Clear Sky Science · fr
UncerTrans : transformeur temporel sensible à l’incertitude pour la prédiction précoce d’actions
Pourquoi voir les actions tôt peut nous protéger
Imaginez un robot domestique capable de dire, dès le premier mouvement du poignet, si quelqu’un s’apprête à verser de l’eau chaude dans une tasse en toute sécurité ou à renverser accidentellement la bouilloire. Dans les usines, les hôpitaux et les maisons connectées, les machines partagent de plus en plus l’espace avec les personnes, et réagir seulement après le début d’un accident est trop tard. Cet article présente UncerTrans, un nouveau système d’IA qui non seulement prédit ce qu’une personne est susceptible de faire à partir du tout début d’une action, mais indique aussi son degré de certitude — une capacité essentielle quand la sécurité humaine est en jeu.
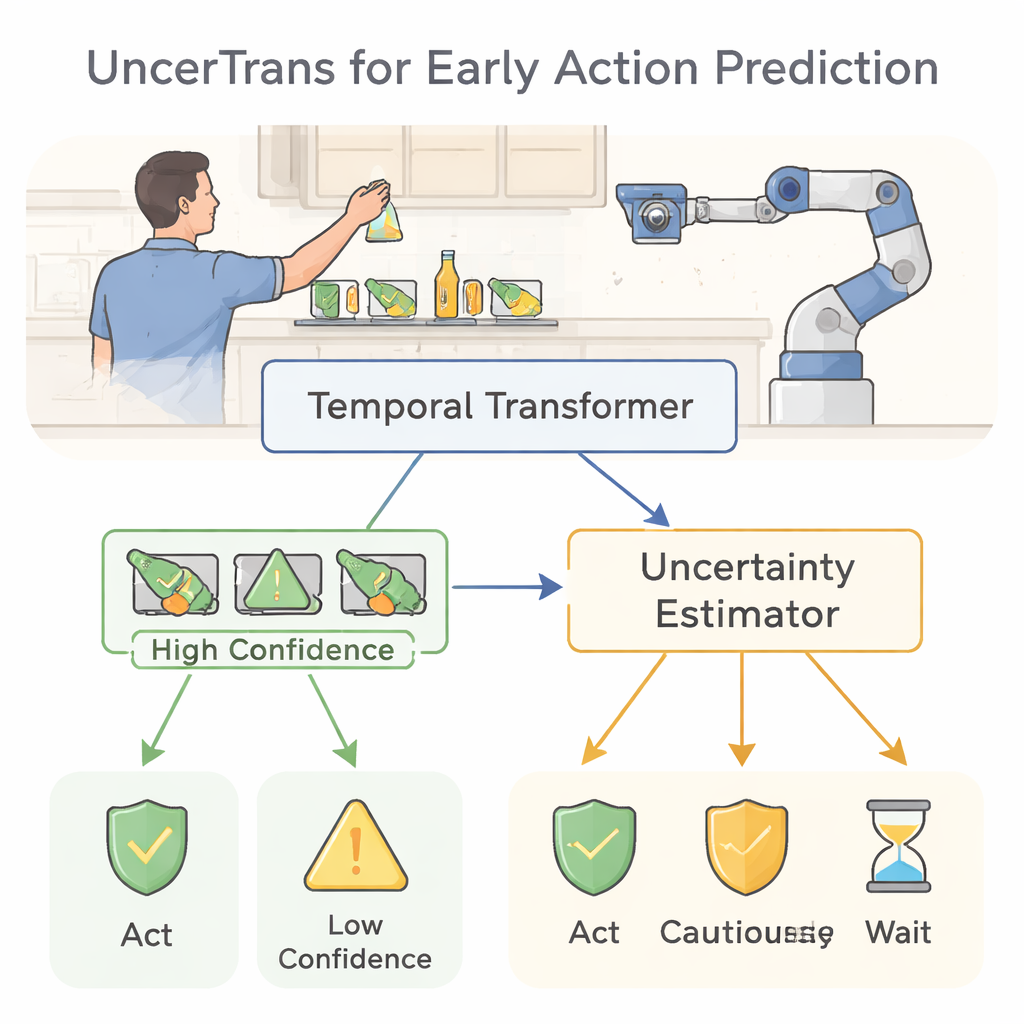
Du visionnage à la prévision des actions humaines
La plupart des systèmes actuels de vision par ordinateur reconnaissent ce que quelqu’un fait seulement une fois l’action presque terminée : ils classent un clip vidéo complet en « couper des légumes » ou « saisir une tasse ». C’est utile pour l’analyse a posteriori, mais pas pour prévenir les brûlures, les collisions ou les chutes. La prédiction précoce d’action relève d’un défi plus difficile : décider quelle action complète va se produire après n’avoir vu que 10–20 % de celle-ci. Le problème est que de nombreuses actions se ressemblent au début — tendre la main vers une bouilloire peut signifier verser une boisson ou la heurter — si bien qu’un système doit fonctionner avec peu d’informations tout en évitant des erreurs dangereuses.
Apprendre à la machine à se concentrer sur les bons instants
UncerTrans répond à cela en utilisant un transformeur temporel, une architecture de réseau neuronal moderne développée à l’origine pour le langage. Plutôt que de lire des mots dans une phrase, il examine de courts extraits vidéo au fil du temps. Le modèle découpe une séquence d’action précoce en quelques segments et utilise un mécanisme d’attention pour décider quels instants comptent le plus. Les images récentes reçoivent un poids supplémentaire, ce qui reflète notre intuition que le mouvement le plus récent révèle généralement l’intention la plus claire. Cette conception permet au système de capter à la fois des détails fins, comme le mouvement des doigts, et des motifs plus larges, comme la trajectoire d’un bras, même lorsqu’il n’observe qu’une fraction de l’action complète.
Amener une machine à admettre quand elle doute
Une innovation clé d’UncerTrans est qu’il ne s’arrête pas à une unique réponse catégorique. Il fait passer la même entrée dans le réseau plusieurs fois de façon légèrement différente en utilisant une technique appelée Monte Carlo dropout. À chaque passage, différentes connexions internes sont désactivées aléatoirement, produisant une prédiction légèrement différente. En examinant à quel point ces prédictions divergent, le système peut estimer sa propre incertitude : des prédictions fortement regroupées indiquent une grande confiance, tandis que des prédictions dispersées signalent le doute. UncerTrans sépare en outre l’incertitude due à une expérience d’apprentissage limitée du bruit présent dans la vidéo elle‑même, et ajuste le nombre d’exécutions de test à la volée — en en faisant plus lorsque les premiers échantillons paraissent ambigus et moins lorsqu’ils s’accordent déjà.
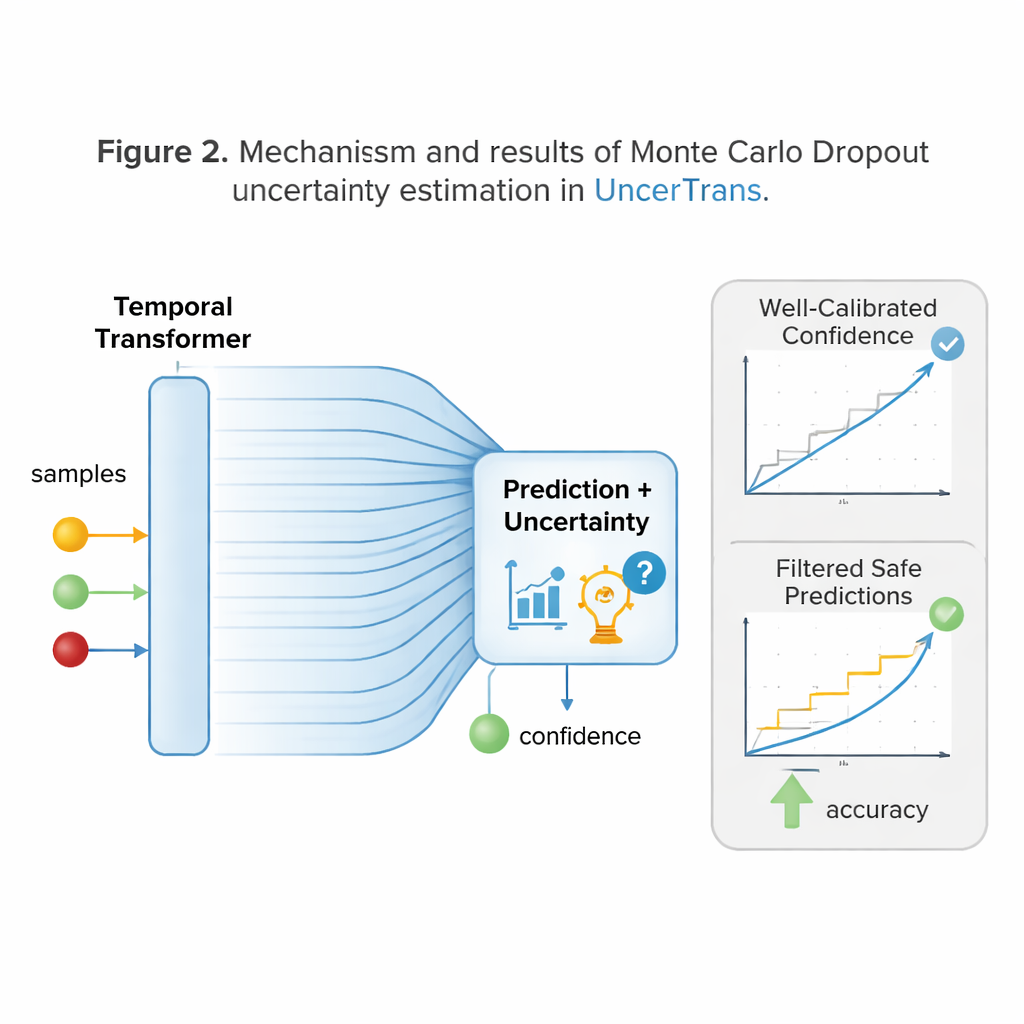
Transformer la confiance en décisions plus sûres
Savoir quand on peut se tromper n’est utile que si cela influe sur le comportement. UncerTrans convertit ses estimations de confiance en choix pratiques. Pour les prédictions présentant une faible incertitude, le système peut agir de manière décisive — par exemple déclencher une alerte ou éloigner le bras d’un robot d’un danger. Lorsque l’incertitude est modérée, il peut opter pour des comportements plus prudents, comme ralentir un robot ou demander plus d’informations. Si l’incertitude est très élevée, il peut refuser de trancher et se contenter de continuer à observer. Des tests sur un large jeu de données vidéo « en première personne » en cuisine montrent qu’UncerTrans prédit les actions à venir plus précisément que plusieurs méthodes concurrentes, en particulier lorsque seuls les 10 % initiaux d’une action sont visibles. De manière notable, en écartant seulement les 30 % des cas les plus incertains, la précision des prédictions restantes monte à environ 84 %, ce qui illustre la réelle valeur du filtrage conscient de l’incertitude.
Ce que cela signifie pour le travail quotidien humain–robot
Pour un non-spécialiste, le message est simple : UncerTrans est une avancée vers des machines qui non seulement devinent notre prochain geste à partir d’indices limités, mais savent aussi quand ces suppositions sont fiables. En combinant un modèle de vision sensible au temps avec un « indicateur de confiance » interne, le système peut réagir plus vite et plus sûrement dans des environnements encombrés du monde réel tels que cuisines, usines et établissements de soins. Bien que la méthode implique encore des coûts computationnels et nécessite des améliorations, elle offre une feuille de route prometteuse pour des robots et des systèmes de surveillance futurs qui anticipent précocement les dangers, répondent prudemment en cas d’incertitude et, ultimement, s’intègrent de façon plus sûre aux espaces humains.
Citation: Zhai, X., Liu, Y. UncerTrans: uncertainty-aware temporal transformer for early action prediction. Sci Rep 16, 7068 (2026). https://doi.org/10.1038/s41598-026-38107-4
Mots-clés: prédiction précoce d’action, collaboration humain-robot, incertitude en IA, modèles vision par transformeur, systèmes intelligents sûrs