canaux d’irrigation, vannes radiales, apprentissage automatique, gestion de l’eau, prévision des débits