Clear Sky Science · fr
Générer des échantillons de test aux limites pour les testeurs d’aléa via l’optimisation intelligente et les algorithmes évolutionnaires
Pourquoi l’« presque‑aléatoire » compte pour la sécurité quotidienne
Chaque fois que vous faites des achats en ligne, déverrouillez votre téléphone ou envoyez un message privé, des dés mathématiques invisibles sont lancés pour protéger vos données. Ces dés prennent la forme de longues suites de bits censés être aléatoires, utilisés comme clés cryptographiques. Si ces bits sont même légèrement moins aléatoires qu’ils ne le devraient, des attaquants déterminés peuvent parfois en déceler des motifs exploitables. Cet article explore une nouvelle façon de fabriquer des séquences de test « presque‑aléatoires » — des données qui paraissent extrêmement aléatoires mais cachent de minuscules défauts — afin que les ingénieurs puissent mettre sérieusement à l’épreuve les dispositifs qui protègent nos vies numériques.
Quand les nombres aléatoires ne sont pas assez aléatoires
Les systèmes de sécurité modernes reposent sur deux types de générateurs de nombres aléatoires. Les générateurs réellement aléatoires s’appuient sur des phénomènes physiques imprévisibles, comme le bruit électronique ou les fluctuations quantiques, tandis que les générateurs pseudo‑aléatoires utilisent des algorithmes qui étendent de courtes graines aléatoires en de longues suites. En pratique, la qualité des deux dépend au fond de la source physique d’imprévisibilité, appelée source d’entropie. Malheureusement, les sources d’entropie du monde réel sont fragiles : variations de température, vieillissement du matériel ou erreurs de conception peuvent réduire silencieusement leur caractère aléatoire. Pour détecter de tels problèmes, des organismes de normalisation comme le NIST définissent des batteries de tests statistiques qui vérifient si les bits produits semblent suffisamment aléatoires. Les dispositifs intègrent de plus en plus des « testeurs d’aléa en temps réel » qui surveillent leur propre sortie pendant leur fonctionnement. Pourtant il n’existait pas de bonne méthode pour générer des cas d’échec réalistes et difficiles à détecter, afin de vérifier que ces contrôleurs embarqués fonctionnent réellement.
Concevoir des séquences qui échouent à peine aux tests d’aléa
Du point de vue d’un testeur, les échecs triviaux — comme des sorties composées uniquement de zéros — sont faciles à repérer. Le véritable défi est de détecter les cas limites : des suites presque indiscernables d’un aléa idéal mais qui ne passent qu’un ou plusieurs contrôles statistiques. Les auteurs se concentrent sur cinq tests classiques qui examinent différents aspects des motifs de bits, notamment la fréquence des zéros et des uns, le comportement des paires de bits, la distribution de certains motifs courts, la corrélation des bits avec des copies décalées d’eux‑mêmes et la distribution des longueurs de runs de bits identiques. Ils définissent une « zone frontière » pour chaque test : une bande étroite où les données ne violent que légèrement les seuils d’acceptation habituels. Produire une longue séquence qui tombe simultanément dans toutes ces bandes étroites est extrêmement improbable par hasard, car les tests interagissent de manière compliquée et non linéaire. C’est là que l’optimisation et l’IA interviennent.
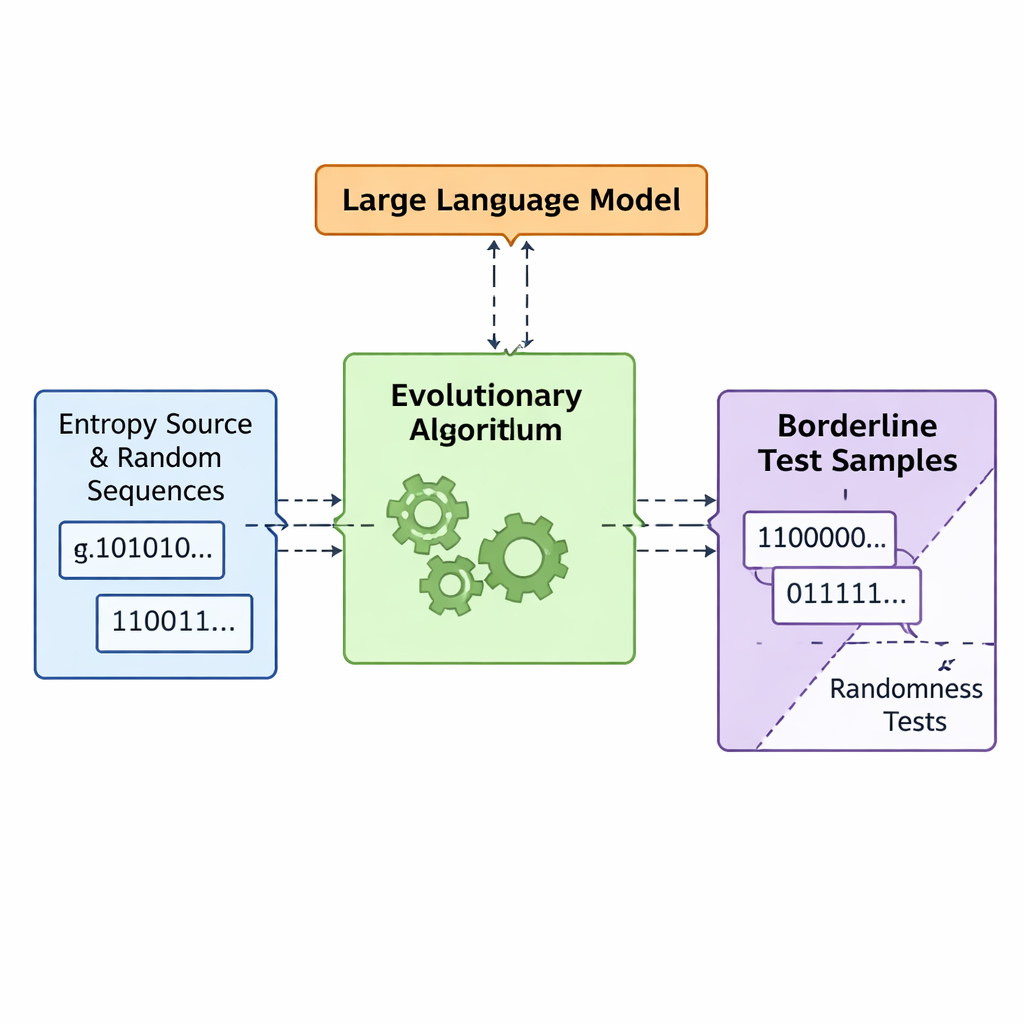
Laisser l’évolution et les modèles de langage co‑construire de la mauvaise randomness
L’équipe présente un cadre nommé APAM‑IGLLM qui traite la génération de séquences comme un problème d’optimisation en haute dimension. Chaque séquence candidate est une chaîne de bits, et sa « fitness » mesure à quel point elle se rapproche des zones frontières des cinq tests. Un algorithme génétique mute et recombine ces séquences à répétition, en conservant celles qui se rapprochent de la région cible. Par-dessus cela, un grand modèle de langage (LLM) joue le rôle d’un coach stratégique. À chaque génération il examine des statistiques résumées de la population et l’historique à court terme, puis suggère comment ajuster des boutons internes — poids et facteurs d’échelle qui déterminent l’influence de chaque test sur la fitness. Cela crée une boucle de rétroaction : l’algorithme génétique explore l’espace des séquences possibles, tandis que le LLM oriente la recherche pour que les cinq scores convergent vers la petite intersection où les séquences sont tout juste non‑aléatoires.
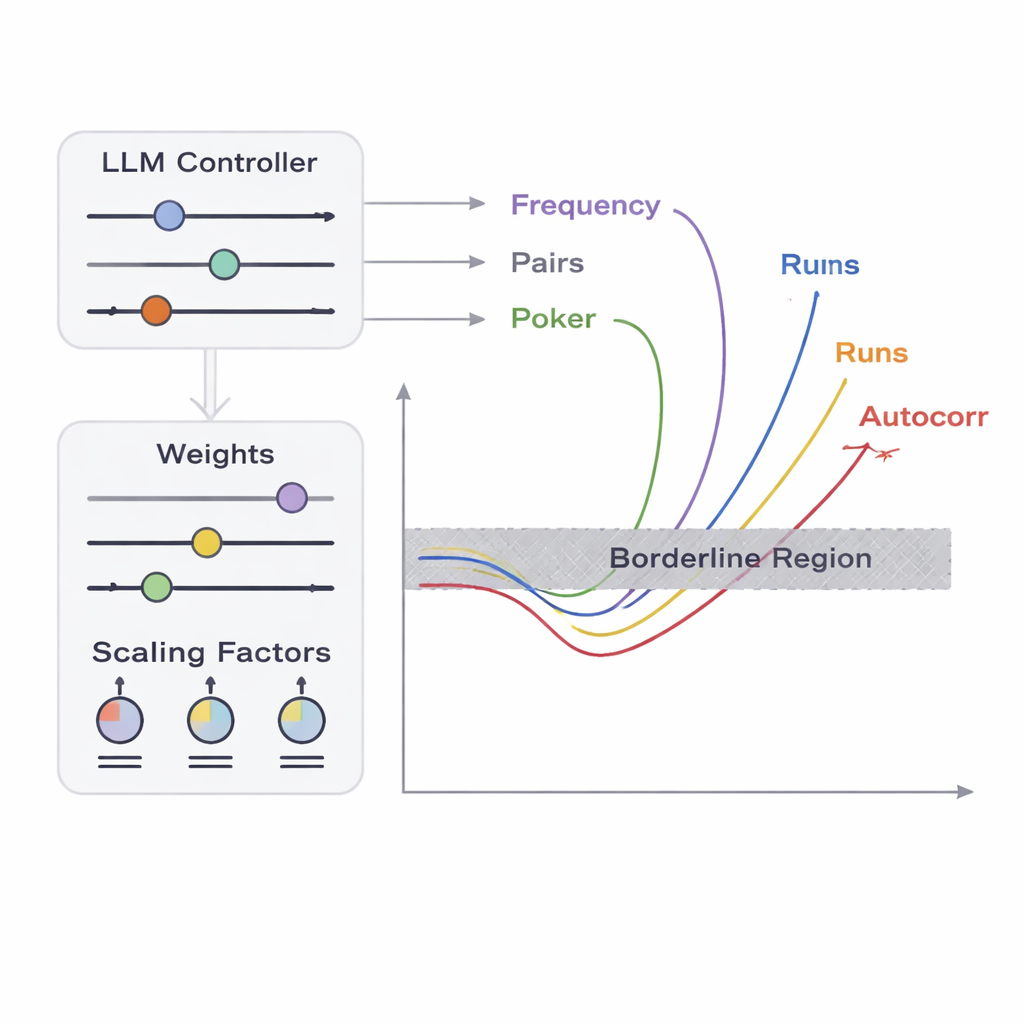
Jusqu’à quel point des données défaillantes peuvent‑elles paraître parfaites ?
Pour évaluer si leurs défauts artificiels paraissent réalistes, les auteurs comparent leurs séquences générées à des bancs d’essai largement utilisés. Ils calculent à la fois l’entropie de Shannon et la min‑entropie, mesures de l’imprévisibilité apparente de chaque octet, et trouvent des valeurs autour de 7,6–8 bits par octet — très proches du maximum théorique de 8 et similaires aux sources matérielles commerciales et au beacon public d’aléa du NIST. Ils exécutent également la batterie complète de tests statistiques NIST SP 800‑22 et observent que leurs séquences frontières réussissent et échouent selon un schéma presque identique à celui des données aléatoires de haute qualité réelles. Autrement dit, pour les outils standards, ces échantillons paraissent essentiellement normaux, même s’ils ont été délibérément conçus pour se situer près de plusieurs seuils d’échec. Cela en fait des entrées « adversariales » idéales pour vérifier la robustesse réelle des testeurs d’aléa embarqués.
Ce que cela implique pour la sécurité dans le monde réel
Pour un non‑spécialiste, ce travail propose une nouvelle façon de vérifier la sûreté des mécanismes de génération aléatoire qui sous‑tendent le chiffrement. Plutôt que de tester les dispositifs uniquement avec des aléas manifestement défaillants ou manifestement sains, les ingénieurs peuvent désormais les soumettre à une pluie de séquences soigneusement conçues et presque correctes qui imitent des défauts matériels subtils ou une dérive environnementale. Si un testeur d’aléa en temps réel manque ces cas limites, cela signale un angle mort potentiel qu’il faut corriger avant le déploiement du dispositif dans la banque, les communications sécurisées ou les systèmes blockchain. En utilisant une recherche évolutionnaire guidée par un modèle de langage, les auteurs fournissent un outil pratique pour générer de telles données de test exigeantes, contribuant à renforcer les fondations cachées de la sécurité numérique vers des niveaux de fiabilité supérieurs.
Citation: Gao, P., Zhang, B., Wang, Z. et al. Generating borderline test samples for randomness testers via intelligent optimization and evolutionary algorithms. Sci Rep 16, 7268 (2026). https://doi.org/10.1038/s41598-026-38020-w
Mots-clés: générateurs de nombres aléatoires, sources d’entropie, algorithmes évolutionnaires, grands modèles de langage, tests cryptographiques