Clear Sky Science · fr
La construction et les techniques raffinées d'extraction de graphes de connaissances basées sur des grands modèles de langue
Cartographies plus intelligentes pour des décisions complexes
Les décisions modernes dans des domaines à fort enjeu — comme les opérations à grande échelle, la gestion des infrastructures ou la réponse aux catastrophes — dépendent de la capacité à interpréter rapidement des volumes considérables d'informations dispersées. Manuels, flux de capteurs, rapports et simulations racontent chacun une partie de l'histoire, mais ils sont rarement organisés de manière exploitable par des humains ou des machines. Cet article présente une méthode pour transformer cette information fragmentée en « cartes de connaissance » vivantes, alimentées par des grands modèles de langue, afin que planificateurs et analystes puissent poser de meilleures questions et obtenir des réponses plus rapides et plus fiables.
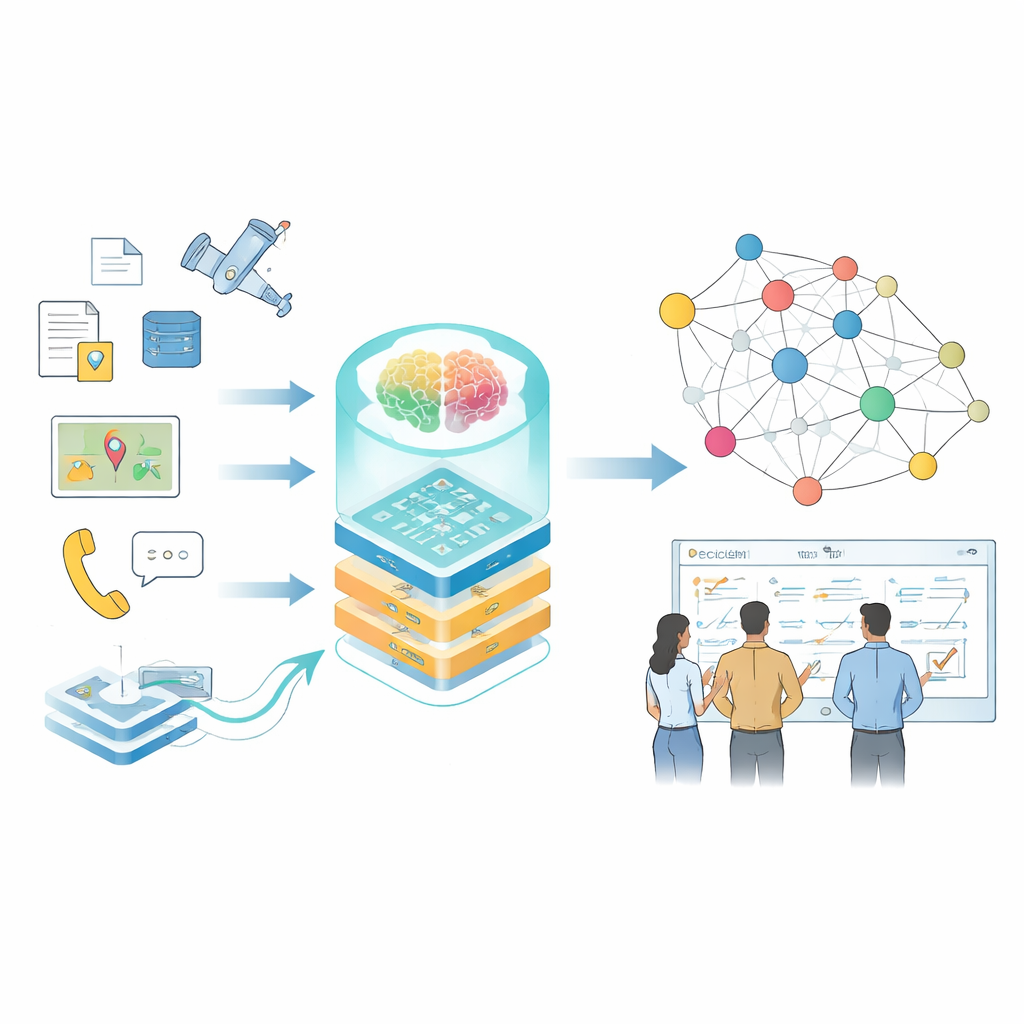
Des faits dispersés à la connaissance connectée
Les auteurs se concentrent sur les graphes de connaissances, une manière de représenter l'information sous la forme d'un réseau de faits liés — qui a fait quoi, avec quel système, dans quelles conditions. Dans des contextes courants, ces graphes alimentent déjà les moteurs de recherche et les systèmes de recommandation, mais les domaines spécialisés posent des problèmes plus difficiles : les données sont sensibles, la terminologie est dense, les formats vont de rapports en texte libre à des journaux de capteurs, et les conditions évoluent rapidement. Les outils traditionnels reposant sur des règles écrites à la main ou des petits modèles peinent à suivre, et les modèles de langue généralistes interprètent souvent mal les termes techniques ou manquent des relations subtiles importantes pour les décisions réelles.
Apprendre une nouvelle spécialité aux grands modèles de langue
Pour répondre à cela, l'étude affine un modèle de langue de base puissant sur un jeu de données spécifique au domaine soigneusement conçu. Le jeu de données s'appuie sur des communications de commandement, des manuels d'équipement, des scénarios simulés et la littérature d'experts. Avant que ces matériaux n'atteignent le modèle, ils sont fortement désensibilisés : des coordonnées concrètes deviennent des emplacements relatifs, des noms d'unités se transforment en codes génériques, et la logique sensible est partiellement masquée tout en préservant les motifs globaux. Les données sont stockées dans un format structuré décrivant la situation générale, les tâches spécifiques (comme la planification, le classement des menaces ou la réponse à des questions) et les liens entre elles. Cette structure permet au modèle d'apprendre non seulement des faits isolés, mais aussi la façon dont différentes tâches partagent un contexte.
Couches d'adaptation pour différentes tâches
Plutôt que de réentraîner chaque paramètre du modèle de langue — un processus coûteux et risqué — les auteurs utilisent une technique appelée adaptation de faible rang, organisée en plusieurs couches qui se concentrent chacune sur un aspect différent du problème. Une couche capture la terminologie et les concepts de base, une autre intègre les règles et contraintes opérationnelles, et une troisième se spécialise dans l'adaptation à des tâches particulières, comme la planification ou l'évaluation des menaces. Un composant de contrôle séparé, le réseau de « routage », examine chaque élément d'entrée et décide quelle combinaison de ces adaptateurs légers le modèle doit utiliser. Cette conception permet au système de basculer efficacement entre les tâches tout en préservant à la fois la capacité linguistique générale et l'expertise spécifique au domaine.
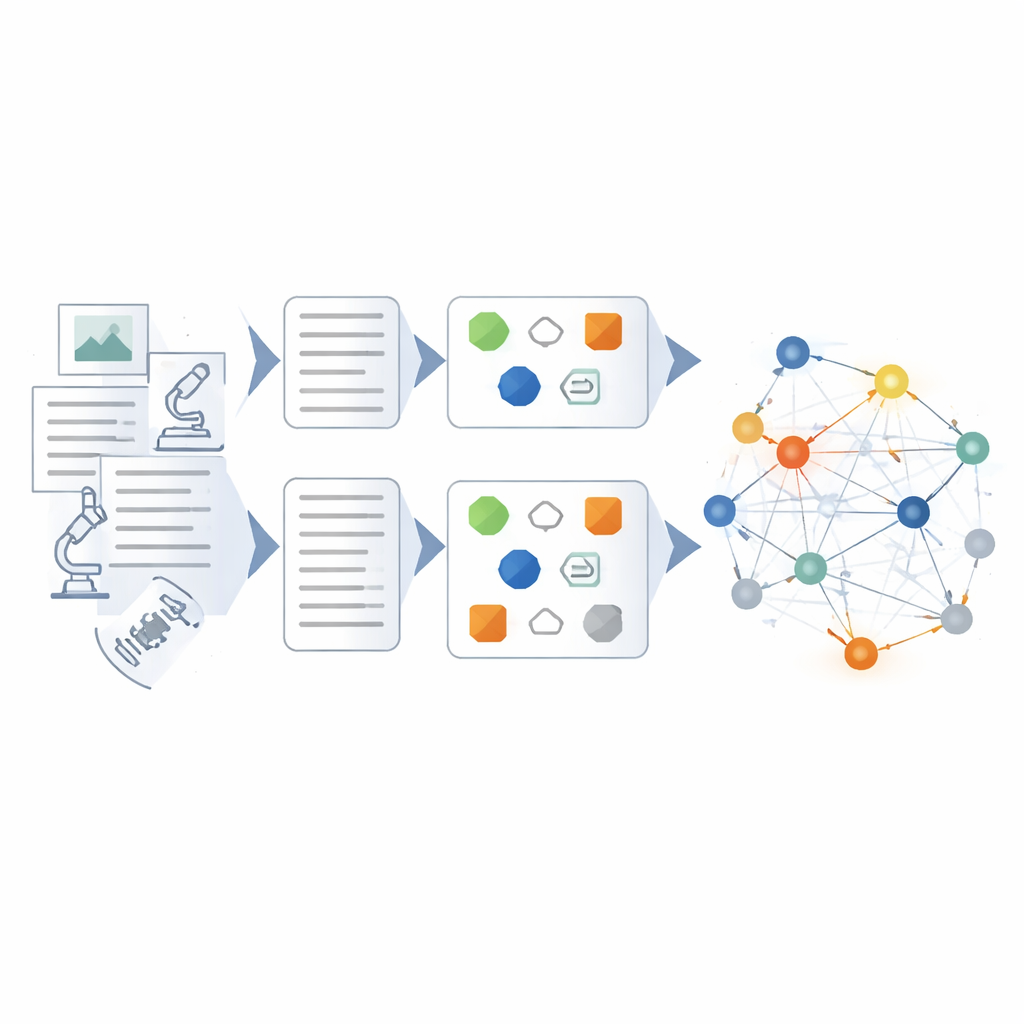
Construire et vérifier la toile de connaissances
Au‑dessus du modèle affiné, les auteurs conçoivent un pipeline hybride pour construire le graphe de connaissances lui‑même. D'abord, les données brutes sont nettoyées et standardisées afin que les termes et formats soient cohérents. Ensuite, des méthodes basées sur des règles et des modèles élaborés par des experts extraient les entités et événements évidents. Le modèle de langue affiné intervient pour les tâches plus complexes : résumer des rapports désordonnés en synthèses concises, identifier les acteurs clés et les équipements, et inférer des relations telles que des chaînes de cause à effet ou la coordination entre unités. Chaque fait extrait reçoit une note selon plusieurs angles — à quel point il correspond à des schémas connus, la force de sa connexion avec d'autres faits, et s'il s'aligne sur des raisonnements en plusieurs étapes à travers le graphe. Seuls les résultats à haute confiance sont ajoutés, et ceux à faible confiance sont signalés pour révision.
Gains prouvés en précision et fiabilité
L'équipe évalue son approche sur trois tâches principales qui reflètent des besoins du monde réel : répondre à des questions complexes sur les règles et l'équipement, proposer des plans d'action pour des situations données, et classer différents scénarios de menace selon leur gravité. Sur ces tâches, le modèle adapté surpasse systématiquement des systèmes généralistes bien connus, y compris des modèles de pointe entraînés de manière plus générique. Il répond plus correctement aux questions, produit des plans plus réalistes et classe les menaces avec plus de précision. Le graphe de connaissances résultant est à la fois volumineux et fortement connecté, plus de 90 % des faits stockés passant des contrôles de confiance stricts et aidant les planificateurs à prendre des décisions solides plus rapidement.
Pourquoi cela compte pour l'avenir
Pour un lecteur non spécialiste, le message clé est que les modèles de langue peuvent être transformés de beaux parleurs en analystes attentifs et spécialisés — à condition d'être entraînés sur les bonnes données, contraints par des règles claires et constamment vérifiés pour la qualité. Ce travail montre comment y parvenir dans un domaine sensible et en rapide évolution tout en protégeant les informations privées. Le cadre n'organise pas seulement des connaissances dispersées en une toile exploitable, il maintient aussi cette toile à jour et digne de confiance, offrant une feuille de route pour les futurs systèmes d'aide à la décision dans tout domaine où il est crucial de prendre des décisions complexes correctement.
Citation: Peng, L., Yang, P., Juexiang, Y. et al. The construction and refined extraction techniques of knowledge graph based on large language models. Sci Rep 16, 8104 (2026). https://doi.org/10.1038/s41598-026-38066-w
Mots-clés: graphe de connaissances, grand modèle de langue, soutien à la décision, adaptation de domaine, désensibilisation des données